
Battlemage
Le 05 octobre 2022, Intel levait le voile sur sa série de cartes graphiques ARC A700. Ce n'était certes pas la première itération (pour carte graphique) de l'architecture Xe (nom de code Alchemist) développée depuis des années sous la houlette de Raja Koduri, puisque l'ARC A380 destinée à l'entrée de gamme avait été lancée en catimini durant l'été précédent. Mais l'annonce officielle eut lieu à l'occasion du lancement des premières cartes graphiques (de l'ère récente) réellement destinées aux joueurs, les Arc A750 et A770. Le résultat, bien qu'encourageant, montrait tout de même de sérieuses limitations de l'architecture. En effet, il était nécessaire pour Intel d'utiliser une puce bien plus dispendieuse en matière de transistors, pour arriver grosso modo au niveau des RTX 3060 / RX 6600 concurrentes. Ajoutez à cela un lancement juste avant les nouvelles générations vertes et rouges, vous comprenez la situation très délicate de ces Arc originelles.
Pour la nouvelle génération, elle va devoir aussi affronter de nouvelles générations tant chez AMD que NVIDIA, la situation ne change donc pas à ce niveau. Par contre, là où il fallait une puce "G10" pour parvenir à la parité avec les "séries 6" de ses concurrents, Intel indique y parvenir ici avec la puce "G21", soit la plus petite des deux (si la nomenclature ne change pas). Nuançons tout de même ces assertions, puisque ACM-G11 équipant les Arc A380 se contentait d'un die de 157 mm² gravé par TSMC via son N6, alors que son successeur logiquement nommé BGM-G21 est beaucoup plus gros, avec 272 mm² en N5. Il croît donc de 73 % malgré l'utilisation d'un procédé de gravure plus dense. De quoi loger pas moins de 19,6 milliards de transistors en son sein, soit 2,7 fois plus. Autant dire que les ambitions d'Intel avec cette nouvelle génération de puces sont toutes autres. Pour illustrer tout cela, quoi de mieux qu'une représentation du die ?

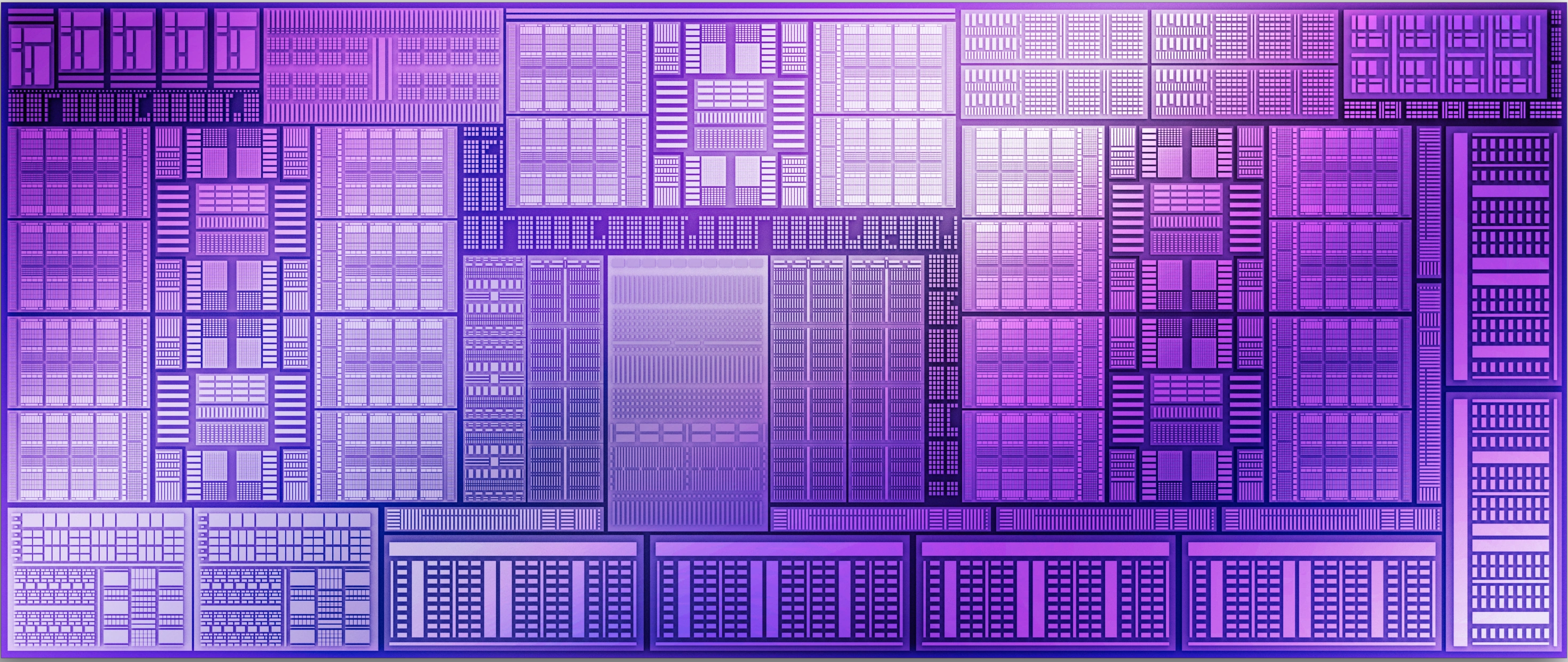 Die BMG-21
Die BMG-21
La représentation visuelle du die de BMG-G21
Xe2
Côté microarchitecture, nous vous invitons à lire ou relire notre page dédiée à Alchemist pour appréhender plus aisément les changements. Débutons par une vue macroscopique et schématique de BMG-G21. Comme tout bon GPU moderne, il dispose d'un processeur de commande central chargé d'ordonner et affecter les différentes tâches aux unités de traitement. Avant de détailler ces dernières, précisons qu'il utilise une interface PCIe composée de 8 lignes de 4ème génération pour le raccordement au CPU. On va également trouver le moteur d'affichage, le media engine (traitant le décodage/encodage vidéo) et le sous-système mémoire. Nous vous en dirons un peu plus sur les deux premiers cités en fin de page, pour nous concentrer à présent sur le dernier.
Tout d'abord, le cache de niveau 2 centralisé se compose de 6 partitions de 3 Mo, pour un total de 18 Mo. Il est totalement dissocié des Render Slices (cf. plus bas), ce qui autorise une plus grande flexibilité au niveau de son activation partielle. Aini, le GPU chargé d'animer la "petite" B570 ne dispose que de 13,5 Mo de L2, du fait de la désactivation de 768 Ko par partition. Les contrôleurs mémoire 32-bit sont associés à des puces GDDR6 (19 Gbps) de 2 Go. Ils sont au nombre de 6 pour une largeur total du bus mémoire à 192-bit. A nouveau, le GPU dédié à la plus petite des deux cartes lancées est amputé, via la désactivation d'un contrôleur pour un bus ramené à 160-bit. Mécaniquement, une puce GDDR6 sera supprimée, réduisant d'autant la VRAM embarquée sur la carte.

 Diagramme de blocs BMG-G21
Diagramme de blocs BMG-G21
Xe2 (la précédente µarchitecture se nommant Xe-HPG) s'articule toujours autour de blocs multifonctions appelés Render Slice et qui correspondent grosso modo aux GPC chez NVIDIA et Shader Engine d'AMD. Ces derniers incorporent toute la partie Compute (calcul), mais aussi le texturage, la géométrie (génération de triangles, tessellation, etc.), les unités de rastérisation (décomposition des triangles en pixels) et enfin les ROP qui effectuent le rendu final (écriture en mémoire). Les bleus indiquent avoir doublé le débit brut en texturing (sans filtrage), tandis que ces TMU (nommées ici Sampler) sont à présent capables d'effectuer un échantillonnage Out Of Order.
Pour la géométrie, le débit en Vertex (sommets) et l'exécution du Mesh Shading sont triplés. Nous mettrons bien entendu à l'épreuve ces assertions à l'aide des tests synthétiques dédiés. Côté rastérisation, on notera un accroissement de 50 % du cache HiZ / Z / Stencil et une éjection (Culling) précoce (ne nous faîtes pas dire ce que nous n'avons pas écrit) des triangles avant rendu s'ils ne sont pas visibles sur l'image à calculer. Finissons avec les unités de rendu ou ROP (Render Output Unit qu'Intel nomme ici Pixel Backend) qui disposent à présent d'un tampon pour la couleur des pixels plus grand (+ 33 %) et qui doublent également leur débit brut en Blending.

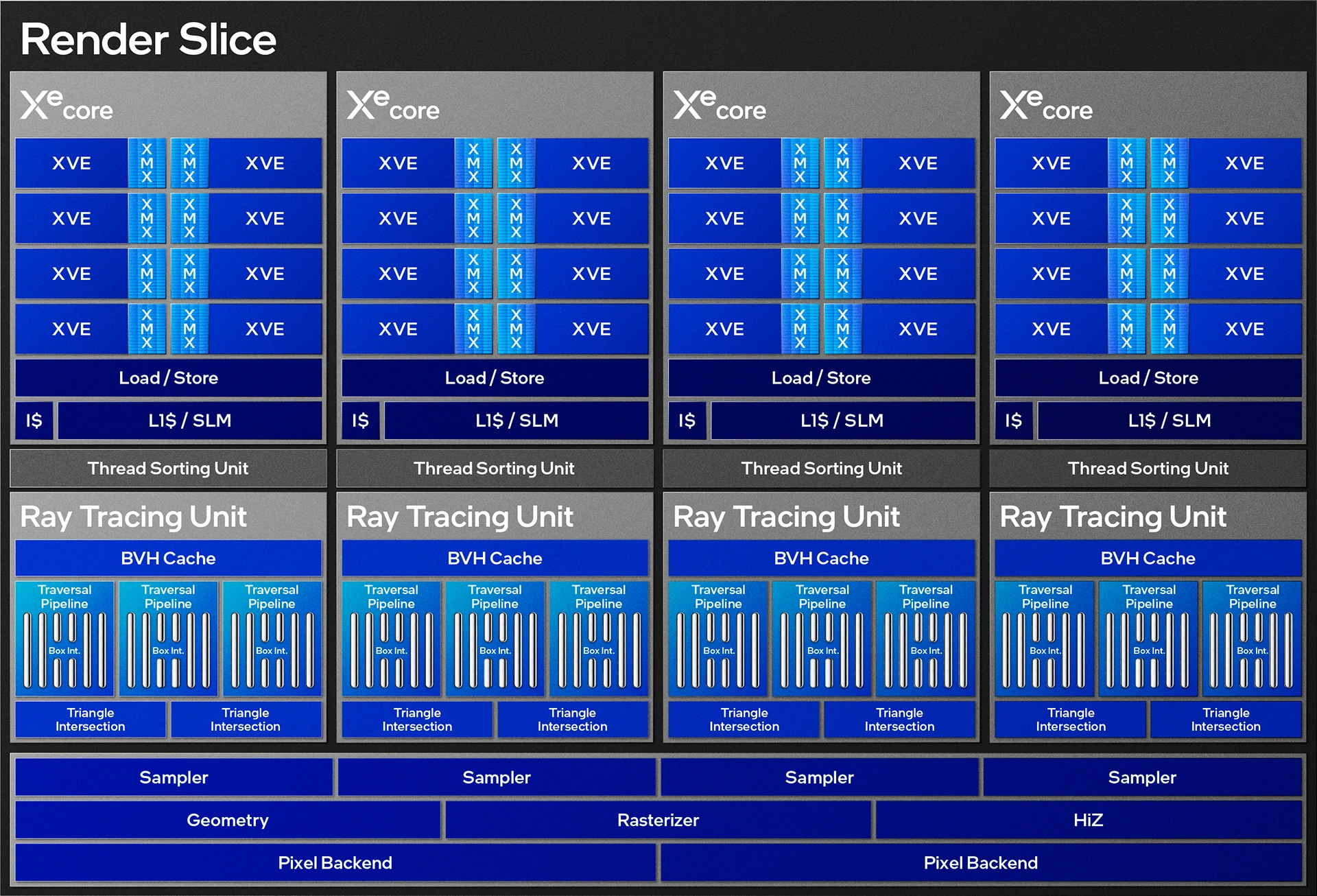 Render Slice BMG-G21
Render Slice BMG-G21
Jetons à présent un petit coup d'oeil aux Xe-cores, ressemblant vaguement aux SM/CU des concurrents. Chaque Xe-core est constitué de 8 unités matricielles XMX, d'unités de chargement / stockage couplées aux L1 / mémoire partagée ainsi qu'au cache dédié aux instructions. A cela s'ajoutent 8 Vector Engines intégrant les unités de calculs "élémentaires" ou ALU. L'organisation de ces dernières a été repensée, puisqu'à présent de type SIMD16 (Single Instruction Multiple Data à 16 voies) au lieu de SIMD8 sur Xe-HPG. En fait, les Vector Engines étaient sur Alchemist agencés par "couple" de SIMD8 partageant une partie de la logique de pilotage. Au sein de Battlemage, ce duo est à présent totalement fusionné en une seule "grosse" unité.
L'intérêt selon Intel, est de revenir à une granularité davantage usitée dans les jeux, évitant ainsi à l'équipe en charge des pilotes, de devoir "optimiser à la main" les shaders pour tirer parti des spécificités de l'architecture. À noter également le support des opérations en SIMD32 par association de 2 Vector Engines. Le cache L1 et la mémoire locale partagée sont toujours unifiés, mais la capacité totale passe de 192 Ko à 256 Ko (+33 %). Toutes ces évolutions ont d'après Intel un impact majeur sur l'exécution de certaines tâches et conduiraient à des gains de performance allant jusqu'à 70 % pour les Xe-cores de seconde génération par rapport à la version originelle. L'efficacité énergétique ne serait pas en reste, avec une progression de 50 %.





Les unités matricielles XMX (équivalent des Tensor Cores de Nvidia) ont été musclées pour doubler leur débit. Intel ne précise toutefois pas si ce débit inclut ou non une notion de sparsité (matrice creuse). Quoi qu'il en soit, chaque XMX se voit appairé à un Vector Engine : on en retrouve donc 8 par Xe-core, ce dernier pouvant délivrer 4096 opérations INT8 et 2048 en FP16 par cycle. L'IA est donc une composante priorisée par Intel, nous y reviendrons un peu plus bas concernant les avancées logicielles basées sur cette dernière.
Le Ray Tracing est une autre priorité des bleus. Pour rappel, AMD et Intel ont repris l'approche de Nvidia consistant en une accélération du BVH. L'implémentation au sein d'Alchemist s'était montrée plutôt efficace, mais Intel ne se repose pas pour autant sur ses lauriers en augmentant significativement la puissance brute de ses unités avec Battlemage. On parle ici de gains allant de 50 % à 100 % selon les tâches par rapport à la génération précédente. Le cache dédié au BVH est également doublé, à 16 Ko en tout.


Quid du Media Engine à présent ? Il reprend la structure de celui équipant les ACM-G10/11, à savoir un double MFX intégrant simultanément un encodeur et un décodeur. Il est donc possible de décoder un flux vidéo via un MFX et d'encoder avec le second ou toute autre configuration (double encodage ou double décodage). Au niveau des codecs supportés, pas de manque notable à ce sujet puisque dès Alchemist, l'AV1 avait été intégré à la fois pour le décodage et l'encodage. Concernant ce dernier, Intel indique tout de même une nouveauté pour Battlemage, à savoir la prise en charge du SCC (Screen Content Coding) améliorant la qualité visuelle à bitrate équivalent.



Finissons notre tour d'horizon architectural par le moteur d'affichage. Intel ne fournit malheureusement pas de représentation schématique du moteur d'affichage intégré à BMG-G21 et ce n'est pas en extrayant celle présente sur le diagramme de blocs que l'on va être davantage avancé. Nous pouvons toutefois extrapoler quelque peu en se basant sur la version incluse à Lunar Lake (que nous avons ajoutée ci-dessous), relativement proche même si des différences existent. La première consiste en la présence de 4 pipelines d'affichage sur ce GPU dédié, contre seulement 3 flux pour la version mobile. Cette dernière dispose également d'une sortie eDP sans intérêt pour la version de bureau, qui se contente uniquement des classiques DisplayPort et HDMI.


Avant de passer à la partie logicielle, voici résumé dans le tableau ci-dessous les définitions permises par ce moteur d'affichage et ce par port. En comparaison d'Alchemist (DP 2.0), la norme DisplayPort 2.1 est prise en charge. Toutefois, il existe trois variantes/options possibles pour cette dernière : 10 Gbps (UHBR10), 13.5 Gbps (UHBR13.5) et 20 Gbps (UHBR20). Intel a opté pour l'UHBR13.5 pour un des 3 flux DP, les deux autres se limitant vraisemblablement à l'UHBR10.
| Port | Norme | Définitions maximales supportées |
|---|---|---|
| DisplayPort (primaire) | DisplayPort 2.1 (UHBR13.5) |
7680 x 4320 @ 60 Hz |
| DisplayPort | DisplayPort 2.1 (UHBR10) |
7680 x 4320 @ 60 Hz 7680 x 2160 @ 165 Hz 5120 x 2160 @ 240 Hz 3840 x 2160 @ 240 Hz |
| HDMI | HDMI 2.1a | 7680 x 4320 @ 120 Hz 3840 x 2160 @ 480 Hz |
XeSS2
XeSS2 est une évolution significative de la version originelle, et il ressemble comme 2 gouttes d'eau au DLSS 3. En effet, on retrouve la composante initiale, à savoir l'upscaling matiné d'IA nommé XeSS-SR (Super Resolution), à laquelle s'ajoute à présent une Frame Generation (XeSS-FG), ainsi qu'un mécanisme de réduction de la latence afin de contrebalancer l'effet négatif à ce niveau de l'insertion d'image. Les bleus nomment celui-ci XeLL (Low Latency), il s'agit donc du pendant de Reflex (Nvidia) et AntiLag (AMD). A noter également qu'Intel fournit à présent un SDK pour DX11 et Vulkan en sus de DX12, ce qui devrait permettre d"élargir encore davantage le périmètre des jeux le prenant en charge.



La Frame Generation utilise finalement un principe de fonctionnement calqué sur celui de ses concurrents (avec quelques spécificités), alors qu'Intel envisageait un temps une extrapolation de l'image générée. Les bleus n'ont pas jugé utile d'ajouter des unités dédiées à l'analyse du flux optique comme NVIDIA peut le faire, et préfèrent utiliser un algorithme IA s'appuyant sur les unités XMX pour cette opération. Seconde source d'interpolation (ou reprojection comme le nomme les bleus), les vecteurs de mouvement issus du moteur de jeu. Les résultats obtenus via ces deux options sont ensuite insérés dans un second algorithme IA, et c'est lui qui va inférer au mieux l'image à insérer grâce à ces deux composantes.


Reste à voir en pratique quelle sera la qualité visuelle réellement atteinte (artefacts potentiels, Frame Pacing, etc.), sachant qu'une dizaine de jeux devrait l'inclure sous peu (F1 24 est déjà mis à jour pour le XeSS 2, AC Shadows et Dying Light 2 devraient suivre pour les plus connus). En attendant de pouvoir se faire une idée plus précise de la chose, Intel propose une petite vidéo illustrant les explications textuelles précédentes. Cette dernière couvre les opérations d'upscaling (Super Resolution) et de Frame Generation.
XeLL fonctionne de son côté de manière identique aux technologies équivalentes des rouges et verts, à savoir via synchronisation des files de rendu d'images côté CPU et GPU. La technologie devra donc être intégrée directement au jeu pour fonctionner de manière optimale. Intel propose toutefois une option au niveau des pilotes, probablement du fait du retard conséquent sur Nvidia côté implémentation au sein des titres. A voir toutefois le résultat puisqu'AMD confronté à ce même retard avait lui aussi opté pour une telle solution, et a connu de sérieux déboires conduisant au bannissement de certains joueurs accusés de tricher après activation de ladite option ! Espérons qu'Intel s'est assuré d'éviter cet écueil.




Puisqu'on parle des pilotes, l'interface de ces derniers a été clairement améliorée, vous pouvez retrouver quelques clichés en fin de page suivante. D'un point de vue logiciel, Intel pousse en tout cas très fort pour rattraper son retard dans le domaine de l'IA, qui comporte à présent de nombreux domaines d'application. A voir si cette stratégie sera couronnée de succès et parviendra à déloger quelque peu Nvidia de son piédestal, histoire de profiter de la manne financière qui est actuellement drainée par cette nouvelle ruée vers l'or (qui a surtout profité aux vendeurs de pelles).






Il est à présent temps de passer à la description de la carte testée ce jour page suivante.




tout n'est pas parfait mais son avantage de vram lui donne beaucoup d'intérêt dans cette gamme de prix
très bon test comme d'habitude
le fonctionnement du mode turbo est spéciale je suis sur que la carte pourrait grapiller des mhz avec un fonctionnement plus comme amd/nvidia
Par contre j'ai fini vraiment à l'arrache, donc désolé s'il y a des fautes/typos/coquille, on va corriger une bonne partie de cela dans les heures qui viennent.
je dis ça pas parce que Eric est un ami, mais ses tests sont une tuerie complète et tellement riches d'enseignements, ils servent de base dans mes connaissances 😊
je viens de lire plus en detail l'article si on écoute le descriptif on croit que la b580 a un die complet et le b570 un die castré
de se que j'ai compris la b580 a aussi un die castré mais je me trompe peut être
Intel ne l'a pas précisé, mais si tu regardes bien la représentation du die en page 2, tu distingues facilement les 5 Render Slice (20 Xe Engine) et 6 contrôleurs mémoire, pas un de plus. Donc il semble bien que le die soit complet.
J'avais vu passer que les 5 render slice c'était bizarre et que du coup il y en aurait 6 mais ton explication tient la route
Mais du coup le côté faible densité en prend un coup j'ai cru que le die avait réellement un bus 256 bits
Ils ont pour moi en tout cas chier dans la colle sur ça
Après ont sait que avec les unités xmx prennent beaucoup (trop ?) de place et qu'il faut un plus gros die pour être équivalent à amd/nvdia mais la c'est peu abusé
J'ai aucune certitude, mais c'est ce qui me semble le plus probable. De toute façon lorsque tu poses la question à Intel (ou aux deux autres) la réponse est toujours la même : "nous ne communiquons jamais sur des produits ou fonctionnalités non annoncées" donc il y a toujours un doute.
L ia chez intel sert à quoi à par le xess ? Pas grand chose il me semble
Il faut des unités ia mais je trouve ça surdimentionné
Les arcs ne sont même pas décliné en secteur pro il me semble
Il ne faut pas oublier aussi que la densité est très étroitement liée à la maîtrise / expérience du procédé de gravure... ce qui passe par l'expertises des outils de conception. Avec Intel qui débarque tout juste chez TSMC - qui plus est avec des GPU qui ne sont pas sa spécialité -, face à un NVIDIA et AMD rompu à la tâche car fabless, c'est compliqué. Il est aussi possible que Intel avait des buts plus agressifs en matière de fréquence, et a initialement designé la puce avec des transistors moins denses mais plus susceptibles de monter en cadence.
Merci pour le test, c'est encourageant pour intel, mais ça arrive beaucoup trop tard et trop cher chez nous.
330€ ce serait plus cher que certaines RTX 4060. Alors certes elle est censée être mieux (hors consommation), mais l'image de marque de NVIDIA est forte.
Si on suit le taux de change + TVA, 250$ c'est moins de 290€, donc à voir si ça va baisser dans les prochaines semaines.
🙏
Comme d'hab', le master des testeurs fr a pondu le meilleur test fr, plein/trop d'info' mais " vulgarisé" , pour un néophyte comme moi qui passe son temps a jouer.. ok je m'égare hihi.
Plus sérieusement, en toute franchise elle a bcp de potentielle, faut voir une fois les pilotes matures ( Intel l'a prouvé avec Arc), son écosystème évolue aussi,
Loin d'être ridicule.
Mais son prix fr va peut être freiné, c'est chère Payé.. et aussi sa conso pas énorme mais face a la 4060...
Merci Éric pour ce test et ces pavés ! On adore!
Un peu moins quand même hein ! 😅 Je suis juste un gars passionné qui est tombé il y a très longtemps dans l'informatique et qui essaie simplement de faire les choses sérieusement. Ma prétention s'arrête à ça et c'est déjà beaucoup vu les biais et erreurs qui peuvent survenir sur chaque test, surtout quand tu es contraint par le temps disponible du fait d'une activité parallèle.
Et en plus il a de l'humilité comme personne !!
☺️
C'est ta passion qui anime ce genre de ticket, de façon factuelle et impartial, n'en déplaise a certains ( et certains sites putacliks)
Merci, toujours un plaisir de te lire, de VOUS lire!