
ADA Lovelace
Si vous n'êtes pas ou peu familiers avec les microarchitectures modernes du caméléon, voici un bref récapitulatif du principe d'organisation de ces dernières, en commençant par une vue macroscopique d'Ada Lovelace illustrée par le diagramme de blocs d'AD102, la puce la plus haut de gamme. Au sommet, juste sous l'interface PCIe permettant la communication du GPU avec le CPU, se trouve le processeur de commande que Nvidia nomme Gigathread Engine, en charge d'ordonner et affecter les différentes tâches aux unités composant le GPU. Juste au-dessous prennent place les moteurs d'affichage, décodage et encodage vidéo, ainsi qu'un bloc OFA que nous expliciterons en fin de page. Sur les côtés du diagramme, sont disposés les contrôleurs mémoires permettant l'accès à la VRAM. Au centre, un important cache L2 et tout autour des structures nommées Graphics Processing Cluster, que nous allons détailler.

 Diagramme de block AD102
Diagramme de block AD102
Le diagramme d'un AD102 complet
Ces GPC comprennent en leur sein les unités constituant le pilier de l'architecture, à savoir les Streaming Multiprocessors qui seront, elles, décortiquées un peu plus bas. À l'instar de Turing/Ampere, ces SM sont regroupés par paire au sein de structures nommées TPC (Texture Processor Cluster), incluant le Polymorph Engine, c'est-à-dire les unités dédiées à la géométrie (vertice, tessellation). Jusqu'à 6 TPC prennent place au sein d'un GPC, ce dernier disposant également d'une unité de rastérisation capable de traiter (découper en pixels) un triangle par cycle. Au total, AD102 comprend 12 GPC, soit 5 de plus que GA102, dans leurs versions complètes respectives.
Les ROP (Render OutPut units) - qui sont les unités en bout de chaine du pipeline graphique, chargées d'écrire en mémoire les pixels calculés précédemment (mais aussi d'appliquer les éventuels MSAA, blending, etc.) - sont également intégrés au GPC depuis Ampere, et ce via 2 partitions de 8 ROP, soit 16 en tout. Avec 12 GPC x 16 ROP, ce sont pas moins de 192 ROP qui sont présents sur une puce intégrale, le fillrate va donc progresser en conséquence, d'autant que les fréquences font, elles aussi, un bon notable entre générations, grâce au procédé de gravure bien plus performant sur la dernière-née. Après avoir brièvement décrit cette partie "macroscopique" de la microarchitecture du GPU, entrons à présent dans le détail avec les Streaming Multiprocessors de cette génération Ada.
Des SM saveur Ampere
Le Streaming Multiprocessor correspond à l'entité "à tout faire" chez Nvidia. Au sein de cette dernière se trouvent différents types d'unités, dont les ALU (Arithemtic Logic Unit) dédiées aux calculs et spécialisés soit pour les entiers (INT32), soit pour les décimaux (FP32) 32-bit (dénommé simple précision). Ces dernières peuvent également s'adapter à des précisions moindres en accélérant la vitesse de traitement, comme par exemple la demi-précision (FP16) à débit doublé. Il existe également des unités capables de traiter des flottants 64-bit (FP64 ou double précision), mais elles ne sont utilisées que pour des tâches particulières dans le domaine professionnel / scientifique, sans intérêt pour une carte grand public. Cette organisation est en vigueur depuis Fermi, mais a bien entendu évolué génération après génération, tant au niveau du nombre d'unités que de leur type. À l'origine, les verts parlaient des CUDA Core comme étant le regroupement d'une ALU INT et d'une ALU FP, mais cette définition ne survivra pas aux sirènes marketing avec Ampere, comme nous le verrons plus bas.

Un SM Ada est très proche de ceux d'Ampere et organisé en 4 partitions, chacune étant pilotée par un couple ordonnanceur / dispatcheur (32 threads/cycle). Elles incluent chacune 16 INT32 / 32 FP32, 4 TMU (unités chargés du texturing), 4 unités load/store pour les accès mémoire, un cache L0 dédié aux instructions, 64 Ko pour les registres 32-bit, 4 SFU traitant les fonctions complexes (Cos, Sin, etc.), un Tensor Core de quatrième génération et un RT Core de troisième génération (que nous détaillerons tous deux un plus bas). Les unités FP64 sont bel et bien présentes, mais non représentées sur le diagramme ci-dessous. Leur nombre est toutefois réduit (elles servent surtout à des fins de compatibilité avec les applications en faisant usage), avec un rapport de 1/64 en comparaison des FP32. Le cache L1 est unifié avec la mémoire partagée et le cache de textures. Nvidia n'indique pas les valeurs de ce partage, mais elles sont probablement inchangées par rapport à Ampere. Dans un contexte de charge graphique, la répartition était la suivante : 64 Ko pour L1 + Texture cache (x2 / Turing), 48 Ko de mémoire partagée et 16 Ko réservés pour diverses opérations au niveau du pipeline graphique. Pour revenir à nos unités de calcul et au titre de cette sous-section, un SM ADA comprend donc au total 128 unités FP32, mais il y a une subtilité dans leur implémentation, puisque la moitié d'entre elles doit partager (à l'instar d'Ampere) un chemin de données commun avec les unités en charge des entiers (INT32). Késako ?

 SM Ada Lovelace
SM Ada Lovelace
Un SM Ada Lovelace
Petit retour en arrière : avant Turing (Volta plus précisément, mais il n'y a pas eu de déclinaison grand public de cette microarchitecture), les unités FP32 partageaient le même accès au sous-système mémoire que les unités INT32. Durant l'exécution d'une instruction sur un entier, les unités en virgule flottante associées se tournaient donc les pouces en attendant. Nvidia a donc créé un second chemin de données (data path) sur Volta/Turing, pour permettre l'exécution concomitante d'une opération sur entier et virgule flottante. Cette possibilité permet d'après les études menées sur différents shaders (à l'époque) par le caméléon, d'augmenter de 36% le taux d'utilisation des unités FP32, ces dernières ne devant plus "laisser la place" aux INT32 lorsqu'il y a besoin de calculer un entier, chacun disposant à présent de son propre chemin de données.
Cette modification fût toutefois très coûteuse à mettre en place en termes d'accès à la bande passante mémoire, c'est pourquoi le caméléon s'est penché sur la possibilité de maximiser les gains liés à cette dernière. Puisque le chemin de données dédié aux INT32 est loin d'être saturé lors de l’exécution de shaders (36 % d'usage suivant les études citées précédemment), comment mettre à profit cette ressource potentielle ? La réponse a donc été d'ajouter sur Ampere, 64 unités FP32 au sein du SM, mais qui vont cette fois devoir partager le même chemin de données que les INT32 (à l'instar des CUDA Cores "pré-Volta" donc). Ada Lovelace reprend exactement cette structure.
C'est le sens de la représentation graphique (un peu plus haut) du SM, puisqu'il ne s'agit en rien d'une fusion d'unités, juste de la représentation graphique simplifiée d'INT32 et FP32 distinctes, mais partageant le même data path (le second bloc de FP32 disposant lui de son propre chemin de données dédié). Mécaniquement, le taux d'utilisation de ces 64 FP32 supplémentaires par SM, sera directement corrélé à celui des INT32, et comme les premières ont vu leur nombre total doublé par SM, alors la probabilité de sollicitation des secondes grandit en conséquence durant l'exécution de shaders. Tout dépendra donc des usages : si un programme donné n'a pas besoin de calculer d'entiers, alors le débit réel en flottants sera bel et bien doublé par cycle. Si par contre le besoin en entiers est significatif, alors le bloc de FP32 partageant le même chemin de données que les INT32, sera impacté en conséquence. Pour autant, cela n'a pas empêché Nvidia de communiquer le nombre total d'unités FP32 en tant que CUDA Core, alors que c'est un "rien" plus compliqué, comme nous venons de l'expliciter.
Shader Execution Reordering (SER)
Avant de s'attaquer aux nouveautés apportées aux RT Cores de 3ème génération, intéressons nous d'abord à l'autre nouveauté qu'introduit Nvidia au sein de ses SM pour améliorer les performances en Ray Tracing, à savoir le Shader Execution Reordering ou SER. En effet, le caméléon (mais aussi Intel via l'implémentation de ses Thread Sorting Unit au sein de ses Xe-Core, le pendant bleu des SM) est bien conscient qu'augmenter la puissance brute de ses RT Cores, n'est pas suffisant pour garantir des performances optimales avec du contenu faisant appel au Ray Tracing. En effet, les tâches liées au lancer de rayons peuvent être entravées par un certain nombre de facteurs.
Ainsi, les shaders dits divergents liés au RT, sont de plus en plus limitants à mesure que les chemins empruntés par les rayons deviennent de plus en plus aléatoires, lors des multiples rebonds ou lors de l'évaluation de matériaux complexes, affectant ces derniers. La divergence peut prendre deux formes : celle d'exécution, où les threads exécutent différents shaders (ou chemins de code au sein d'un même shader), et la divergence de données, où les threads accèdent à des ressources mémoire difficiles à fusionner ou à mettre en cache. Les deux types de divergence se produisent naturellement dans de nombreux scénarios de lancer de rayons et cela impacte fortement les performances, puisque les GPU fonctionnent plus efficacement lorsque le travail à réaliser est uniforme, permettant de le paralléliser au maximum. C'est là qu'entre en jeu le SER.

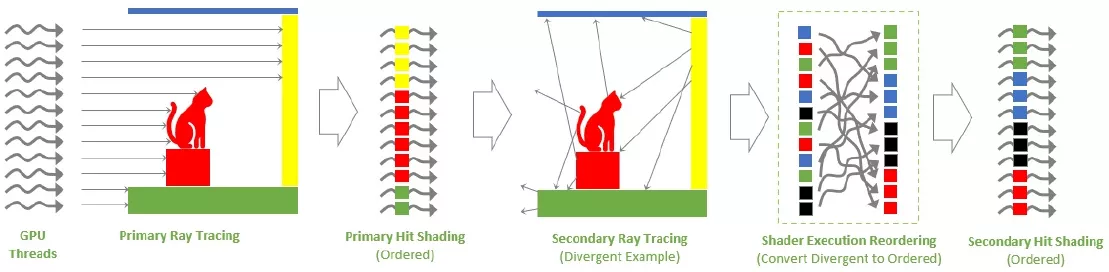 Principe SER
Principe SER
Le schéma ci-dessus montre un exemple simple de lancer de rayons. En partant de la gauche, un certain nombre de threads GPU projettent des rayons primaires dans une scène. Ces rayons frappant les objets suivent la même trajectoire: ils sont donc exécutés au sein du même shader, correspondant tout à fait au modèle d’exécution d’un GPU SIMT (Single Instruction, Multiple Threads = une instruction, une multitude de threads). Les difficultés commencent lorsque des rayons secondaires sont générés à chaque point d’impact d’un rayon primaire.
En effet, à partir des surfaces d’impact, les trajectoires divergent et cela va s’accroître au fur et à mesure des rebonds et de la complexité des surfaces touchées. Nous nous retrouvons alors avec un paradigme différent : plusieurs instructions pour plusieurs threads ! De ce fait, les shaders se multiplient, rendant leur exécution bien moins efficace par le GPU qui est une machine à paralléliser, calibré pour quelques shaders seulement, aux chemins de code homogènes. Le SER ajoute donc une nouvelle étape dans le pipeline de lancer de rayons, en réorganisant et regroupant le shading des rebonds secondaires, pour retrouver cette homogénéité si chère aux GPU pour assurer des performances optimales.
Si Intel indique qu'il a ajouté une unité dédiée à ces opérations en sortie des unités de lancer de rayons, Nvidia est bien moins loquace à ce sujet. Tout juste se borne-t-il a préciser que :
l'architecture matérielle Ada a été conçue avec SER à l'esprit et inclut des optimisations du SM et du système de mémoire spécifiquement ciblées pour une réorganisation efficace des threads.
OK, on est bien avancé avec ça, les verts utilisent peut-être une unité spécifique chargée de ces tâches à l'instar d'Intel, ou - plus vraisemblable au vu des communications de la GTC - ont inclus de nouvelles capacités aux ordonnanceurs déjà présents dans le SM, allez savoir. Un point intéressant et divergeant (au moins officiellement) entre bleus et verts se situe au niveau du fonctionnement du SER. En effet, sur Xe-HPG, l'unité dédiée semble autonome d'après Intel, c'est-à-dire qu’elle va réorganiser toute seule comme une grande les tâches, alors que du côté d'Ada, Nvidia évoque un processus bien différent :
SER est entièrement contrôlé par l'application via une petite API, permettant aux développeurs d'appliquer facilement la réorganisation là où leur charge de travail en profite le plus. L'API introduit en outre plus de flexibilité autour de l'appel des shaders liés au RT, permettant de mieux structurer les implémentations du moteur de rendu, tout en tirant parti de la réorganisation. De plus, nous ajoutons de nouvelles fonctionnalités au profileur de shaders NSight Graphics, afin d'aider les développeurs à optimiser leurs applications pour SER. Les développeurs peuvent ainsi utiliser les extensions NVAPI spécifiques à NVIDIA pour implémenter SER dans leur code. Nous travaillons également avec Microsoft et d'autres pour étendre les API graphiques standard avec SER.
L'approche des verts semble donc (là encore si on se base sur les annonces de part et d'autre) faire appel aux différents développeurs pour tirer parti au mieux de la fonctionnalité au sein des moteurs 3D. C'est indéniablement une grande force du caméléon, sa capacité à proposer aux différents développeurs un environnement logiciel leur facilitant la tâche, pour tirer le meilleur de son hardware spécifique, encore faut-il que ce boulot d'optimisation soit réalisé en pratique !
Des RT Cores améliorés
Turing avait marqué une rupture en étant la première architecture à inclure des unités dédiées à l'accélération matérielle du Ray Tracing ou plus précisément de l’algorithme BVH (Bounding Volume Hierachy). Ce dernier simplifie les calculs en procédant par dichotomie via l'utilisation de "boites" successives pour détecter rapidement (un parallélépipède rectangle étant une forme géométrique 3D très simple, le calcul des intersections est aisé), un impact entre un rayon et un triangle. 3 étapes peuvent être identifiées : intersection avec les boites, traversée de l'arborescence du BVH (passage d'une boite à des boites plus petites en son sein) et enfin intersection avec le triangle touché. Tous les GPU contemporains reprennent cette approche, mais l'implémentation diffère selon les concepteurs. Ci-dessous une image animée décrivant succinctement le fonctionnement du BVH.

 Principe du BVH
Principe du BVH
Ampère utilise de son côté des RT cores de seconde génération, disposant d'un débit doublé pour le calcul des intersections des rayons avec les triangles, ainsi qu'une unité accélérant l'application du flou cinétique lors des rendus. Avec ADA Lovelace, Nvidia double à nouveau le débit pour le calcul des intersections rayons/triangles, portant à 4 le facteur par rapport à la première itération des RT Cores (Turing) dans ce domaine.
Ensuite, les verts ont inclus aux RT Cores d'Ada, une unité capable d'effectuer les opérations Alpha (transparence) 2 fois plus rapidement. En effet, les développeurs utilisent fréquemment le canal alpha d'une texture pour découper sans consommer trop de ressources, des formes complexes, ou plus généralement pour représenter la translucidité. Une feuille peut ainsi être décrite à l'aide de quelques triangles, en utilisant le canal alpha d'une texture pour "détourer économiquement" la forme complexe. Il est également possible de faire une approximation satisfaisante d'une flamme complexe, par le biais de cette technique.

Jusqu'à présent, un développeur désireux d'incorporer ces types de contenu dans une scène utilisant le RT, devait les marquer comme non opaques. Lorsqu'une feuille est par exemple susceptible d'être touchée ou non par un rayon, un shader est appelé pour déterminer comment traiter l'intersection, et ce même si cette dernière se produit ou non, ce qui entraîne un coût non négligeable. Plus précisément, lorsqu'un groupe de rayons est projeté vers des objets non opaques, les requêtes de rayons individuels peuvent nécessiter plusieurs appels de shader pour être résolues, alors que certains rayons se terminent en fait immédiatement. Il en résulte de nombreux threads actifs persistants, et une inefficacité proportionnelle.
Pour améliorer cela, les ingénieurs de NVIDIA ont donc ajouté un moteur dénommé Opacity Micromap au RT Core d'Ada. Ce dernier, que l'on pourrait traduire par microcarte d'opacité, est un maillage virtuel de microtriangles, chacun avec un état d'opacité que le RT Core utilise pour résoudre directement les intersections de rayons avec des triangles non opaques. Plus précisément, les coordonnées d'une intersection sont utilisées pour adresser l'état d'opacité du microtriangle correspondant. 3 états sont possibles au sein de cette carte : opaque, transparent ou inconnu. S'il est opaque, un impact est enregistré et renvoyé. S'il est transparent, l'intersection est ignorée et la recherche d'une intersection se poursuit. S'il est inconnu, le contrôle est renvoyé au SM, qui va faire appel à un shader ("anyhit") pour résoudre l'intersection.

Ces mailles peuvent être dimensionnées d’un à seize millions de microtriangles, avec un ou deux bits associés à chacun d'entre eux. À titre d'exemple, la figure ci-dessus montre une feuille d'érable décrite à l'aide de deux triangles et d'une texture alpha. Sur le schéma, les zones transparentes sont blanches, la feuille n'est pas présente sur ces dernières. Celles vert foncé correspondent à des zones opaques de la feuille, enfin les rouges et bleus correspondent à des zones d'opacité mixte (inconnue). Le moteur Opacity Micromap marque ainsi 30 des microtriangles comme transparents, 41 comme opaques et 57 comme inconnus.

Cela signifie que plus de la moitié de la feuille est entièrement caractérisée et que plus de la moitié des rayons coupant ces triangles soit manquent la feuille, soit la touchent sans ambiguïté. Le RT Core d'Ada peut donc entièrement caractériser ces rayons sans avoir à invoquer le moindre shader pour cela, tout en préservant la pleine résolution et la fidélité de la texture alpha d'origine. Bien sûr, lorsque l'état est inconnu, il faut toujours faire appel à un shader pour sa résolution, mais leur nombre est largement réduit du fait de l'action préalable de l'Opacity Micromap Engine.
Dernier point d'amélioration des RT Core d'ADA, le Displaced Micro-Meshes ou DMM. La complexité géométrique continue d'augmenter à chaque nouvelle génération, toutefois, les performances lors du traçage des rayons sont faiblement impactées par cette dernière. Ainsi, dans une scène en Ray Tracing, une multiplication par cent de la complexité géométrique ne conduira qu'à doubler le temps de traçage des rayons. Cependant, la création de la structure de données (BVH) qui rend possible cette "petite" augmentation de temps lors du traçage nécessite elle un temps et une mémoire à peu près linéaires à l'augmentation de la complexité géométrique. Ainsi, 100 fois plus de géométrie pourra nécessiter jusqu'à 100 fois plus de temps pour créer le BVH et 100 fois plus de mémoire pour le stocker.
Les RT Cores de troisième génération intègrent donc le Displaced Micro-Meshes, afin d'aider à relever les deux défis consécutifs d'une complexité géométrique élevée : les performances lors de la construction du BVH et l'empreinte mémoire/stockage. Le stockage des Assets et les coûts de transmission de ces derniers sont également réduits. Voilà comment les verts définissent DMM :
Nvidia a développé le DMM comme une représentation structurée de la géométrie qui exploite la cohérence spatiale pour être compacte (compression) et exploite cette structure pour un rendu efficient avec un niveau de détail intrinsèque (LOD) et une animation/déformation légère.
Côté clarté on a encore une fois fait bien mieux. Il s'agit en fait de microgéométrie : lors des opérations faisant appel au Ray Tracing, la structure du DMM est utilisée pour éviter une forte augmentation des coûts de construction BVH (temps et espace), tout en préservant une traversée BVH efficace. Ainsi, lors des phases de rastérisation, le niveau de détails (LOD) intrinsèque au DMM, permet de rastériser les primitives de tailles adéquates via des Mesh Shaders ou Compute Shaders.
Ce crabe est composé de triangles de base représentés en rouge (à gauche), avec des détails géométriques supérieurs représentés par les micro-meshes (rouge également) à droite
Le DMM est donc en fait une nouvelle primitive géométrique, qui a été co-conçue par le moteur de microgéométrie inclus dans le RT Core de troisième génération. Chaque Micro-Mesh est définie par un triangle de base et une carte de "déplacement", contenant la valeur de ce dernier pour chaque microtriangle. Le moteur peut ainsi générer à la demande des microtriangles à partir de cette dernière, afin de résoudre les intersections entre les rayons et les Micro-Meshes, et ce jusqu'à atteindre le microtriangle touché par le rayon. La carte est façonnée de la sorte : les sommets des microtriangles constituent une grille barycentrique de puissance deux, et leurs coordonnées sont utilisées pour traiter directement les déplacements des micro-vertex.

Tensors Cores v4
À l'instar de l'architecture classique, Nvidia ne dévoile finalement que bien peu de choses concernant les Tensor Cores d'Ada. Pour rappel, ces derniers sont des cœurs de calculs spécialisés à hautes performances, qui sont adaptés aux opérations mathématiques de multiplication et d'accumulation matricielles, particulièrement utiles dans les applications IA et HPC. Ils peuvent donc à la fois servir pour l'apprentissage en profondeur des réseaux de neurones (Deep Learning), mais aussi pour les fonctions d'inférence, dont le DLSS est une des mises en œuvre les plus célèbres. Par rapport à Ampere, Ada fournit plus du double des TFLOPS FP16, BF16, TF32, INT8 et INT4 et inclut également le moteur Hopper FP8, offrant plus de 1,3 PetaFLOPS de traitement tenseur.
Un cache L2 gigantesque
Nous avons rapidement abordé le cache L2 lors de la présentation macroscopique de la microarchitecture, toutefois, Ada Lovelace mérite un paragraphe dédié à ce sujet. Pourquoi ? Eh bien tout simplement en raison du changement radical de philosophie ayant eu lieu à cette occasion. On passe en effet de 6 Mo sur les TU102/GA102, à pas moins de 96 Mo sur AD102, soit un facteur 16 entre ces générations. D'un point de vue organisationnel, ce cache L2 est toujours rattaché par partition à chaque contrôleur mémoire 32-bit, mais du fait de l'augmentation considérable de sa capacité, Ada permet à présent la désactivation d'une fraction de ce L2 connecté à chacun des contrôleurs, ce qui n'était pas le cas des microarchitectures précédentes. Mais au fait, pourquoi une telle inflation ? Probablement en raison de la stagnation de la mémoire vidéo. Certes, la GDDR6X gagne un peu en fréquence par rapport à celle intronisée sur Ampere, mais les puces les plus rapides sur RTX 40 se limitent pour l'heure à 22,4 Gbps (4080 16 Go), contre 21 Gbps pour la série 30 (3090 Ti). Un gain de 6,7 %, loin d'être comparable à celui qui intervient du côté de la puissance de calcul.

 Cache L2 faible
Cache L2 faible
 Cache L2 large
Cache L2 large
Augmenter ainsi considérablement le cache, va permettre d'amplifier la bande passante à destination des unités de calcul. Si les données nécessaires sont présentes en cache (et plus il est grand, plus il y a de chances que cela se produise), alors le débit ne sera plus celui de la mémoire, mais bel et bien celui du cache L2, infiniment plus rapide et moins couteux en énergie qu'un accès mémoire. À noter qu'AMD a visé le même objectif avec RDNA2, mais avec une approche légèrement différente. Au lieu de gonfler le L2, il a ajouté un niveau supplémentaire (L3 ou Infinity Cache sa dénomination marketing), unifié à tout le GPU.
Optical Flow Acceleration
Au cours des quatre dernières années, l'équipe NVIDIA Applied Deep Learning Research a travaillé sur un projet de génération d'images, combinant le DLSS avec une technique d'estimation du flux optique. Le but était de parvenir à un résultat visuellement satisfaisant, d'insertion d'images précises entre des images existantes, afin d'améliorer l'expérience de jeu en la rendant plus fluide. L'estimation du flux optique est couramment utilisée pour mesurer la direction et l'amplitude du mouvement apparent des pixels, entre des images graphiques ou des images vidéo rendues consécutivement. Dans les domaines des graphiques et de la vidéo 3D, les cas d'utilisation typiques incluent la réduction de la latence dans la réalité augmentée et virtuelle, l'amélioration de la fluidité de la lecture vidéo, l'amélioration de l'efficacité de la compression vidéo et la stabilisation de la caméra vidéo. Les utilisations via Deep Learning, incluent souvent la navigation automobile et robotique, ainsi que l'analyse et l'identification vidéo.

Le flux optique est plutôt similaire au composant d'estimation de mouvement utilisé en encodage vidéo, mais avec des exigences bien plus élevées en matière de précision et de cohérence. En conséquence, différents algorithmes sont utilisés. Depuis la microarchitecture Turing, les GPU du caméléon intègrent un moteur de flux optique autonome (OFA), c'est-à-dire fonctionnant de manière indépendante des Cuda Cores. Ces unités OFA sont capables de fournir jusqu'à 300 TeraOPS (TOPS) de travail sur le flux optique (plus de 2 fois plus rapide que les OFA de génération Ampère). Et c'est la que l'on en revient aux recherches de l'équipe mentionnée au paragraphe précédent, qui aboutissent à la création du DLSS 3, qui va en fait coupler le DLSS 2.0 utilisant l'inférence pour reconstituer une image en haute définition depuis une définition plus basse, à l'insertion d'images, générées cette fois depuis les données issues de l'OFA.
Moteur d'affichage et vidéo
Continuons notre tour d'horizon par le moteur d'affichage. Le port Virtual Link est malheureusement mort et enterré pour les verts, qui l'avaient pourtant introduit avec Turing. Pour rappel, ce dernier permettait de regrouper au sein d'un connecteur USB Type C, le flux d'affichage, de données et l'alimentation destinée aux casques VR. De nombreux acteurs de la VR étaient partie prenante de ce projet, pourtant aucun casque n'a vu le jour utilisant ce format. C'est une déception, une de plus dans l'univers de l'informatique, impitoyable pour certaines technologies. Toujours au rayon des déceptions, Nvidia n'a, contrairement à Intel ou AMD, pas intégré la norme Display Port 2.x, probablement jugée non nécessaire à l'heure actuelle, puisque le DP 1.4 convient parfaitement pour l'immense majorité des usages contemporains. Couplé au DSC 1.2a, il permet d'aller jusqu'à 8K en 60 Hz + HDR. Malgré tout, ce choix peut paraitre pour le moins surprenant, Nvidia aimant bien afficher un avantage technologique, il concède ici un retard flagrant sur la concurrence. Le HDMI 2.1, qui était déjà présent sur Ampere, est bien entendu toujours de la partie.
Passons à présent au moteur vidéo. Sur le front du décodage, Nvidia conserve ici la cinquième itération de son NVDEC, introduite avec Ampere et qui apportait le support plus que bienvenu de l'AV1. Ce codec, ouvert sans royalties à payer, permet de meilleurs taux de compression ou de qualité d'image que les H.264 et H.265 / HEVC / VP9. La contrepartie est une décompression très gourmande, pouvant mettre à genoux de nombreux processeurs en haute définition. Le décodage par le GPU permet de réduire à minima le taux d'usage du processeur central. Côté encodage, il y a cette fois du neuf à se mettre sous la dent, avec un NVENC qui passe à la génération 8 et assure l'accélération matérielle pour l'encodage AV1. Mais comme cela ne suffisait pas au caméléon, il a décidé d'en coller 2 au sein de la puce, de quoi réduire drastiquement les temps d'encodage, lorsque les logiciels seront en mesure de tirer parti de cette spécificité. Enfin, Nvidia affirme que son encodeur AV1 est 40 % plus efficient que celui H.264. Puisqu'un dessin vaut mieux qu'un long discours, voici un petit exemple fourni par le caméléon.

 Dual encoder AV1
Dual encoder AV1
Interface
Un petit mot pour finir, sur l'interface de raccordement au PC : alors que l'on pouvait s'attendre à une interconnexion en PCIe Gen 5, vu l'émergence des plateformes à cette norme l'année précédant ce lancement, il n'en est rien. Que l'on soit clair, encore plus que pour le DP 2.x, c'est loin d'être un problème, car d'ici à ce que les GPU saturent l'interface PCIe 4.0 x16, il va se passer encore un bon bout de temps. Est-ce un choix délibéré afin d'économiser des transistors, du budget puissance ou une finalisation du design préalable à la démocratisation de l'interface sur les plateformes grand public ? Quoi qu'il en soit, si cela n'impacte en rien les performances, l'utilisateur qui paie une petite fortune pour sa carte graphique, aime bien avoir les toutes dernières normes, ce ne sera pas le cas ici, même si c'est plus une question d'ordre psychologique qu'autre chose dans le cas présent et qu'il n'y a contrairement aux normes vidéo, pas mieux chez la concurrence à l'heure actuelle. Voilà ce que nous pouvions vous dire sur Ada Lovelace, passons à sa contrepartie bleue, page suivante.




Merci pour ce gros test !
Super boulot ! Merci ! Les explications de fonctionnement sont super informatives.
Je pourrai abuser et demander l'ajout de la gamme en dessous : une 3060, une 4060, une 6600 de chez dédé ? ou tout du moins l'une d'elle ? :oS
Sinon ce serait super d'avoir une représentation des résultats en 3D (interactive ?) x: perf synthétique sur les 20 jeux, y: nuisance sonore, z: conso ... bon pi quand les humains auront évolué pour le percevoir, un 4ème axe "prix" ça serait au poil :D car c'est un peu de cette optimisation que chacun prend sa décision d'achat ;) Et ça serait marrant de voir des gros outliers sortant du lot.
Alors non, désolé et ce pour une raison simple : ces cartes ne sont pas adaptées du tout pour les définitions et réglages sélectionnés pour ce dossier. Même parmi l'échantillon de test, certaines références se retrouvent dans une situation inconfortable parce qu'elle ne sont pas utilisées dans leur plage adaptée (principalement en UHD). Le souci, c'est que cela conduit à une hiérarchie pour ces cartes qui n'est pas pertinente (parce que structurellement (plus de VRAM, de ROP, etc.) la référence A serait moins limitée que la référence B dans ces conditions qui ne font pas partie de leur plage nominale et ce même si cela ne rend pas le réglage jouable pour autant) et qui pourra induire en erreur le lecteur qui se contente de regarder l'indice moyen (et il y en a bcp).
C'est pour ça que je suis contre les plages de références trop larges du fait de ce biais. On pourrait le contourner partiellement en rajoutant le FHD en plus des QHD/UHD, mais d'une part cela va multiplier de manière conséquente la durée des mesures (et le risque qu'une nouvelle version de pilotes ou un patch de jeu sorte obligeant à reprendre toutes les cartes déjà testées), et d'autre part la pertinence retrouvée via cette nouvelle définition pour ces cartes entrainera aussi une absence de pertinence (pour cette même définition) pour certaines autres références qui pour le coup vont être totalement limitées par le CPU et se tourner les pouces rendant la hiérarchie biaisée à nouveau même si pour d'autres raisons. Nous avons toutefois réalisé d'autres dossiers où l'on retrouve des références communes qui permet d'extrapoler quelque peu le positionnement des références demandées.
Nos graphs dynamiques ne permettent pas de folie de ce genre pour le moment, mais probablement un type radar à l'avenir. Par contre les nuisances sonores sont fortement liées à la version choisie : on ne peut pas inférer ce que sera le niveau d'une Asus, Gigabyte, MSI, etc. en se basant sur la prestation à ce niveau de la carte de référence.
Pour ça il y a nos guides d'achat, ils vont être remis à jour prochainement.
Ça c'est du test de qualité (et de quantité) non de diou ! Merci Riton pour l'investissement !
Je me suis régalé en page 2 3 4, c'est tellement bien détaillé !
Merci pour le test Eric, comme d'hab' au top!
Content que ça t'ait plu 😉