
Le rendu neuronal à l’honneur : mais késako ?
Contrairement à la rastérisation ou au Ray Tracing, qui dénomment tous deux une méthode de rendu (c’est à dire un algorithme permettant d’obtenir la couleur des pixels d'une image en 2D correspondant à une certain angle de vue d’une scène 3D encodée numériquement), le rendu neuronal ne renvoie pas à une technologie précise, mais à une famille d’algorithmes (les réseaux de neurones) appliqués au cas du rendu 3D. Comprenez ici, du rendu au sens large, puisque NVIDIA propose dans les faits une collection d’outils basés sur le sacro-saint machine learning (pour plus de détails sur le fonctionnement de la chose, nous lui avons consacré un dossier entier ici) permettant de gagner en vitesse, en taille de données ou en qualité d’image selon le cas. Côté matériel, les Tensor Cores sont mis bien entendu à contribution, mais également les unités de calcul classiques, le tout sous la houlette du SER 2.0 pour organiser tout cela efficacement : une belle illustration de co-design matériel-logiciel — reste à voir ce qu’il en sera en pratique au niveau de son intégration, partielle ou totale dans les AAA vidéoludiques à venir. Voyons voir ce que cela donne !
Shader Execution Reordering 2 (SER)
Pour effectuer le sacro-saint rendu neuronal, NVIDIA a bûché sur son Shader Execution Reordering, ou SER pour faire court, qui passe en version 2 dans cette génération. Cette technologie n’est rien d’autre que l’équivalent GPU du fonctionnement out-of-order des CPU : au lieu de chercher à exécuter les instructions les unes après les autres sur les multiples threads du GPU sans se poser de question (modèle de programmation SIMT utilisé chez les verts), l’ordonnanceur peut prendre des libertés pour faire passer en priorité certains shaders en fonction des unités de calcul disponibles (Tensor Cores, RT Cores et async compute). Notez par ailleurs que NVIDIA n’est pas le seul à travailler sur ce type de technologie, Intel tente également le coup via l’implémentation de ses Thread Sorting Unit au sein de ses Xe-Core, le pendant bleu des SM.
En revanche, NVIDIA n’est pas très loquace sur les changements à l’œuvre dans cette version 2 : il s’agirait d’un mix matériel/logiciel permettant d’améliorer l’efficacité du machin, qui passe par un nouveau cœur logique deux fois plus efficace (sur quelle métrique, mystère mystère) mais également plus performant - comprendre plus malin dans sa capacité à extraire plus de parallélisme des threads. Dans la pratique, SER est accessible aux développeurs au moyen d’une API permettant de demander au système la réorganisation des threads. SER dans sa première version était uniquement limité au Ray Tracing — shaders de type raygeneration —, ce qui signifie qu’il fallait parfois tordre l’API de manière à y rentrer des programmes tiers, et souffrait d’un surcoût lié à la réorganisation qui le rendait parfois contre-productif lorsque les threads/rayons étaient majoritairement cohérents, par exemple dans des cas de calcul de l’occlusion ambiante.
Avec la version 2, NVIDIA communique sur davantage de flexibilité autour de l’appel des shaders de Ray Tracing, on imagine donc que certaines conditions/interfaces ont étés revues de manière à englober plusieurs types de calcul. Pourquoi pas des threads de type IA pour utiliser conjointement les unités INT et FP sur des modèles à précision mixte ? Le caméléon ne dit rien à ce sujet précis, mais mentionne en revanche le Path Tracing intégré dans « certaines productions actuelles » comme bénéficiant grandement de la technologie (vous avez parlé de Cyberpunk ?), le tout sans avoir besoin de changement au niveau du code (comprendre, de patch !). De plus, l’intégration des Tensor Cores comme partie prenante des SM permet au SER d’en tirer également parti pour accélérer les shaders neuronaux, ce qui signifie que ce ré-ordonnanceur agit désormais sur intégralité des unités de calcul programmables de la puce : RT Cores, ALU INT, ALU FP, Tensor Core.
L’AI Management Processor
Alors que le SER permet des réordonnancements au sein de threads d’un même groupe de manière à améliorer leur vitesse d’exécution au niveau micro, NVIDIA s’est également occupé de l’optimisation au niveau macro - comprendre, l’ordonnancement des contextes GPU, analogues des processus CPU — qui peuvent désormais être décidé directement depuis la carte au moyen d’un microcontrôleur RISC-V embarqué nommé AI Management Processor, ou AMP. Auparavant, c’était au CPU de faire ce boulot, occasionnant une latence superflue : vu les monstres de puissances que sont les RTX 4090 et 5090, une telle décision est plus que compréhensible. L’idée du bousin ? D’une part, pouvoir décharger le processeur central de cette tâche, et d’autre part de pouvoir gérer directement des politiques d’ordonnancement sur mesure de manière à fournir une fluidité de rendu optimale.

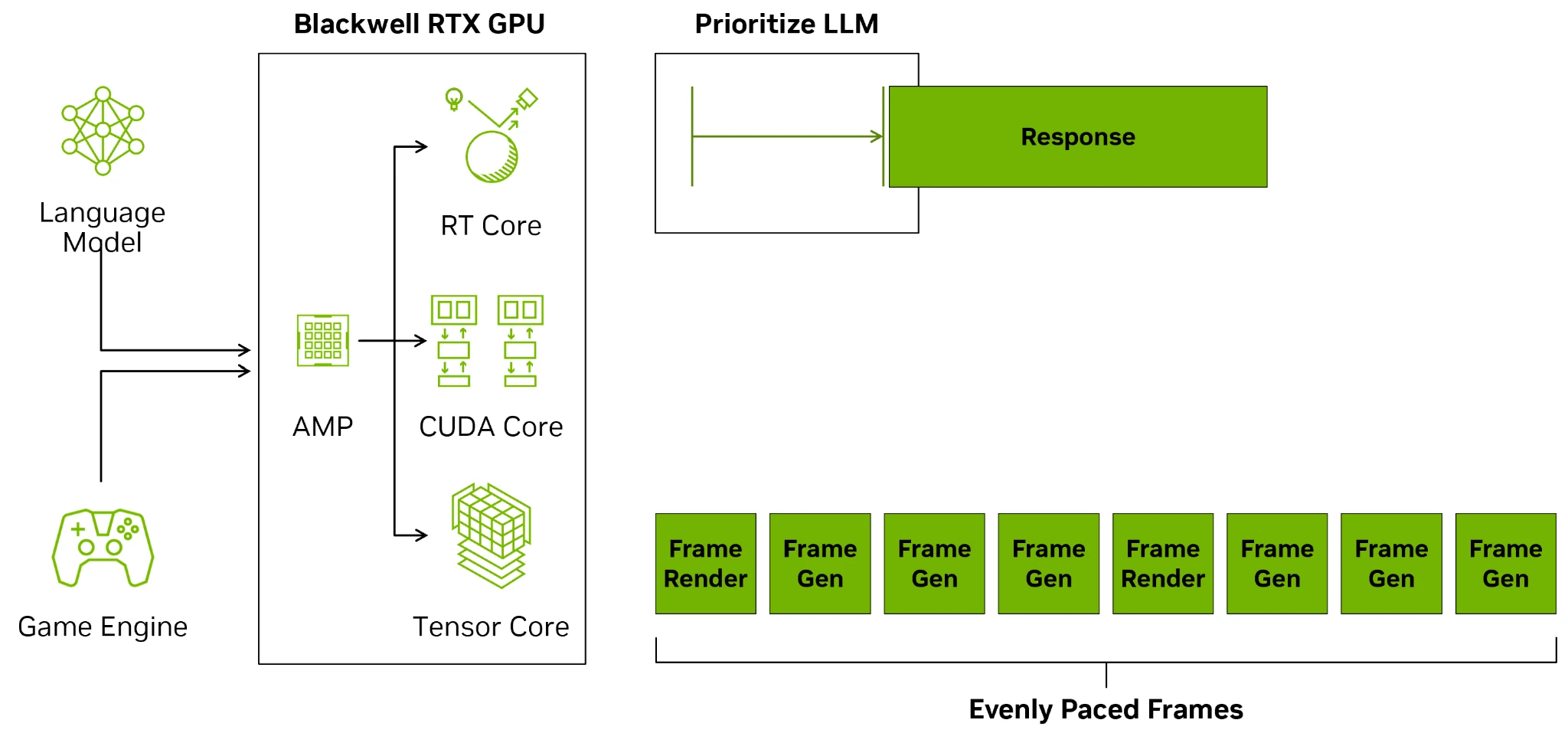
En français, cela signifie que le GPU est autonome dans la gestion de ces différentes tâches, par exemple lorsque le GPU est occupé à un rendu et une tâche de synthèse de texte dans le même jeu : de quoi rappeler certaines démos de la Gamescom ! Selon la puissance de votre carte, AMP sera ainsi chargé de s’assurer que le jeu ne laguouille pas trop lorsqu’un réseau de neurones est utilisé par une tâche intégrée au titre : pratique !
RTX Neural Materials et Neural Texture Compression
La première application de ces shaders neuronaux se situe dans RTX Neural Materials : une méthode permettant de stocker une représentation traitée par réseau de neurones nommé espace latent au lieu du matériau lui-elle (pour en savoir plus sur ce que cela représente, direction notre dossier IA !). Dans les faits, cela revient à troquer de l’espace mémoire pour de la complexité de calcul, mais pas de panique : les Tensor Cores sont là pour accélérer la chose.

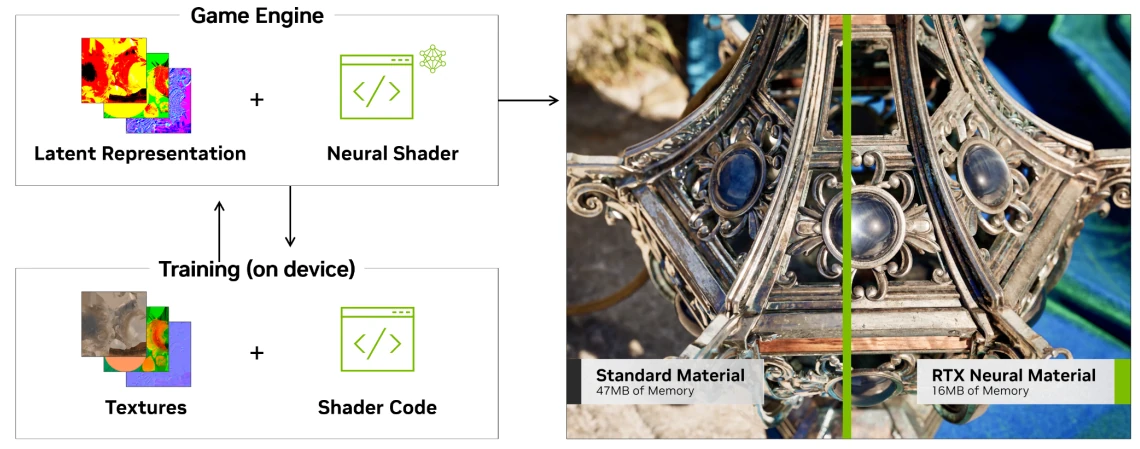
Dans le même style, la RTX Neural Compression, déjà entrevue dans un papier de recherche de la firme, utilise le même stratagème au niveau des textures, c’est-à-dire uniquement des images utilisées lors du rendu. NVIDIA communique sur une réduction de l’ordre d’un facteur 3 dans l’espace mémoire nécessaire pour leur démonstration, avec seulement 333 Mo une fois compressé au lieu de 1110 Mo pour les textures originales. Lors du rendu, les shaders traditionnels sont alors pourvu d’une partie IA utilisant les Tensor Cores, d’où le nom de shader neuronaux… et la nécessité du SER 2 pour dispatcher tout cela efficacement sur les unités disponibles.
Neural Radience Cache (NRC)
Une des difficultés du Ray Tracing réside dans les réflexions des rayons après avoir heurté une surface : il leur est alors possible de rentrer une nouvelle fois en collision avec une autre surface, puis une autre, et ainsi de suite. Ce phénomène rend le RTX Global Illumination particulièrement lourd au niveau des performances ; mais — pas de panique —, l’IA est là pour aider. Le Neural Radience Cache, un shader neuronal lié au rendu tracé par rayon, peut se charger de simuler ces nouvelles réflexions.


NRC prend en entrée des rayons simulés de manière non-IA, et donne ainsi en sortie une approximation calculée par réseau de neurones de l’éclairage final. De quoi sérieusement alléger les RTX Cores, qui se contentent de ne tracer qu’une seule réflexion ; à condition que l’entraînement et la précision du réseau soient suffisants pour tromper l’œil humain et offrir un niveau de réalisme acceptable — comprendre, ne pas produire (trop) d’artefacts. Une nouvelle fois, cela reste à vérifier en jeu !
RTX Neural Faces
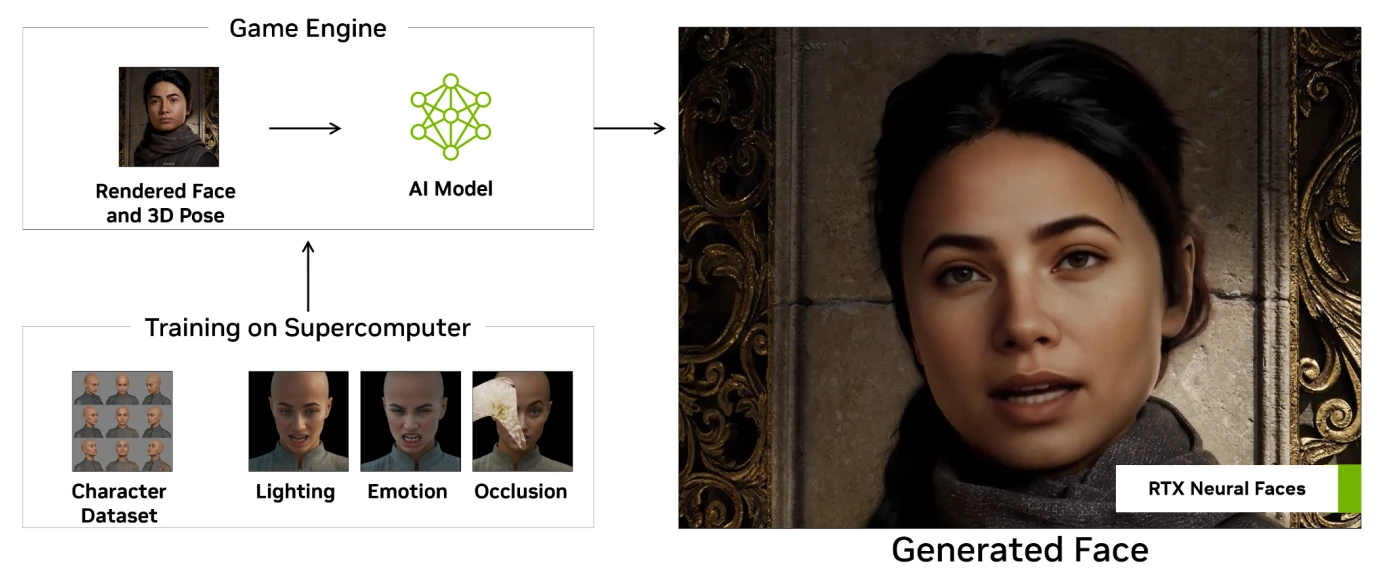
Au vu des progrès de l’IA générative, la chose était attendue au tournant : l’IA permettant d’inventer et de modifier des visages à partir d’une description, NVIDIA a intégré la chose dans son pipeline de rendu. À partir de l’image rendue par rastérisation et des informations de positionnement des sources de lumière et du visage, RTX Neural Face va peaufiner la chose pour la rendre plus naturelle et agréable à l’œil. Pour une fois, NVIDIA est très bavard sur la technologie à l’œuvre : un réseau entraîné sur des images prises par des photographes, mais également générées par IA, le tout envoyé dans TensorRT pour être utilisable en temps réel en jeu.

DLSS4
Dernier-né dans la série de l’anti-aliasing neuronal des verts, le DLSS profite de Blackwell pour passer en version 4. L’occasion de passer par un modèle de type transformer qui innove par un mécanisme d’autoattention (self-attention dans le jargon anglophone) permettant au réseau de se focaliser sur certains endroits jugés importants (par ici pour une explication partielle de son fonctionnement), de taille plus grande que les CNN précédentes. Notez que ces transformers sont la brique de base à l’œuvre dans les derniers réseaux à la mode tel Chat GPT : NVIDIA n’a pas fait cavalier seul ce coup-ci. Grâce à cela, les verts communiquent sur une implémentation de la génération d’image 40 % plus rapide et faisant usage de 30 % de VRAM en moins, ce qui permet aux réseaux du DLSS 4 de manger 2 fois plus de paramètres en entrée pour un rendu toujours plus fidèle.
Dans les faits, les réseaux à l’œuvre dans les trois composantes de base du DLSS ont été mis à jour pour tirer partie de cette nouvelle structure : Super Resolution (pour la mise à l’échelle de rendu effectué dans une définition inférieure —, Ray Reconstruction — débruitage et nettoyage du lancer de rayon — et DLAA — Anti-aliasing par IA. Dans chaque cas, le passage aux transformers permet de limiter le ghosting (effet de rémanence de l’image précédente), améliorer la restitution des détails ainsi que diminuer les artefacts temporels typiquement lors de la génération d’image.

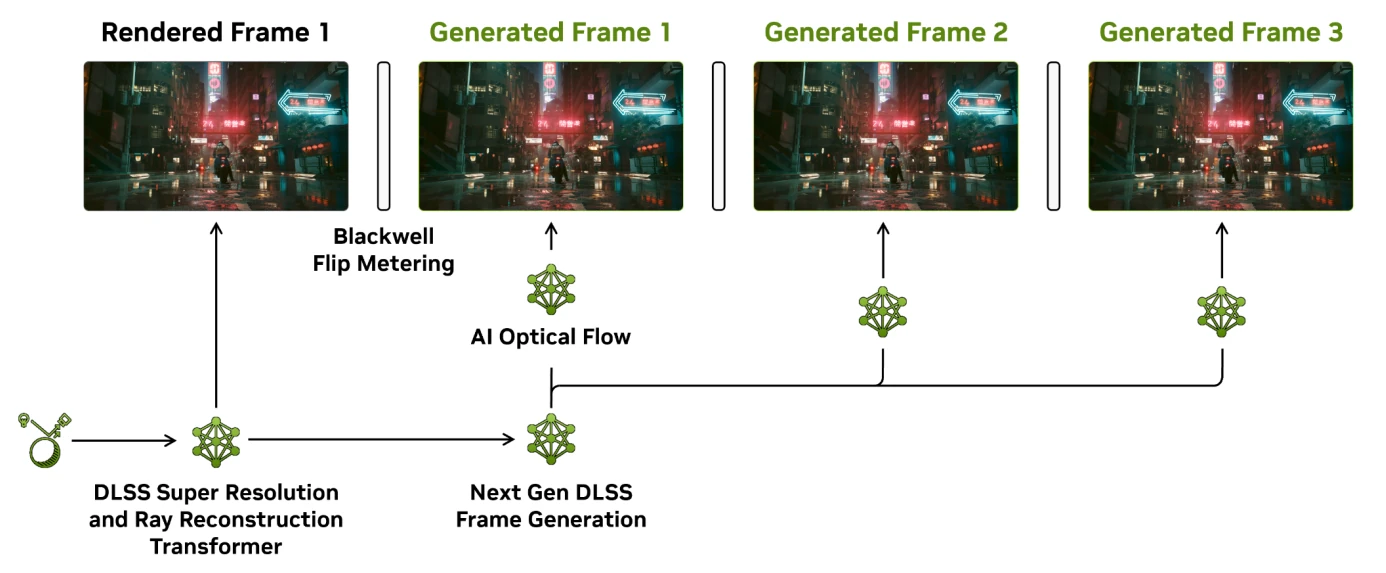
Le DLSS 4 génère à présent 3 images au maximum, et s’affaire à les distribuer de manière efficace dans le temps
Et, niveau génération d’images, nous voilà servis : le DLSS 4 introduit le MFG, ou Multi Frame Generation : la capacité d’intercaler non pas une (cas du DLSS 3 avec Frame Generation) mais un maximum de 3 images entre chaque frame, pour une accélération allant ainsi jusqu’à un facteur 4 au niveau des FPS. Si la structure de l’algorithme demeure inchangée (calcul du flux optique entre deux images via les OFX, puis utilisation d’un modèle neuronal prenant ce dernier en entrée ainsi que des informations du moteur de rendu), la puissance accrue de Blackwell et le changement de type de réseau suffisent à calculer plusieurs images ; une fonctionnalité qui sera donc exclusive à cette génération. En revanche, NVIDIA a également travaillé sur la manière de distribuer ces frames en dotant le moteur vidéo de la capacité à espacer les images dans le temps, limitant les microlatences.
C’en est tout pour la partie théorique des nouvelles capacités de Blackwell : rendez-vous à la page suivante pour les constater en pratique !




C'est parti pour un peu de lecture, merci d'avance pour votre test !!
🙏
Merci pour le test les copains ! 💯
🙏
Merci beaucoup pour le test, très complet!
Alors certes elle a de la patate et est à l'aise en upscale + FG, mais voilà la conso (et la température des puces mémoire, aouch)!
🙏
Merci Hardware & Co pour cet article de qualité (et les petites touches de cultures).
Bonne journée.
Quelques points à signaler vu l'ampleur du dossier et le temps imparti pour le réaliser :
Merci pour votre compréhension
Cool le test merci
rajouter une passe en UHD RT mais sans DLSS? Parce que le DLSS ca fonctionne mais on le sait depuis les premières RTX!
30 heures de boulot mini, désolé je peux pas. Il fallait que je case quelque part l'apport du DLSS 4. Sur 4 def/réglages, il y en a 3 sans DLSS/FSR et c'est en UHD RT qu'il fait plus sens.
Ouai je comprend , après je n'ai clairement pas la même vision sur le dlss!
Avec le DLSS 4 il y a match ! C'est justement tout l'intérêt de cette nouvelle version utilisant Transformer
Toute mes excuses j'avais sauté la page dlss 4, il y a l'info que je souhaitais, mea culpa!
Il n'y a pas de mal, c'est vrai que j'ai ajouté les tests en UHD RT natif dans la page DLSS 4, mais ça se limite à la seule 5090 et les 4 jeux testés, tant mieux si tu as trouvé ton bonheur.
Pour un test partiellement "rushé" 🙃 c'est juste incroyable le travail réalisé 🤩
Merci 🤸♂️