
Les tendances du (presque) moment
Après ce (rapide) coup d’œil en arrière, cap sur les années 2020 et l’état de l’art des IA actuellement en utilisation. Entre les secrets industriels et la complexité de certaines méthodes, s’y retrouver n’est pas une chose aisée, ce pour quoi nous avons opté pour trois réseaux emblématiques de ces dernières années se basant chacun sur des technologies différentes : GauGAN, StableDiffusion et ChatGPT. Chacun méritant son analyse dédiée, notre objectif ici est de souligner leurs spécificités sans pour autant rentrer (trop) dans les détails : ne soyez donc pas étonnés de voir certains éléments passés sous silence, et n’hésitez pas à multiplier les sources si le sujet vous passionne. C’est parti !
Plus que jamais, cette section n’est pas exhaustive, tant les dernières avancées en matière d’IA ont permis un développement toujours plus effréné de la chose. Il est question ici de vous présenter certaines des méthodes récemment utilisées afin de vous donner un goût de l’étendue des possibles, mais ce contenu sera très probablement rapidement obsolète !
GAN comme dans GauGAN
Pour améliorer l’apprentissage, les réseaux de neurones génératifs adversariels (Generative Adversarial Networks, ou GANs) se basent sur un entraînement à deux réseaux. Le premier est un réseau génératif, c’est-à-dire qu’il produit la sortie désirée (typiquement un texte ou une image, à l’inverse des réseaux effectuant de la classification qui sortent une probabilité de détection), que l’on souhaite entraîner, et le second (nommé discriminateur) est un réseau beaucoup plus simple, usuellement constitué des quelques couches denses, dont le but est de deviner si le résultat a été créé par l’IA ou non. Lors de l’entraînement, les images du réseau et de vraies images sont soumises aléatoirement au discriminateur qui va, lui aussi, progresser, permettant ainsi d’améliorer la vraisemblance des créations en les forçant à ressembler aux images existantes.
GauGAN, développé en partenariat avec NVIDIA dans le but de promouvoir l’IA, est d’un d’entre eux, et permet de générer une image photoréaliste à partir d’un coloriage simple désignant la nature des zones concernées (eau, végétation, ciel, route, etc). En interne, nous ne sommes pas surpris de retrouver un mix de tout ce que nous avons vu précédemment : un assemblage de couche SPADE ResBLK qui rassemble une liaison résiduelle, deux convolutions et deux couches SPADE qui, sans trop sortir les maths, permettent de modifier les résultats partiels de manière conditionnelle (comprendre, en fonction du type de la zone concernée) pour améliorer la sortie. Au niveau du hardware, l’entraînement a été réalisé sur une station de travail DGX-1 équipée de 8 NVIDIA V100 (32 Gio de VRAM) : il faut bien faire tenir ce réseau mastoc en mémoire !
En dépit de son âge relativement récent, les GAN sont en (grand) déclin, si bien que cette architecture aurait également pu être abordée à la page précédente. Dans la pratique, les GANs sont désormais adjoints à d’autres modèles afin de rester compétitifs par rapport aux architectures concurrentes.

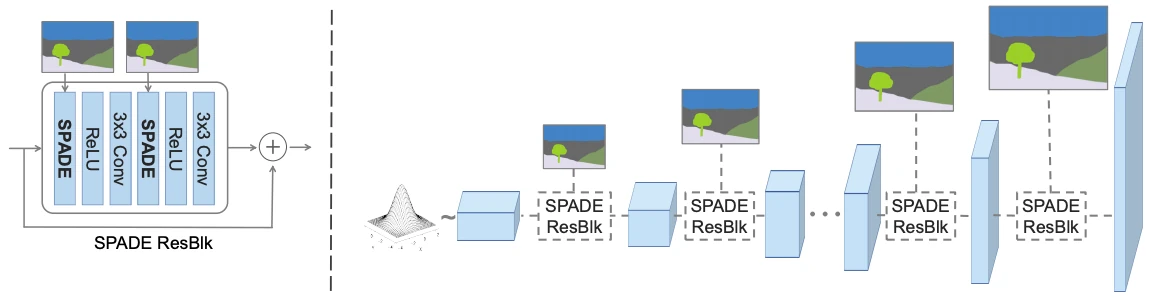
Le réseau générateur du GauGAN
Et quelques illustrations des sorties du bousin
StableDiffusion : en avant la génération d’images !
Si GauGAN avait marqué quelques esprits et fait causer de NVIDIA qui sponsorisait le projet, il ne représente pas la quintessence du réseau de neurones ; celle qui a participé à sa révélation auprès du grand public et a causé bon nombre de lois à son sujet. Par contre, ces qualificatifs peuvent totalement s’appliquer à StableDiffusion, un réseau de neurones permettant de générer des images sur la simple saisie d’un bref texte. Le réseau se base sur le concept de diffusion latente, et est composé de deux parties : un générateur chargé d’inventer des images à partir de ce fameux bruit, et une partie de traitement du texte chargée de guider le générateur vers la sortie souhaitée.
StableDiffusion n’est pas le seul projet s’étant attaqué à la génération d’images ! DALL-E, Midjourney et bien d’autres ont également abordé le problème sous des angles différents tout aussi passionnants… pour lequel un article dédié ne serait déjà pas suffisant pour expliquer toutes les subtilités.
Revenons à notre diffusion latente. Il s’agit un mécanisme cherchant à transformer des images en un bruit (noise), c’est-à-dire une distribution aléatoire des pixels. C’est ce concept qui donne le nom du réseau : similairement à deux colorants bleus et jaunes qui, dans un verre d’eau, vont se diffuser pour donner une coloration finale verte, la diffusion latente consiste entraîner un réseau de neurones conventionnel (U-Net, si vous souhaitez tout savoir) sur des images possédant initialement des différences marquées (un chat et un chien, par exemple), qui sont peu à peu corrompues en rajoutant une image aléatoire — notre bruit, quoi. In fine, ce réseau est alors capable de prédire à quel point l’image a été corrompue, i.e. sa différence avec une image normale.

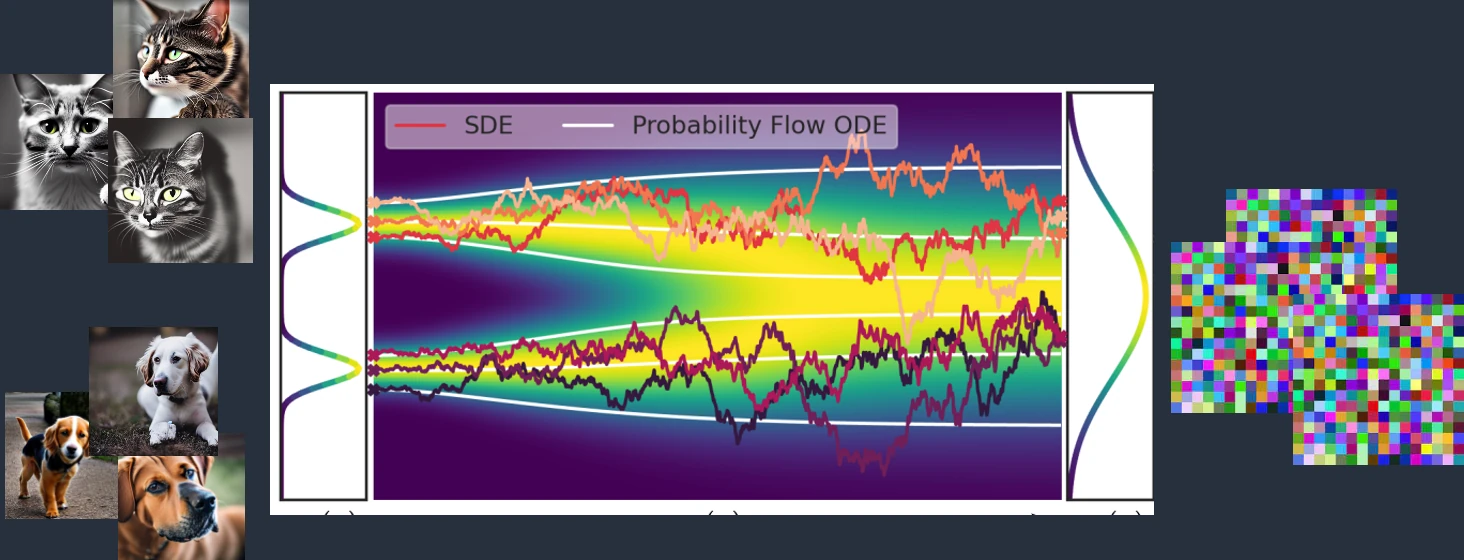
Exemple de diffusion latente, modifié à partir des explications de cet article de stable-diffusion-art, dont nous vous encourageons la lecture !
Tout cela est fort intéressant, mais à quoi bon ? Hé bien, en inversant le procédé, il est possible de créer des images : il suffit de partir d’une image aléatoire, puis retirer plusieurs fois de suite les bruits prédits par notre réseau : la sortie va naturellement converger vers une image statistiquement proche de celles vues à l’entraînement. Mieux encore, en rajoutant une seconde entrée (au hasard, un nombre décrivant le contenu de l’image), il devient possible de contrôler la sortie du réseau selon votre bon vouloir : parfait, il ne reste plus qu’à guider cette génération pour la faire correspondre à l’entrée textuelle humaine.
Notez que pour StableDiffusion, les images sont en fait compressées en utilisant (encore) un réseau de neurones nommé Variational AutoEncoder (VAE) dont le but est d’extraire un maximum d’information des images pour les faire tenir dans un espace minimal, ce qui permet d’améliorer la vitesse de prédiction. Ainsi, toutes les transformations sont en fait effectuées sur images compressées ayant totalement perdu le sens d’une image (il n’est pas question d’un. zip mais d’une soupe IA !), qui sont par la suite décompressées par le réseau pour obtenir la sortie finale.
Et comment qu’on guide un réseau ? Par un autre réseau ! Cette fois-ci en se basant sur l’héritage des réseaux d’analyse de texte, la description de l’image est mâchée pour être réduite en valeurs nommées tokens, qui sont ensuite transformées en valeurs vectorielles par une transformation nommée word embedding. En français, cela signifie que la phrase analysée est retranscrites en nombre par une transformation qui traduit en des nombres similaire des expressions de sens similaires ; par exemple, « chat bleu » et « petit félin couleur ciel » se retrouvent traduits en des valeurs proches l’une de l’autre, tant bien même qu’aucun mot n’est commun. C’est cette sortie qui est par la suite donnée au modèle de prédiction de bruit, et qui fait ainsi le lien entre le mot « chat » (ou plutôt, sa traduction en nombre) et les images de chat !

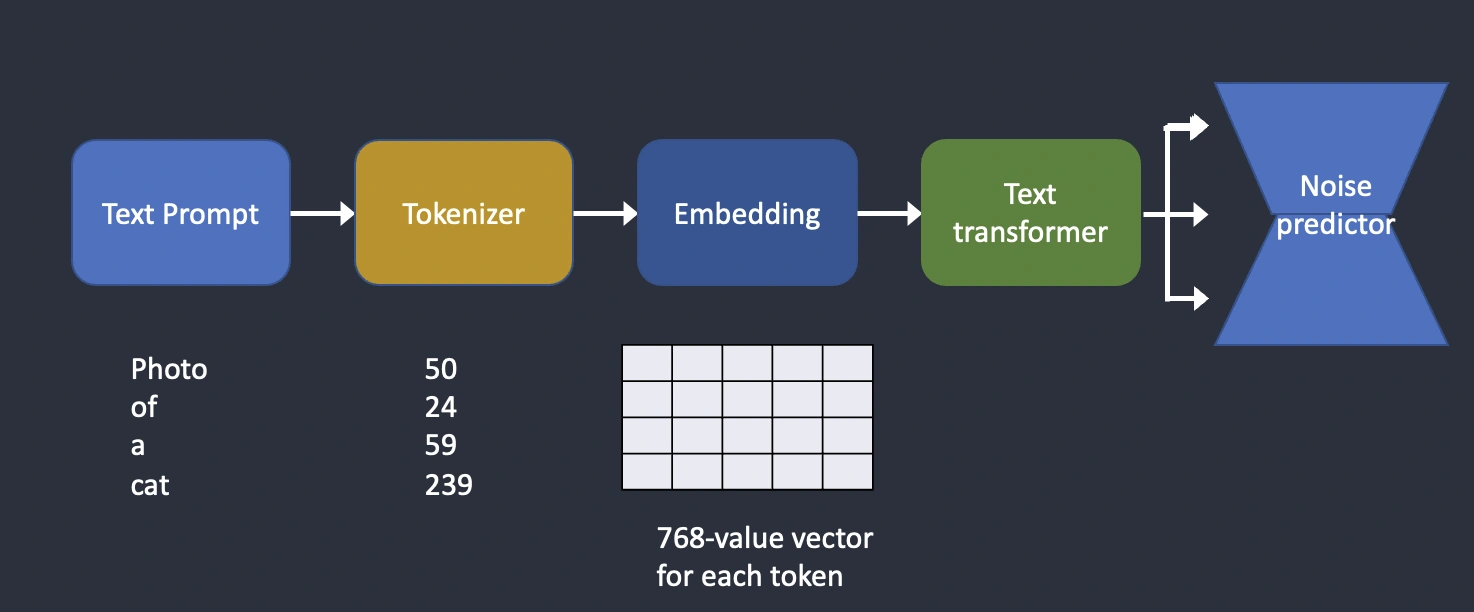
En résumé, voilà le fonctionnement du bousin (Crédit : toujours stable-diffusion-art.com)
Ainsi, au final, les mots sont hachés par un premier réseau, leur sortie est elle-même combinée à une bouille de pixels compressée et donnée à manger à notre modèle basé sur de la diffusion latente. Ce dernier itère pour raffiner sa sortie un grand nombre de fois nommé sampling step. Il en sort une image, toujours compressée pour gagner en temps, que nous décompressons en utilisant le VAE pour obtenir l’image finale. Quelle complexité !
Un approfondissement vidéo francophone, si le sujet vous passionne !
GPT comme dans ChatGPT
Changeons radicalement de registre avec ChatGPT. Cette fois-ci, il n’est plus question de génération d’image, mais de génération de texte : selon l’entrée d’un humain, le programme doit répondre de manière pertinente, ce qui signifie combiner des tâches d’explications, de synthèse ou encore de discussion non dirigée. Ici, deux nouveautés : l’utilisation d’un réseau de type transformer (un bloc de base depuis repris dans bien d'autres applications du machine learning), et un pré-entraînement (pre-training) dont l’assemblage donne notre GPT, Generative Pre-trained Transformer.
Ici et comme dans StableDiffusion, tout commence par une de l’embedding transformant les mots en nombres. Il en suit une architecture composée de 12 répétitions du bloc transformer (pour GPT-1, 96 répétitions pour GPT-3), dont nous vous reportons la structure principale ici :

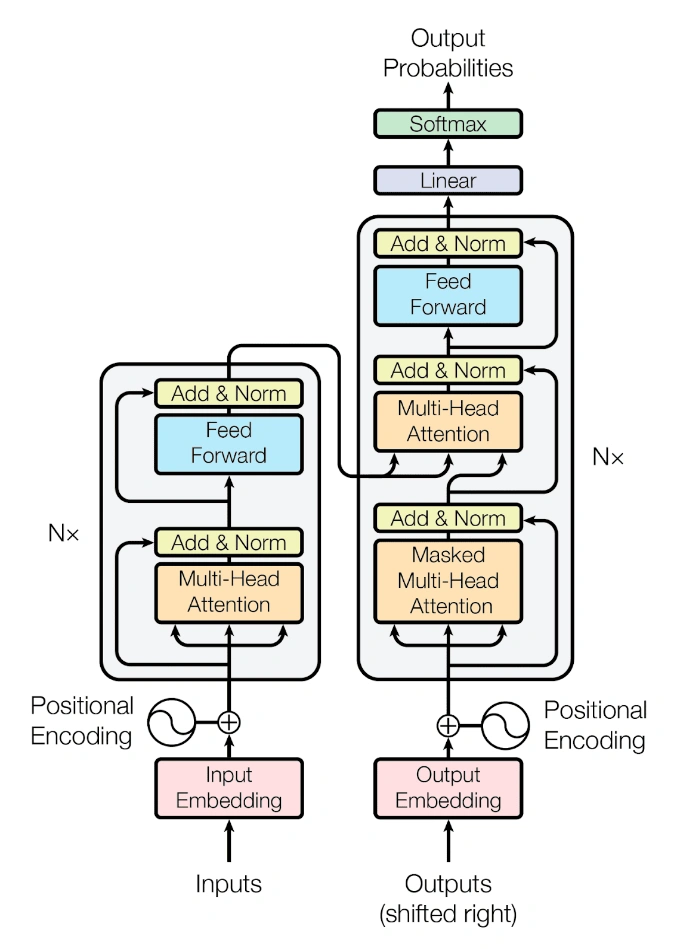
Le détail d’un transformer : encodeur à droite, décodeur à gauche (Source : Attention Is All You Need)
L'idée est de succéder aux LSTM et aux GRUs que nous avions abordés deux pages plus tôt en reposant sur la notion d'attention, c'est à dire en utilisant le contexte des mots pour modifier leur sens via la couche Multi-Head Attention (dont nous vous évitons le détail, à moins de vouloir faire une thèse en IA !). La couche Feed Forward est grosso modo l'analogue des couches denses version texte, et nous retrouvons des additions provenant des couches précédentes (nos résidus !) et la normalisation permettant de s'assurer que les résultats intermédiaires restent cohérents. Enfin, le transformer originel possède une particularité supplémentaire : il est composé de deux blocs : un encodeur et un décodeur, car il servait initialement à de la traduction. Le premier bloc comprenait l'anglais, le second le français, et ta-daaa, vous avez un traducteur. Pour ChatGPT, seul le décodeur est utilisé car il est question de génération.
Enfin, une des grandes améliorations de ChatGPT réside dans son mécanisme d'entraînement. Tout commence par le pré-entraînement (pre-training). qui consiste à étalonner le décodeur sur un corpus de texte de manière à lui faire prédire les mots suivants en partant de morceaux de phrases. Qualitativement, cela permet d'apprendre les basiques de la langue au réseau, le B-A.BA de ce qui lui est demandé. Il peut alors répondre, mais n'est vraiment pas malin et à tendance à répéter les mêmes choses en boucle, car la génération de texte consiste à compléter mot-à-mot sa propre sortie, et donc à rapidement se mordre la queue.
Ainsi, une seconde phase d'ajustement (fine-tuning) a lieu, qui est elle-même composée de deux étapes : SFT (Supervised Fine-Tuning), qui utilise un ensemble de dialogues annotés comme étant bons (par exemple une réponse à une question ou un compliment) ou mauvais (par exemple lorsque des sujets sensibles / illégaux sont abordés) pour raffiner les sorties du réseaux dans un nouveau round d'apprentissage. Parfois, ces dialogues sont eux-même des sorties d'autres réseaux... la boucle est bouclée ! La dernière phase d'ajustement vise à corriger cette déviance en faisant directement appel à l'humain, qui va (nous simplifions ici à l’extrême) passer en revue les sorties du réseau pour annoter les meilleurs des moins bonnes, et utiliser yet another réseau pour apprendre les sorties souhaitées. Finalement, c'est ce dernier réseau qui est utilisé pour corriger le modèle génératif, et pouf ! Voilà ChatGPT... aux secrets professionnels de la firme près, évidemment.


Les étapes complètes de l’entraînement du réseau : pré entraînement et ajustements (automatisé [SFT] et corrections par l’humain [RLHF])
Terminons par un peu plus de vulgarisation encore, tant le sujet mérite d'être creusé !
Avoir une architecture de réseau chiadée, c’est important pour que les bousins soient optimisés pour certaines tâches. Cependant, cela ne fait pas tout, puisqu’il faut lui donner à manger des informations préalablement à son utilisation : c’est l’apprentissage. Rendez-vous à la page suivante pour voir en quoi cela consiste !



Merci beaucoup pour cet article, j'en avais bien besoin. J'ai découvert de nombreux détails, notamment la problématique du sur apprentissage.
Heureux de t'avoir été utile :D !
Pas encore lu, mais sur la vignette miniature de la colonne des dossiers, j'ai bien cru que c'était le majeur qu'il tendait. Ça commence bien...
"F*ck, la race humaine" 🤣
Merci pour ce dossier que j'ai lu avec beaucoup de retard. C'est complet, détaillé, et surtout pointu malgré la presque absence de maths.