
Blackwell
Si vous n’êtes pas ou peu familiers avec les microarchitectures modernes du caméléon, voici un bref récapitulatif du principe d’organisation de ces dernières, en commençant par une vue macroscopique de Blackwell (version grand public) illustrée par le diagramme de blocs de GB202, la puce la plus haut de gamme. Vous pouvez aussi vous référer à la partie architecturale d'Ada Lovelace ici même. Au sommet, juste sous l’interface PCIe (qui adopte la génération 5.0) permettant la communication entre GPU et CPU, se trouve le processeur de commande que NVIDIA nomme Gigathread Engine, en charge d’ordonner et affecter les différentes tâches aux unités composant le GPU.
A côté, apparait ce que NVIDIA nomme AI -Management Processor ou AMP, que nous détaillerons un peu plus bas. Au-dessous prennent place les moteurs d’affichage, décodage et encodage vidéo, ainsi qu’un bloc Optical Flow Engine servant à l’analyse du flux optique utilisée pour les traitements vidéo et pour les joueurs au sein du RTX Frame Generation introduit avec les RTX 40. Sur les côtés du diagramme, sont disposés les 16 contrôleurs mémoires 32-bit (+ 33% vs AD102) permettant l’accès à la VRAM. Au centre se trouvent 128 Mo de cache L2 (là aussi en progression d’un tiers puisqu'une partition de 8 Mo est associée à chaque contrôleur mémoire depuis Ada) et, tout autour, des structures nommées Graphics Processing Cluster, que nous allons détailler.

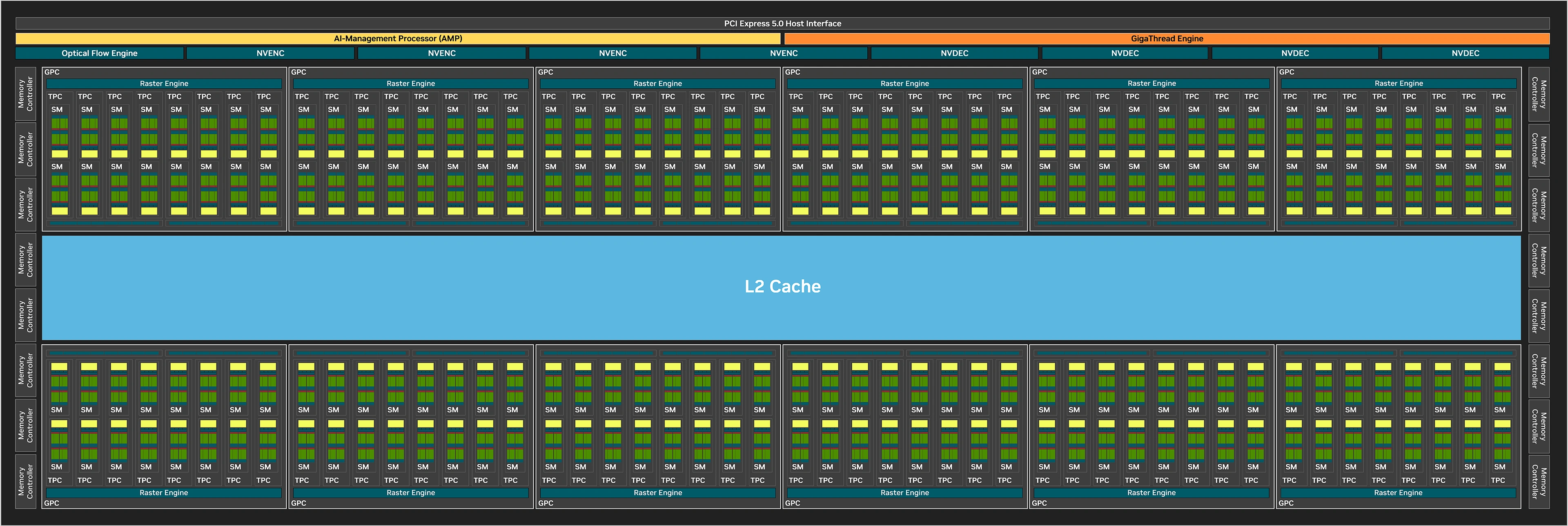 Diagramme de blocks GB202
Diagramme de blocks GB202
Le diagramme d’un GB202 complet
Ces GPC comprennent en leur sein les unités constituant les piliers de l’architecture, à savoir les Streaming Multiprocessors qui seront, elles, décortiquées un peu plus bas. À l’instar de Turing/Ampere, ces SM sont regroupés par paire au sein de structures nommées TPC (Texture Processor Cluster), incluant le Polymorph Engine, c’est-à-dire les unités dédiées à la géométrie (vertice, tessellation). 8 TPC prennent place au sein d’un GPC (6 sur AD102), ce dernier disposant également d’une unité de rastérisation (Raster Engine) capable de traiter (découper en pixels) un triangle par cycle. Au total, GB202 comprend 12 GPC, soit le même nombre qu’AD102, dans leurs versions complètes respectives.
Les ROP (Render OutPut units) — qui sont les unités de rendu en bout de chaîne du pipeline graphique, sont chargées d’écrire en mémoire les pixels calculés précédemment (mais aussi d’appliquer les éventuels MSAA, blending, etc.) — sont également intégrés au GPC depuis Ampere, et ce via 2 partitions de 8 ROP, soit 16 en tout. Avec 12 GPC x 16 ROP, ce sont pas moins de 192 ROP qui sont présents sur un GB202 intégral, à l’instar de son devancier. Le fillrate ne progresse donc pas et régresse même légèrement du fait de fréquences officielles moindres. Voilà pour cette partie « macroscopique » de la microarchitecture GPU, entrons à présent dans le détail avec les Streaming Multiprocessors de cette génération Blackwell.
Ciao dual issue
Le Streaming Multiprocessor correspond à l’entité « à tout faire » chez NVIDIA. Au sein de cette dernière se trouvent différents types d’unités, dont les ALU (Arithemtic Logic Unit) dédiées aux calculs et spécialisées soit pour les entiers (INT32), soit pour les flottants/décimaux (FP32) 32-bit (dénommé simple précision). Ces dernières peuvent également s’adapter à des précisions moindres en accélérant la vitesse de traitement, comme par exemple la demi-précision (FP16) à débit doublé. Il existe également des unités capables de traiter des flottants 64-bit (FP64 ou double précision), mais elles ne sont utilisées que pour des tâches particulières dans le domaine professionnel/scientifique, sans intérêt pour une carte grand public.
Cette organisation est en vigueur depuis Fermi, mais a bien entendu évolué génération après génération, tant au niveau du nombre d’unités que de leur type. À l’origine, les verts parlaient des CUDA Cores comme étant le regroupement d’une ALU INT et d’une ALU FP, mais cette définition a évolué avec Ampere et Ada, puisque NVIDIA a implémenté 2 unités FP32 pour une unité INT32. Au lieu de présenter cela comme des cœurs typés Dual Issue, les verts ont préféré compter chaque unité FP32 comme un Cuda Core (les gros chiffres, Bob du marketing adore).

Mais, le Dual Issue est loin d’apporter des gains en jeu équivalents à un véritable doublement des CUDA Cores, puisqu’une des 2 unités de flottants doit partager son chemin de données avec l’unité d’entiers et requiert des conditions spécifiques d'usage. Les SM de Blackwell reviennent ainsi à une organisation pré-Ampere, chaque CC pouvant à présent calculer un INT32 ou FP32 par cycle, ce qui correspond donc au doublement du nombre d’unités INT32 par SM — ah, les va-et-vient des architectures ! Ces derniers sont toujours organisés en 4 partitions, chacune étant pilotée par un couple ordonnanceur/dispatcheur (32 threads/cycle). Elles incluent chacune 32 ALU INT32 et 32 ALU FP32, 4 TMU (unités chargées du texturing), 4 unités load/store pour les accès mémoire, un cache L0 dédié aux instructions, 64 Ko pour les registres 32-bit, 4 SFU traitant les fonctions complexes (Cos, Sin, etc.), un Tensor Core de cinquième génération (que nous détaillerons plus bas).
Des unités FP64 sont bel et bien présentes, mais non représentées sur le diagramme ci-dessous. Leur nombre est toutefois réduit (elles servent surtout à des fins de compatibilité avec les applications en faisant usage), avec un rapport de 1/64 en comparaison des FP32. À cela s’ajoute un RT Core (de quatrième génération, que nous détaillons ci-après), 128 Ko de cache L1 unifié avec la mémoire partagée et le cache de textures. NVIDIA n’indique pas les valeurs de ce partage, mais elles sont probablement inchangées par rapport à Ampere/Ada. Dans un contexte de charge graphique, la répartition était la suivante : 64 Ko pour L1 + Texture cache, 48 Ko de mémoire partagée et 16 Ko réservés pour diverses opérations au niveau du pipeline graphique. Pour récapituler, un SM Blackwell intègre donc 128 Cuda Cores, un RT Core, 4 Tensor Cores, 256 Ko de registres et 128 Ko de cache L1/mémoire partagée.

 Diagramme d'un SM Blackwell
Diagramme d'un SM Blackwell
Un SM Blackwell
Grosse nouveauté pour Blackwell, les shaders (programmes exécutés au sein du GPU) intègrent (enfin !) les Tensor Cores comme une unité unifiée au sein du SM, c’est-à-dire directement utilisable par les threads de manière asynchrone, au lieu d’être séparée et partagée comme dans les microarchitectures précédentes. De ce fait, les shaders prennent le nom de Neural Shaders et peuvent comprendre des tâches d’IA — typiquement de la décompression de texture, cf. section suivante pour plus de détails à ce sujet - mêlées à du rendu par rastérisation ou Ray Tracing.

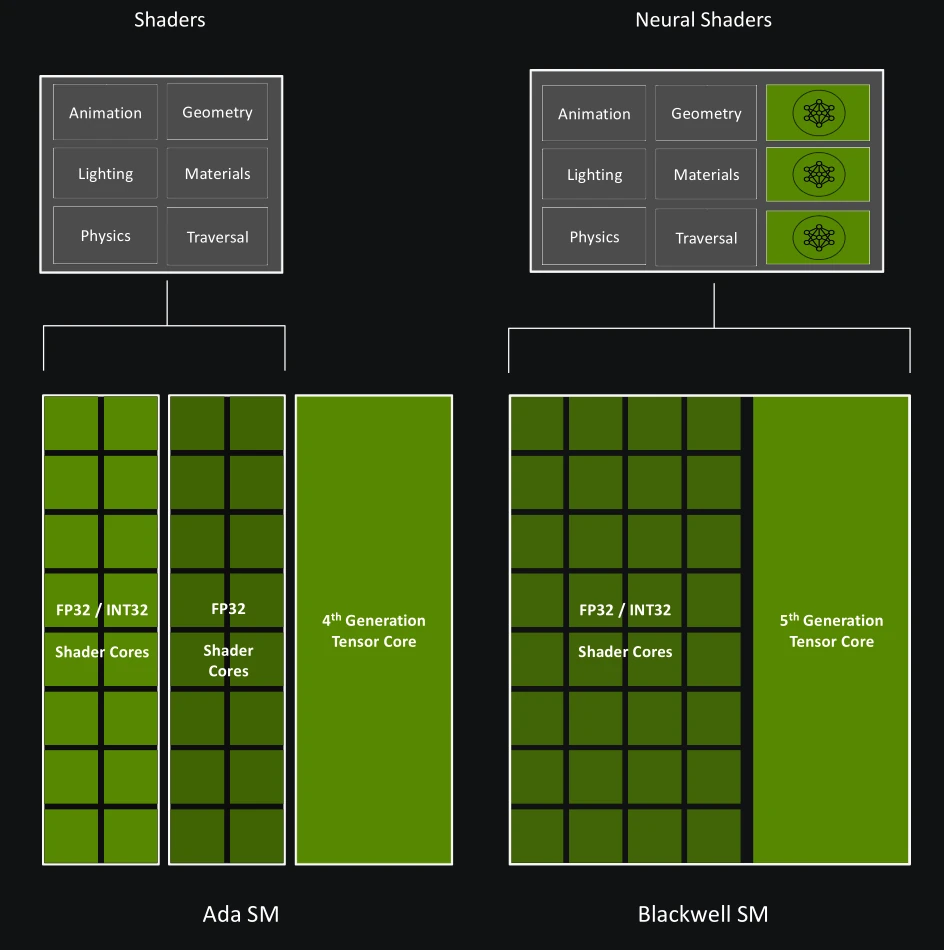
Les shaders neuronaux, c’est ça !
Des RT Cores améliorés
Turing avait marqué une rupture en étant la première architecture à inclure des unités dédiées à l’accélération matérielle du Ray Tracing ou plus précisément de l’algorithme BVH (Bounding Volume Hierachy). Ce dernier consiste à utiliser des « boites » successives pour détecter les impacts entre rayons (objets de base du Ray Tracing) et triangle (objets de base d’un modèle 3D). En parcourant une arborescence (subdivision ordonnée par imbrication) de ces boites, il est très efficace de retrouver où se situe exactement le triangle frappé par un rayon : en effet, un parallélépipède rectangle est une forme géométrique 3D très simple, le calcul des intersections y est aisé. 3 étapes peuvent être identifiées : intersection avec les boites, traversée de l’arbre et enfin intersection avec le triangle touché. Tous les GPU contemporains reprennent cette approche, mais l’implémentation et les blocs accélérés diffèrent selon les concepteurs. Ci-dessous une image animée décrivant succinctement le fonctionnement du BVH.

 Principe du BVH
Principe du BVH
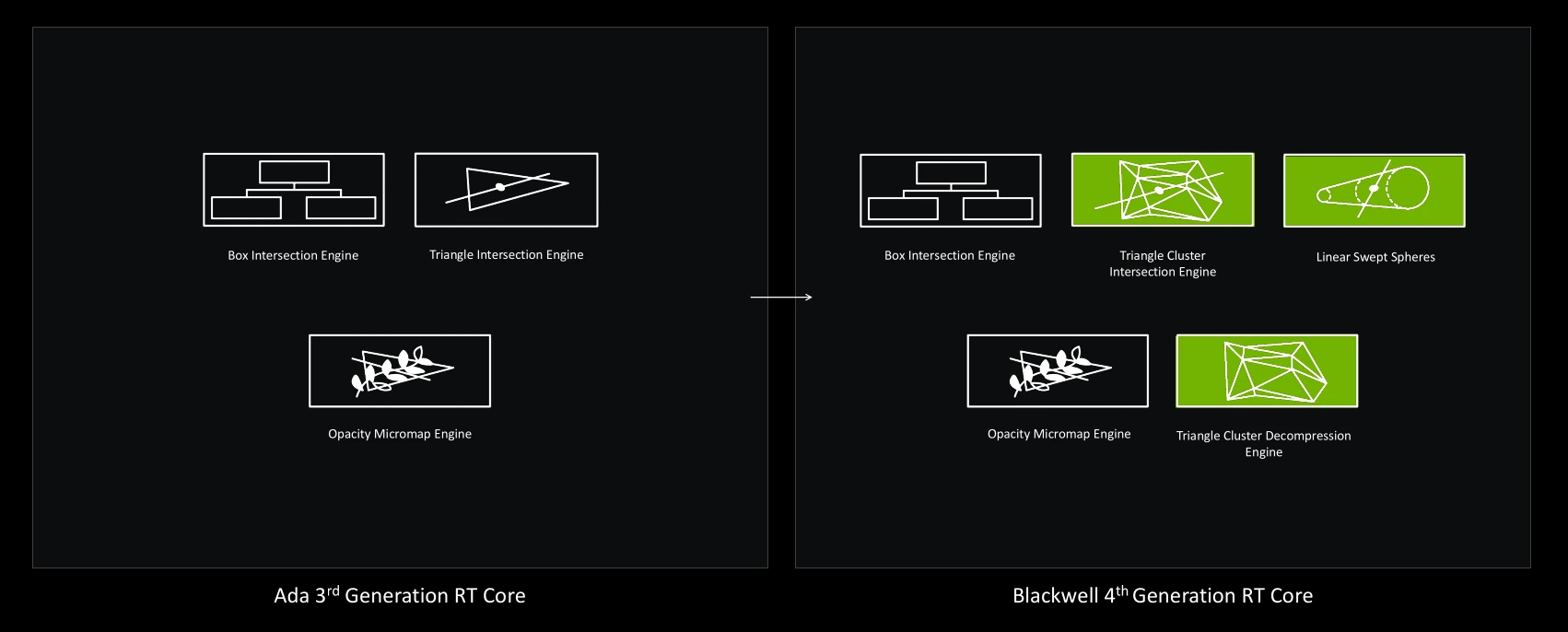
Ampère utilisait de son côté des RT cores de seconde génération, disposant d’un débit doublé pour le calcul des intersections des rayons avec les triangles, ainsi qu’une unité accélérant l’application du flou cinétique lors des rendus. Ensuite, les verts ont inclus aux RT Cores d’Ada, une unité capable d’effectuer les opérations Alpha (transparence), ainsi que la gestion locale de déformations des modèles 3D via la prise en charge de Micromap.
Avec Blackwell, une modification majeure et deux nouveaux accélérateurs sont à l’honneur. D’une part, l’unité de traitement des intersections de triangles se voit gonflée pour doubler (par rapport à Ada) de débit et est désormais dotée de la capacité de calculer des intersections sur des assemblages (clusters) de triangles, une amélioration que NVIDIA retranscrit comme le passage à un Triangle Cluster Intersection Engine, faisant partie d’une technologie nommée Mega Geometry que nous allons à présent expliciter.

Mega Geometry
Derrière cette dénomination marketing, se cache la volonté d’améliorer la fidélité des détails lors du rendu, plus précisément en limitant les phénomènes de clipping, ici dans le cas où un modèle 3D low-poly (niveau de détail moins élevé) est utilisé en proxy de la version haute définition, de manière à limiter le temps de rendu. En pratique, cela se traduira en des objets et des ombres toujours plus fidèles, en particulier lorsque le sujet est lointain et/ou en dehors du champ de vision direct de la caméra. Encore une fois, l’intention est louable, encore faut-il que les moteurs ainsi que l’optimisation des titres soient également au rendez-vous pour tirer parti de la technologie ! Pour rappel, les Micro Meshes avaient été lancées avec Ada pour aider déjà à ce sujet, mais n'avaient jamais décollé puisque boudés par les développeurs, pas friands des calculs de translation des triangles. A que cela ne tienne, le caméléon propose une nouvelle approche qui connaitra peut-être meilleur sort.
Comment cela se fait-il ? Hé bien, à l’aide d’une méthode nommée Cluster-level Acceleration Structures : au lieu d’utiliser différents modèles 3D (un HD et un SD), les différents niveaux de détails sont directement intégrés au sein de l’objet et pris en compte dans la structure du BVH en groupant dans un cluster un maximum de 256 triangles — bien évidemment calculables de concert par les RT Cores, après une étape de traitement par le nouveau Triangle Cluster Decompression Engine. Outre les bénéfices habituels du clipping (c’est-à-dire un gain de performance dans les situations où le moteur de rendu juge que le niveau de détail « bas » est suffisant), cette structure permet une transition plus rapide entre niveaux en évitant d’avoir à reconstruire l’arborescence BVH à chaque changement, tout en rendant les transitions moins abruptes. Enfin, une telle prise en charge permettra ultimement de déporter entièrement la gestion des niveaux de détails au sein du GPU, limitant une nouvelle fois le ping-pong entre CPU et GPU : tout bénèf' !

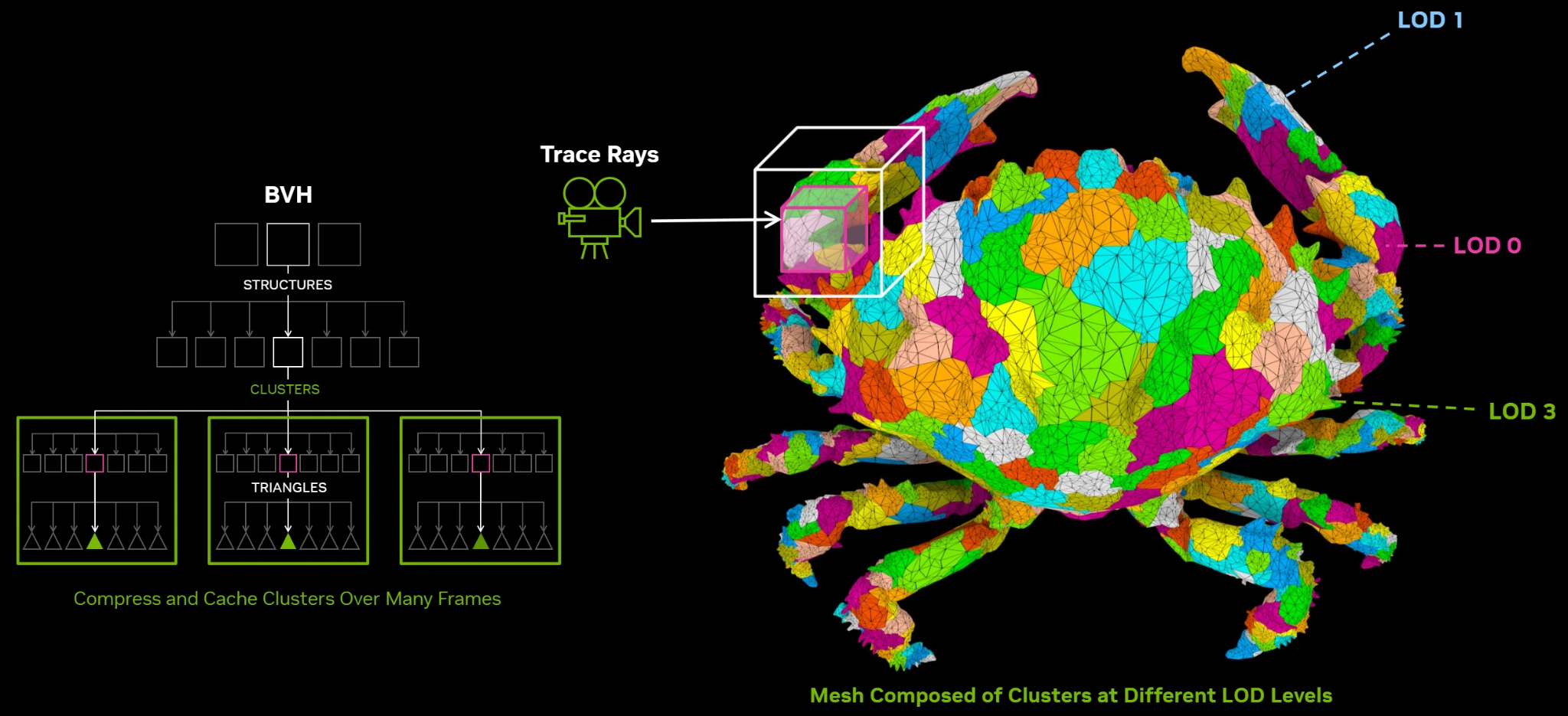

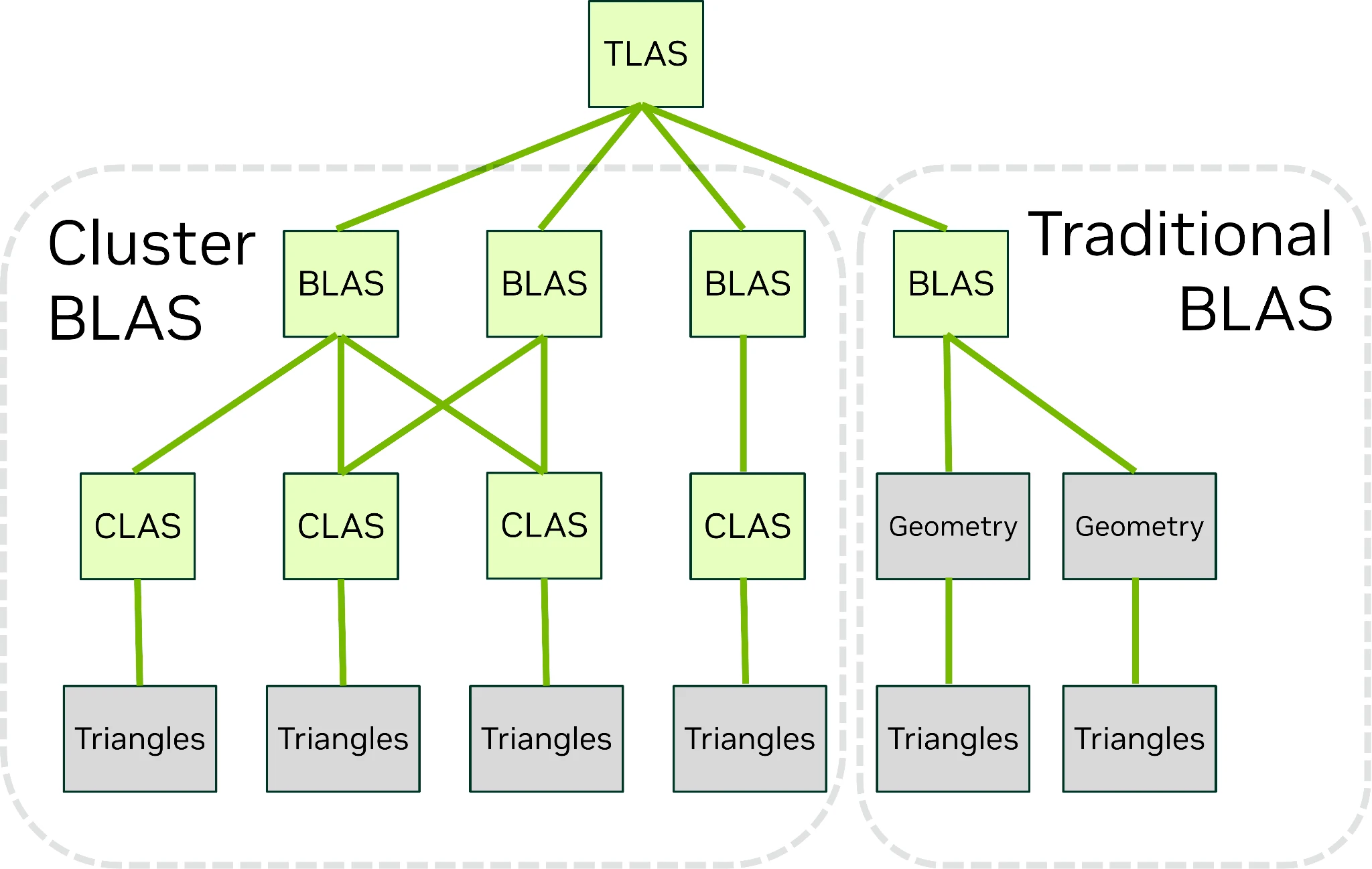
Tout en haut, représentation graphique des clusters sur un modèle 3D. En bas à gauche, arborescence correspondante. En bas à droite, arborescence sans clusters.
Dans une même philosophie, les objets sur lesquels appliquent le Ray Tracing peuvent également être combinés en clusters au sein d’un Partitioned Top-Level Acceleration Structure. Normalement, les objets cibles du lancer de rayon sont regroupés dans un TLAS, ou Top Level Acceleration Structure, une structure de données qui doit être recalculée à chaque image du fait de la possible appartition ou disparition de certains objets. Comme cela est peu fréquent en jeu, le Partitionned TLAS permet de conserver au sein d’une unique structure, ordonnée en partitions, l’ensemble des objets de manière à pouvoir mettre à jour les objets dynamiques en les plaçant dans une « partition globale » séparée.

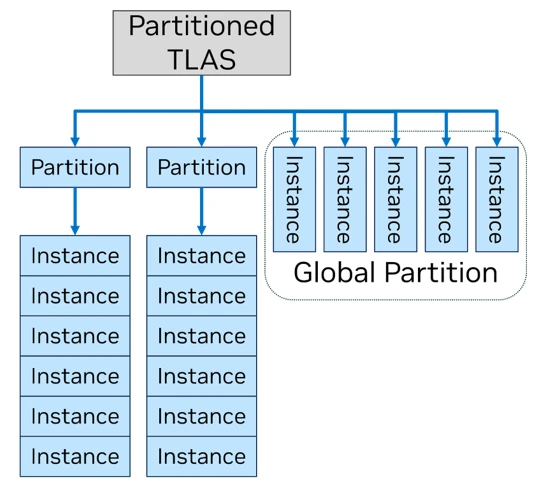
Structure du Partitioned TLAS : la Global Partition est la seule à pouvoir être mise à jour dynamiquement.
Toutes mises bout-à-bout, ces technologies permettent de reconstruire les volumes BVH directement par le GPU lors des changements de scène à partir des clusters (globaux ou locaux), offrant ainsi une tesselation (étape consistant à découper une surface en blocs élémentaires) à plus gros grains que les habituels triangles des rendus 3D temps réel. De quoi suggérer des gains toujours plus faramineux en Path Tracing !
Linear Swept Spheres
Lors des rendus en temps réels, les rendus de structures filiformes — herbes, cheveux, fourrures, etc — sont particulièrement difficiles à effectuer par un GPU, du fait du grand nombre de triangles et des shaders personnalisés nécessaires pour un rendu naturel. Cela a mené au développement de technologies comme NVIDIA Hairworks, qui trouve désormais son prolongement version Ray Tracing avec l’apparition d’unités de traitement dédiées : les Linear Swept Spheres. Ces dernières permettent d’accélérer un des tricks utilisés dans le rendu de brins : les Disjoint Orthogonal Triangle Strips. Ces dernières consistent à modéliser les fils comme des triangles orthogonaux ordonnés en un motif disjoint le long du brin, remplaçant ainsi des cylindres reliés les uns aux autres. Malheureusement, cette approximation s’effectue au détriment de la qualité du rendu, car des artefacts se produisent aux jointures entre assemblages de triangles, comme le montre l’illustration ci-dessous.

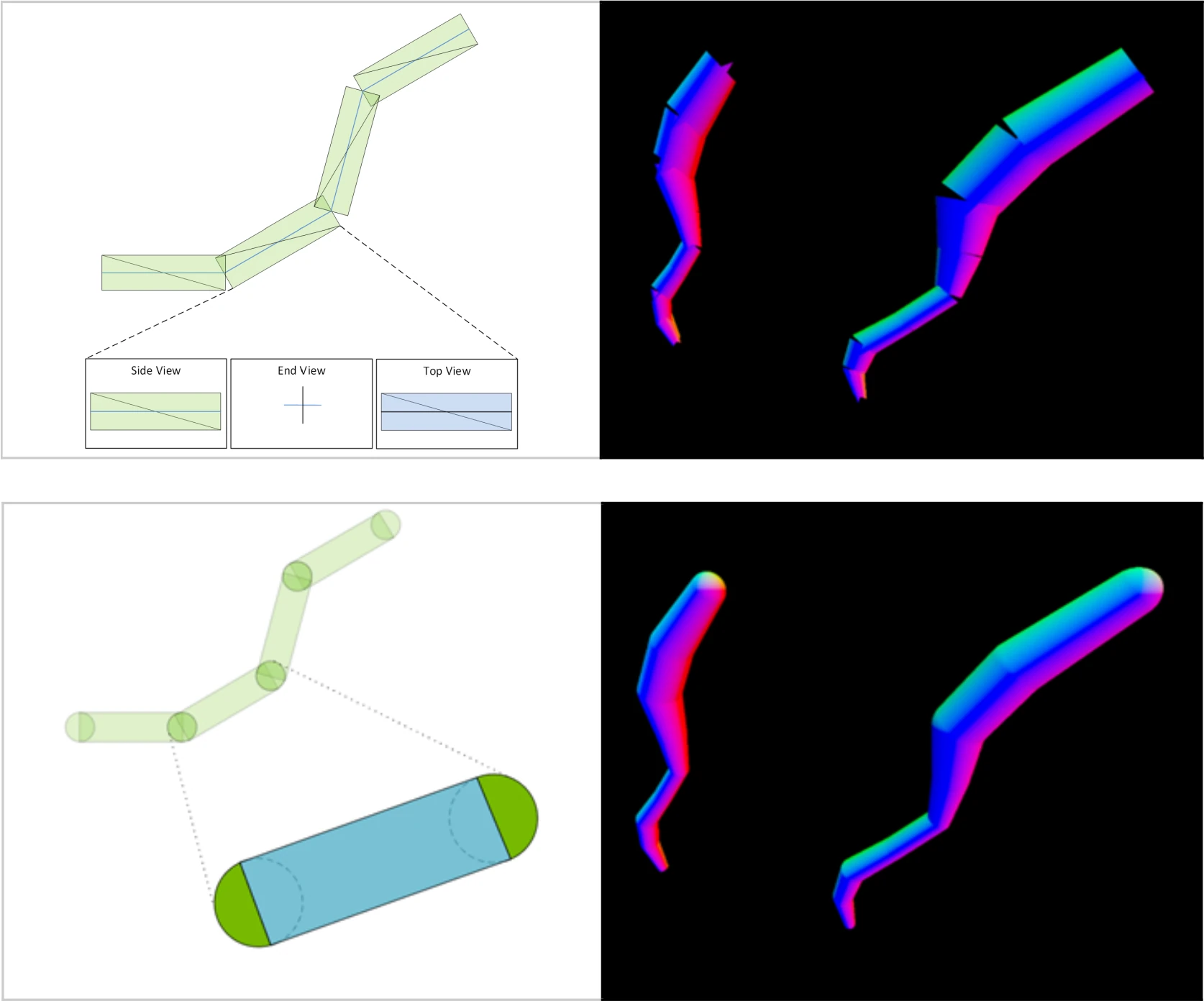
En haut : approximation Disjoint Orthogonal Triangle Strips, en bas, Linear Swept Spheres
Pour pallier ce problème, les Linear Swept Spheres représentent tout bonnement et simplement une nouvelle primitive de tesselation correspondant à un cylindre orné de deux demi-sphères (ou la surface balayée — swept — par une sphère parcourant un segment). Notez que le rayon des sphères peut différer entre les deux côtés de la forme, ce qui permet de représenter des brins coniques. Le résultat ? Les cheveux sont rendus 2 fois plus rapidement qu’en utilisant les triangles disjoints (l’avantage d’une accélération hardware ; la technique n’est pas en soit plus rapide computationnellement parlant), tout en utilisant 5 fois moins de VRAM : double gain !
Tensors Cores 5ème Gen
En passant à Blackwell, les Tensor Cores — unités de calcul matriciel — se font une nouvelle jeunesse en passant en 5ème génération. Le cœur du travail ayant déjà été effectué, cette mise à jour n’est qu’un raffinement des fondations existantes, de manière à suivre les dernières tendances en matière de réseau de neurones. Ainsi, la FP4 fait son apparition, un format de données toujours plus réduit (2⁴ = 16 valeurs différentes par nombre) au profit d’un débit de calcul doublé par rapport à la FP8 (qui elle ne progresse pas côté débit). En revanche, les réseaux cibles doivent passer par une phase modifiant potentiellement leur comportement afin de faire usage de cette nouvelle précision, tout cela se passant via NVIDIA TensorRT. Nous notons également une prise en charge en retrait du FP8 lorsque l’accumulation s’effectue avec une précision de 32 bits (débit réduit de moitié par rapport au FP8 à accumulation FP16) : au vu des progrès des méthodes numériques d’optimisation des réseaux et l’investissement sur des précisions plus faibles encore, cela n’a rien de surprenant.

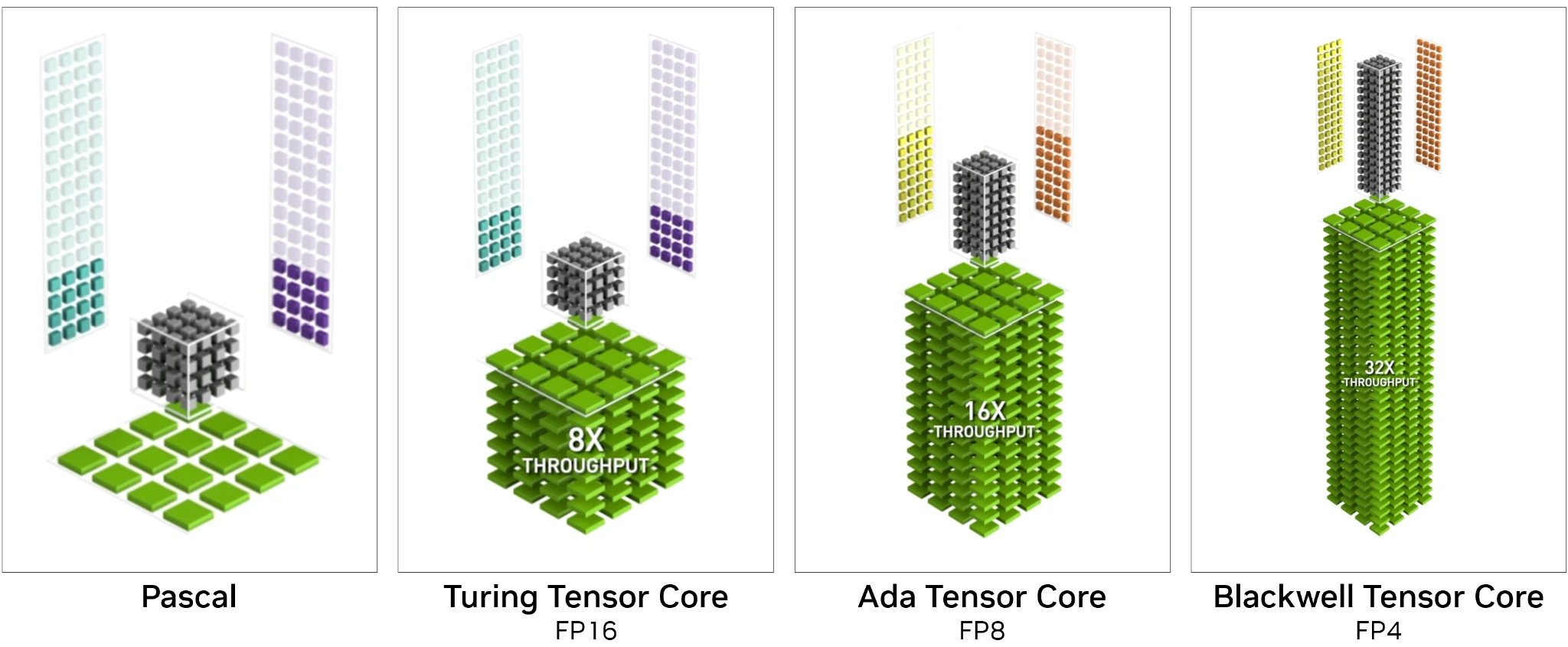
Une naturelle évolution vers le FP4
Moteur d’affichage et vidéo
Continuons notre tour d’horizon par le moteur d’affichage. Le port Virtual Link est malheureusement mort et enterré pour les verts, qui l’avaient pourtant introduit avec Turing. Pour rappel, ce dernier permettait de regrouper au sein d’un connecteur USB Type C, le flux d’affichage, de données et l’alimentation destinée aux casques VR. De nombreux acteurs de la VR étaient partie prenante de ce projet, pourtant aucun casque n’a vu le jour utilisant ce format. C’est une déception, une de plus dans l’univers de l’informatique, impitoyable pour certaines technologies. Nouveauté par rapport à Ada, le DisplayPort 2.1b fait enfin son apparition, ce qui permet de transmettre un maximum de 80 Gb/s d’informations vidéo vers votre moniteur via 4 flux indépendants, pouvant atteindre jusqu'à 16K @ 60 Hz ou 8K @120 Hz via le truchement du Display Stream Compression (un algorithme de compression « visuellement sans perte »), ainsi que 4K/UHD @ 240 Hz sans DSC - attention toutefois, il faudra se munir d’un câble compatible ! Le HDMI est également toujours bien présent, en version 2.1 toujours en attendant la prochaine évolution du standard.

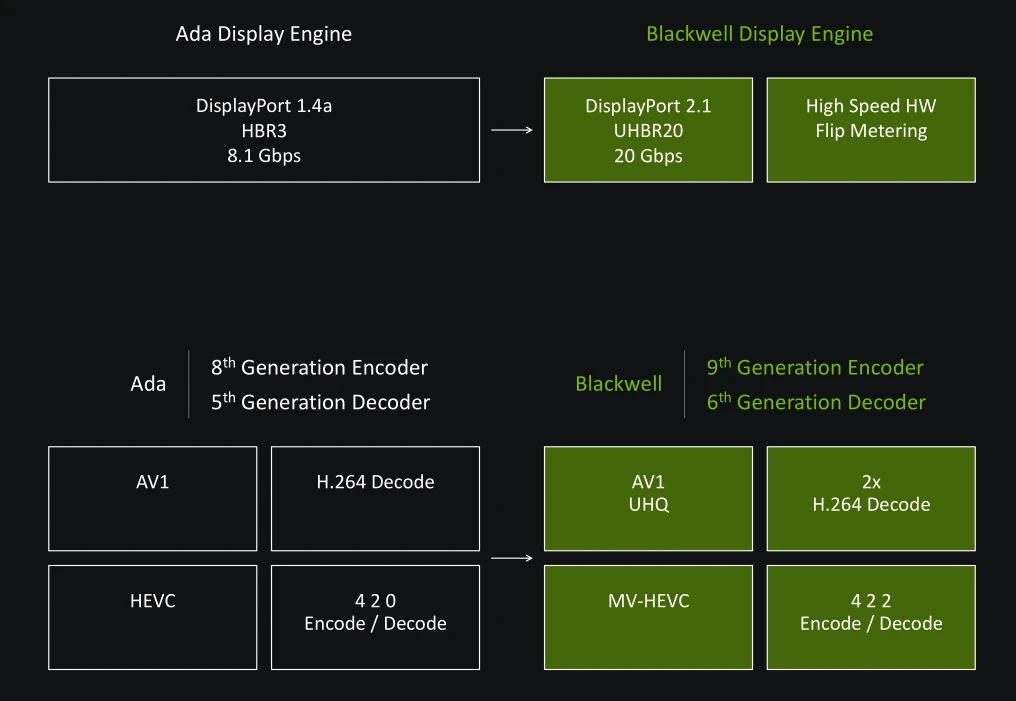
Passons à présent au moteur vidéo. Sur le front du décodage, NVIDIA se met à niveau avec la sixième itération de son NVDEC, dont la grande nouveauté se situe dans la prise en charge du format de couleurs YUV 4:2 : 2 (le 4:4 : 4 correspondant au natif, et le 4:2 : 0 une légère compression des couleurs, utilisée notamment dans des Blu-ray ou sur les services de streaming ; le 4:2 : 2 proposant un juste milieu, typiquement pour des éditions vidéos avant le rendu final) en H.264 et HEVC. Au passage, le décodage est désormais deux fois plus rapide en H.264, de manière à rattraper le débit AV1/HEVC. Une preuve que cet algorithme de compression vidéo est encore loin d’être mort ! Côté encodage, il y a cette fois du neuf à se mettre sous la dent, avec un NVENC qui passe à la génération 9 en ajoutant également la prise en charge des formats de couleurs YUV 4:2 : 2. NVIDIA communique aussi sur des progrès de son encodeur AV1, offrant entre 10 et 15 % de fidélité (mesuré en Peak Signal to Noise Ratio) dans un nouveau mode Ultra Haute Qualité (UHQ), et 4 à 5 % de progrès dans le mode normal, le tout mesuré en UHD. Pour les intéressés, ce mode UHQ sera également rétroporté sur les RTX 40, mais offrira toujours une qualité moindre que sur les encodeurs de Blackwell. Rajoutez que NVIDIA a muni sa RTX 5090 de trois encodeurs et deux décodeurs (la puce GB202 complète en comprenant 4 + 4 d'après son diagramme), ce qui offre des performances en hausse d’un facteur 1,5 par rapport à la RTX 4090 sur le terrain de l’encodage vidéo matériel.
Des améliorations électroniques
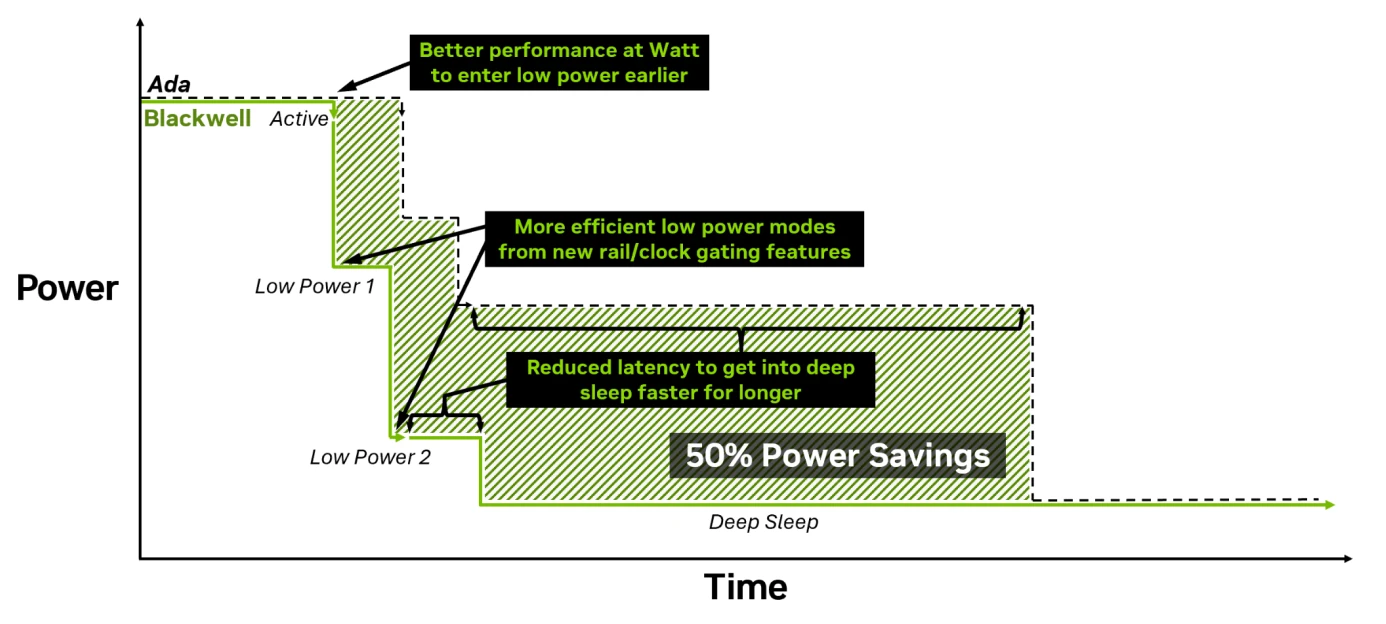
Plus tout à fait dans l’architecture, mais davantage dans le design du circuit, Blackwell fait des progrès au niveau de la gestion de son courant de manière à améliorer son efficacité dans les cas où le TDP est fortement contraint — comprendre, les fameuses séries Max-Q permettant de faire rentrer une gargantuesque RTX 5090 dans un ordinateur portable. À ce niveau, les verts présentent des capacités de power gating (méthode consistant à éteindre physiquement le courant dans certaines parties de la puce lorsqu’elles ne sont pas utilisées) plus avancées, car décomposées en trois niveaux : contrôle de l’horloge (clock gating, classique), mais également de l’alimentation (power gating, également classique) mais aussi directement des rails (rail gating) différents pour le GPU et la mémoire. Avec cela, Blackwell peut ainsi éteindre certaines parties de la carte avec une granularité (spatiale comme temporelle) toujours plus fine.


Mais ce n’est pas tout : la gestion de la fréquence est également revue et jusqu’à 1000 fois plus rapide. Rien que ça ! En fait, cette dernière était auparavant gérée à la granularité de la frame : impossible de modifier la cadence pendant le calcul d’une image, ce qui pouvait mener à des surconsommations locales, et ainsi une drastique chute de fréquence par la suite pour rester dans l’enveloppe thermique, créant des micro-latences fortement désagréables. Désormais, cette limitation n’a plus cours, ce qui permet également de diminuer la fréquence entre frames (par exemple dans le cas d’un écran G-Sync) et, ultimement, gagner en efficacité énergétique.

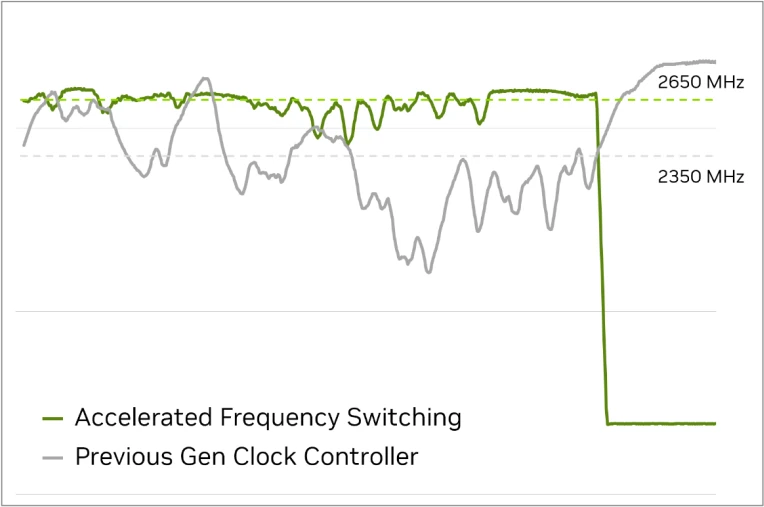
L’effet de la nouvelle méthode de gestion de la fréquence : plus haut quand il le faut, plus bas par la suite !
Grâce à ces améliorations, NVIDIA communique également sur une durée plus faible d’entrée en veille, ce qui permet un gain de 50 % de la puissance nécessaire. Inutile ? Pas tant que cela : si le GPU est réveillé pour réaliser une tâche d’inférence courte (au hasard, dans des PC Copilot+…), la consommation à l’activation/désactivation de la carte est cruciale pour conserver une autonomie décente. À voir en pratique !

La GDDR7 entre en scène
Côté mémoire, la RTX 5090 marque l’entrée de la GDDR7 sur le marché des joueurs. Sans rentrer trop dans les détails — cela peut être très, très long ! — cette génération utilise pour la communication avec le GPU des signaux PAM3, c’est-à-dire représentant trois états par transfert. Un recul par rapport à la GDDR6X (PAM 4, soit 4 états/2 bits), mais une avancée comparé à la GDDR6 ; qui permet de monter en cadence plus facilement au niveau électronique. Rajoutez une correction d’erreur incluse directement dans le standard — tout comme la DDR5 — de manière à pouvoir utiliser des dies possédant des défauts de gravure sans que cela n’ait de conséquence à l’usage, et voilà un premier aperçu de la bête. Donnée pour dépasser les 36 Gpbs par pin, la RTX 5090 n’utilise pour le moment « que » des modules cadencés à 28 Gbps, ce qui laisse de la marge pour la fiabilité ainsi que pour d’éventuelles autres références rafraîchies dans le futur.
Enfin, la GDDR7 inclut un état de veille avec réveil rapide, ce qui permet, allié aux améliorations électroniques de Blackwell, de pouvoir éteindre totalement l’horloge mémoire lorsque cette dernière n’est pas utilisée, pour toujours plus de gains au niveau de la consommation. Youpi !
Interface
Intégré sur les dernières générations de processeurs et de cartes mères, le PCIe 5.0 fait sa première apparition sur un GPU grand public avec Blackwell. Cette nouvelle interface double la bande passante disponible entre la carte et le processeur central pour atteindre 8 GTr/s par ligne (partagé entre débit montant et descendant), soit 128 Gtr/s sur un bus x16, ce qui se révèle bien pratique pour des utilisations de type DirectStorage — bien que la liste des titres supportés ne soit pas encore bien longue — ou l’entraînement de réseau de neurones (une seconde application bien plus probable vu le placement en gamme de la RTX 5090 !).
C’en est (presque) tout pour les changements à l’œuvre au niveau architectural de Blackwell, direction la page suivante pour voir comment les verts ont casé toujours plus d’IA dans le pipeline de rendu habituel.




C'est parti pour un peu de lecture, merci d'avance pour votre test !!
🙏
Merci pour le test les copains ! 💯
🙏
Merci beaucoup pour le test, très complet!
Alors certes elle a de la patate et est à l'aise en upscale + FG, mais voilà la conso (et la température des puces mémoire, aouch)!
🙏
Merci Hardware & Co pour cet article de qualité (et les petites touches de cultures).
Bonne journée.
Quelques points à signaler vu l'ampleur du dossier et le temps imparti pour le réaliser :
Merci pour votre compréhension
Cool le test merci
rajouter une passe en UHD RT mais sans DLSS? Parce que le DLSS ca fonctionne mais on le sait depuis les premières RTX!
30 heures de boulot mini, désolé je peux pas. Il fallait que je case quelque part l'apport du DLSS 4. Sur 4 def/réglages, il y en a 3 sans DLSS/FSR et c'est en UHD RT qu'il fait plus sens.
Ouai je comprend , après je n'ai clairement pas la même vision sur le dlss!
Avec le DLSS 4 il y a match ! C'est justement tout l'intérêt de cette nouvelle version utilisant Transformer
Toute mes excuses j'avais sauté la page dlss 4, il y a l'info que je souhaitais, mea culpa!
Il n'y a pas de mal, c'est vrai que j'ai ajouté les tests en UHD RT natif dans la page DLSS 4, mais ça se limite à la seule 5090 et les 4 jeux testés, tant mieux si tu as trouvé ton bonheur.
Pour un test partiellement "rushé" 🙃 c'est juste incroyable le travail réalisé 🤩
Merci 🤸♂️