
Alchemist (ARC XE-HPG)
À l'instar de ses 2 compères concevant des GPU pour les PC grand public, Intel introduit tout un vocabulaire lié à ses technologies. Ainsi, la microarchitecture utilisée pour cette première fournée de GPU, porte le doux nom de Xe-HPG, nom de code Alchemist. Pour décrire la microarchitecture des bleus, nous allons débuter à nouveau par une vue macroscopique de l'organisation de son plus gros GPU, aka ACM-G10. Sans surprise, il ressemble fortement à ce que l'on peut trouver chez la concurrence. Ainsi, un processeur de commande (Global Dispach) est chargé d'ordonner et affecter les tâches aux différentes unités de calcul du GPU. Avant de détailler ces dernières, faisons un peu le tour des principaux éléments connexes, à savoir l'interface PCIe (x16 Gen 4.0) pour le raccordement au CPU, le Display Engine chargé de l'affichage et le Media Engine en charge des tâches d'encodage/décodage vidéo. Nous reviendrons également sur ces 2 derniers éléments en fin de page. Viennent ensuite la mémoire cache L2 d'une capacité totale de 16 Mo, et les 8 contrôleurs mémoire 32-bit, permettant un adressage à 256-bit de la GDDR6.

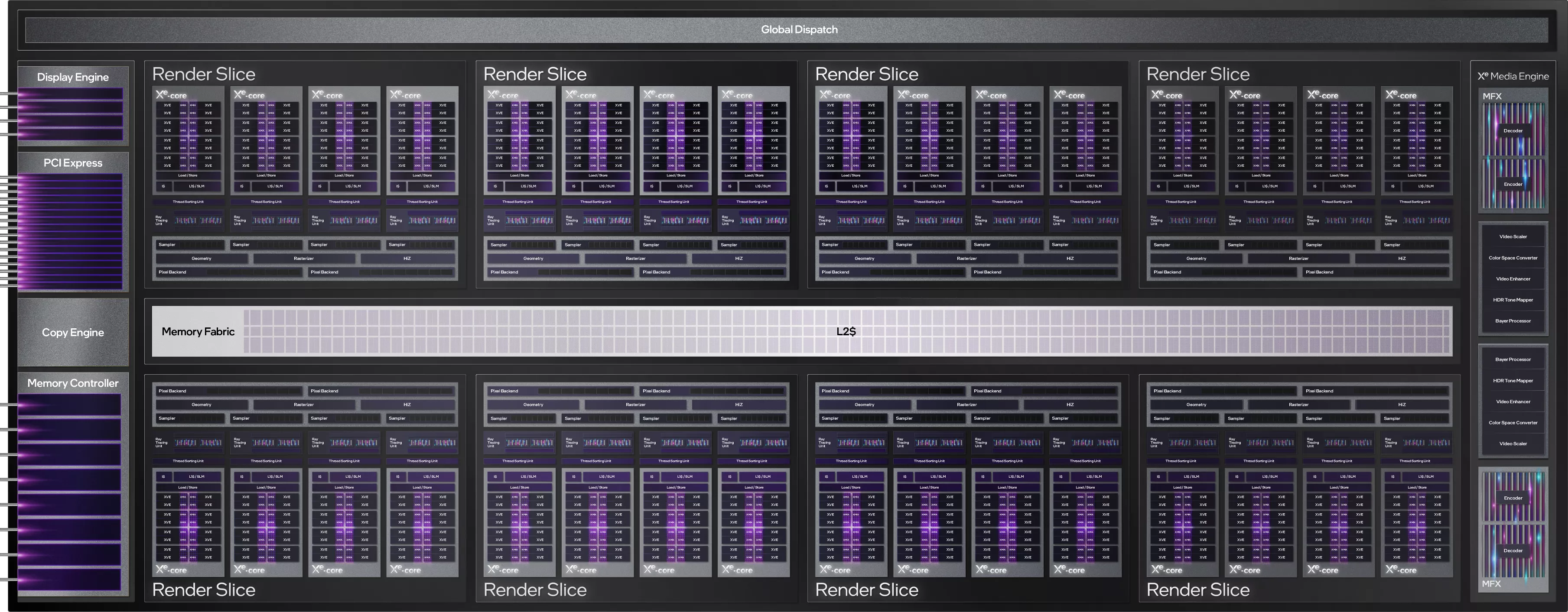 Diagramme de bloc ACM-G10
Diagramme de bloc ACM-G10
ACM-GA10 dans sa version intégrale
Une organisation similaire à ses concurrents
À l'instar des GPC sur les GPU verts, Intel propose ici des Render Slice (8 maximum sur ACM-GA10), une structure regroupant les unités de géométrie (en charge de la génération des triangles, mais aussi de la tessellation, etc.), de rastérisation (découpe des triangles en pixels), de texturing (nommées sampler ici, 32 par Render Slice pour un total de 256), Hierachical Z (éjection (Culling) des triangles qui ne seront pas visibles), mais aussi les ROP (nommés Pixel backend, 16 par Render Slice soit 128 au total) et bien entendu les unités dédiées au Ray Tracing ainsi qu'aux différents calculs, que nous allons à présent détailler.

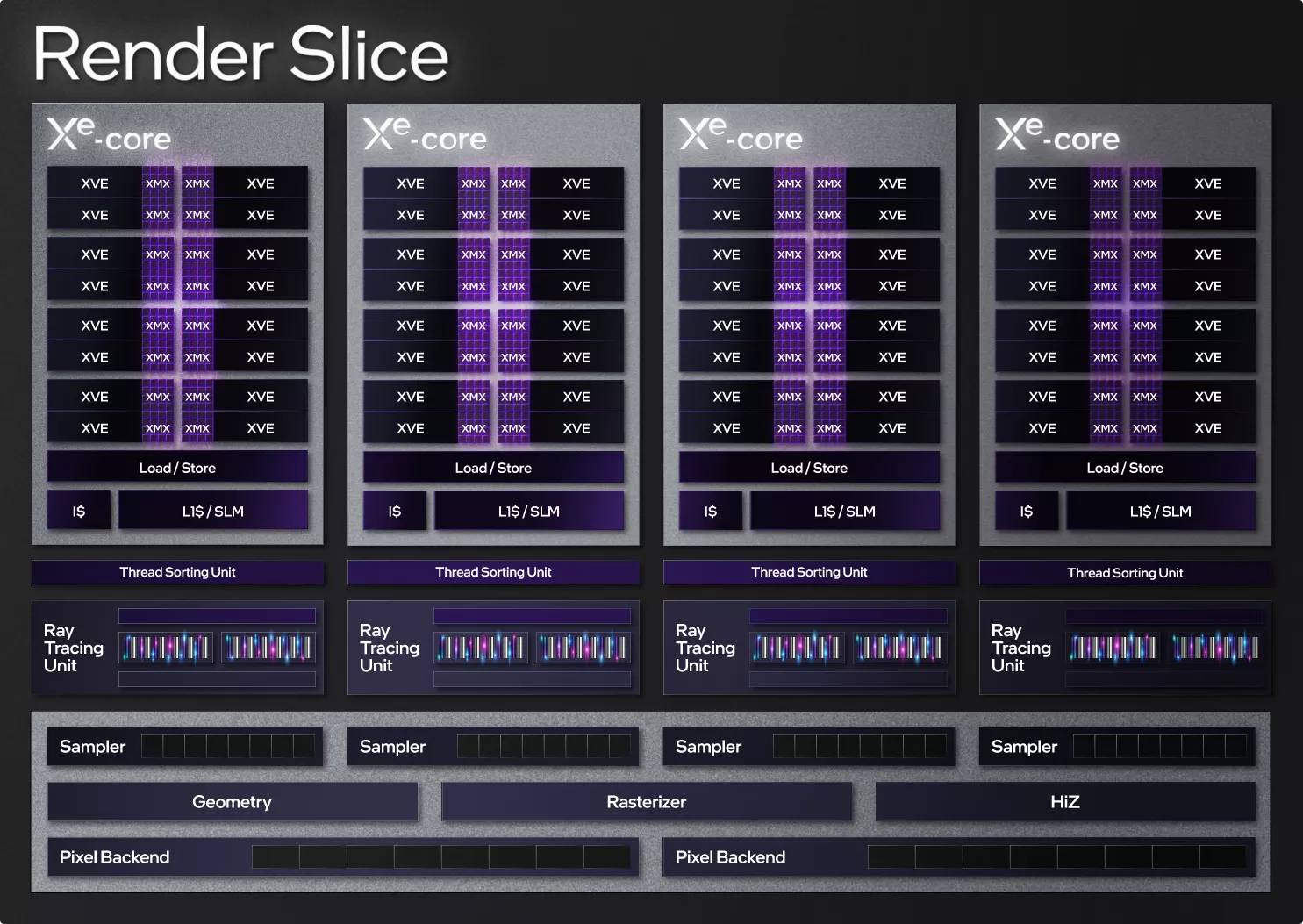 Render Slice
Render Slice
Render Slice Xe HPG
Au sein des Render Slice, se trouve ce qu'Intel nomme les Xe-Core, au nombre de 4. En poursuivant l'analogie avec l'organisation des GPU concurrents, les structures similaires seraient les SM (Streaming Multiprocessor) côté vert ou CU (Compute Unit) côté rouge. Ce Xe-Core se compose de 16 unités vectorielles (Xe Vector Engine, comprenant 8 SP (FP), 8 INT et 2 EM (opération complexe = SFU sur GeForce). À noter que les entiers et opérations complexes (sin, cos, etc.) ne peuvent pas être exécutés simultanément (soit l'un soit l'autre). Au sein du Xe-Core, sont également présentes des unités matricielles XMX (16 également), que l'on pourrait cette fois comparer aux Tensor Cores du caméléon et que nous détaillerons également un peu plus loin. À cela s'ajoutent bien entendu les registres d'instructions, ainsi que le cache L1 et la mémoire locale partagée (192 ko en tout pour ces 2-là).

 Xe Core
Xe Core
Le Xe-core, la structure de base d'Alchemist
Des unités de calcul tout-terrain
À l'instar d'AMD avec ses WGP ou plutôt Dual CU / Compute Unit Pair, puisque ce sont les dernières terminologies adoptées par les rouges pour ces derniers, les Xe Vector Engine fonctionnent par paire. Est-ce dû au fait que Raja Koduri a été le superviseur de ces deux architectures ? Quoi qu'il en soit, c'est une similitude notable. Contrairement à Nvidia qui intègre ses unités matricielles au sein du SM, ce n'est pas le cas ici, tout du moins la représentation qui en est faite (et qui est souvent une simplification d'organisations bien plus complexes) avec les unités XMX en dehors des Xe Vector Engines, mais bel et bien interconnectées à ces derniers. Le point important à noter concerne les capacités de cet ensemble, pouvant traiter simultanément une instruction sur flottant, entier (ou fonction spéciale) et matriciel.

 High Performance Engine
High Performance Engine
L'organisation des unités de calculs
En termes de débit, les XeVector Engine sont capables de réaliser soit 16 opérations FP32, soit 32 en demi-précision (FP16) ou encore 64 INT8 par cycle d'horloge. Intel indique d'ailleurs une gestion très efficace des différents threads, les tests pratiques mettront à l'épreuve cette assertion.

 Xe Vector Engine
Xe Vector Engine
Les Xe Vector Engine
L'IA n'est pas oubliée
Petit zoom à présent sur les unités XMX. Ces dernières sont capables de réaliser des opérations de multiplication-addition en précision mixte sur une matrice. De quoi atteindre des débits très importants en faible précision, dont l'IA est friande en particulier pour les tâches d'inférences.

 Les unités XMX d'Alchemist
Les unités XMX d'Alchemist
Les unités XMX d'Alchemist
Intel indique ainsi que pour des calculs INT8, la vitesse de traitement peut être multipliée par 16 par rapport à une unité de calcul traditionnelle, en utilisant ses unités matricielles XMX. À l'instar du caméléon qui a développé le DLSS en s'appuyant sur ses Tensor Cores, les bleus proposent leur propre technique d'upscaling (XeSS), mais ouverte aux cartes de la concurrence à contrario de la solution verte. Cet upscaler peut s'appuyer sur l'inférence, par contre pour des raisons de compatibilité avec les différents GPU, les performances et la qualité visuelle obtenue varieront selon le type d'unités capables d'en faire le traitement. Ainsi, il n'y a en réalité pas un mais des XeSS, selon que ce dernier soit exécuté sur un hardware Intel ou celui d'un autre concepteur.

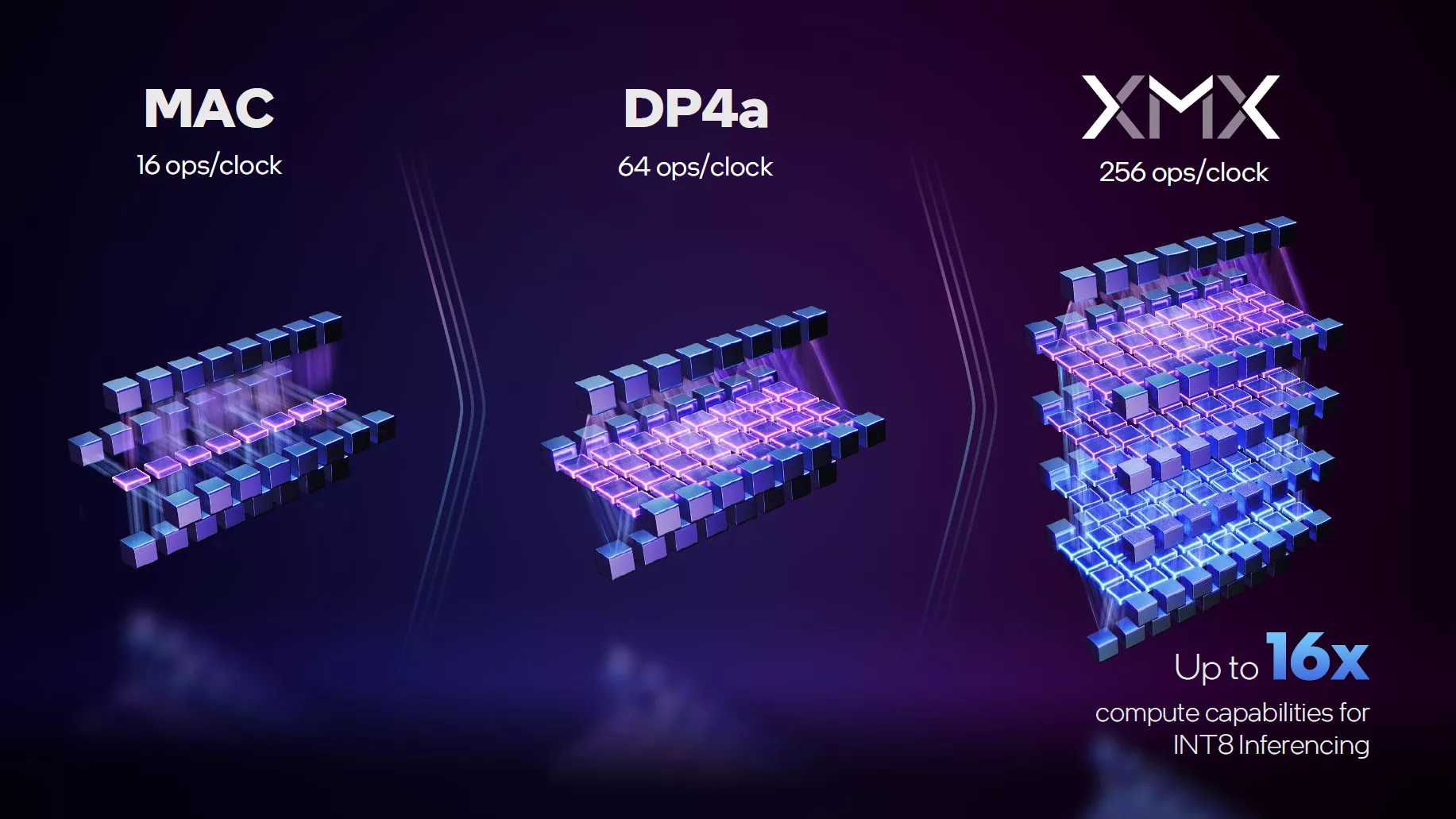 Les capacités de traitement des unités XMX
Les capacités de traitement des unités XMX
Les performances des unités XMX
Une gestion du Ray Tracing très poussée
Passons à présent aux capacités en Ray Tracing de ce nouveau GPU. Pour concurrencer NVIDIA qui est pour l'heure le champion incontesté dans ce domaine, les bleus ont développé un accélérateur de BVH prenant en charge les 3 étapes (voir page précédente pour plus de détails) et disposant d'un cache dédié spécifiquement à cette technique. Une unité annexe est également présente au sein du Xe-Core, afin de gérer l'ordonnancement des tâches liées au Ray Tracing.

 Pipeline graphique optimisé pour le RT
Pipeline graphique optimisé pour le RT
Un pipeline optimisé pour le RT
En effet, du fait des multiples rebonds des rayons et du temps nécessaire à la traversée du BVH, les charges ne sont pas uniformes et le GPU peut perdre un temps précieux à attendre les résultats, comme expliqué dans le paragraphe SER en page précédente. L'unité d'ordonnancement est donc là pour apporter de la cohérence au sein de tout cela, afin de retrouver un mode de fonctionnement optimum pour le GPU, favorisant le parallélisme et donc de meilleures performances in fine. Il est intéressant de noter qu'Intel propose une telle approche dès son premier jet, alors que Nvidia ne communique (ce qui ne veut pas forcément dire qu'il n'y avait pas des mécanismes destinés à retrouver un minimum de cohérence sur Turing / Ampere) sur le sujet qu'à sa troisième itération.

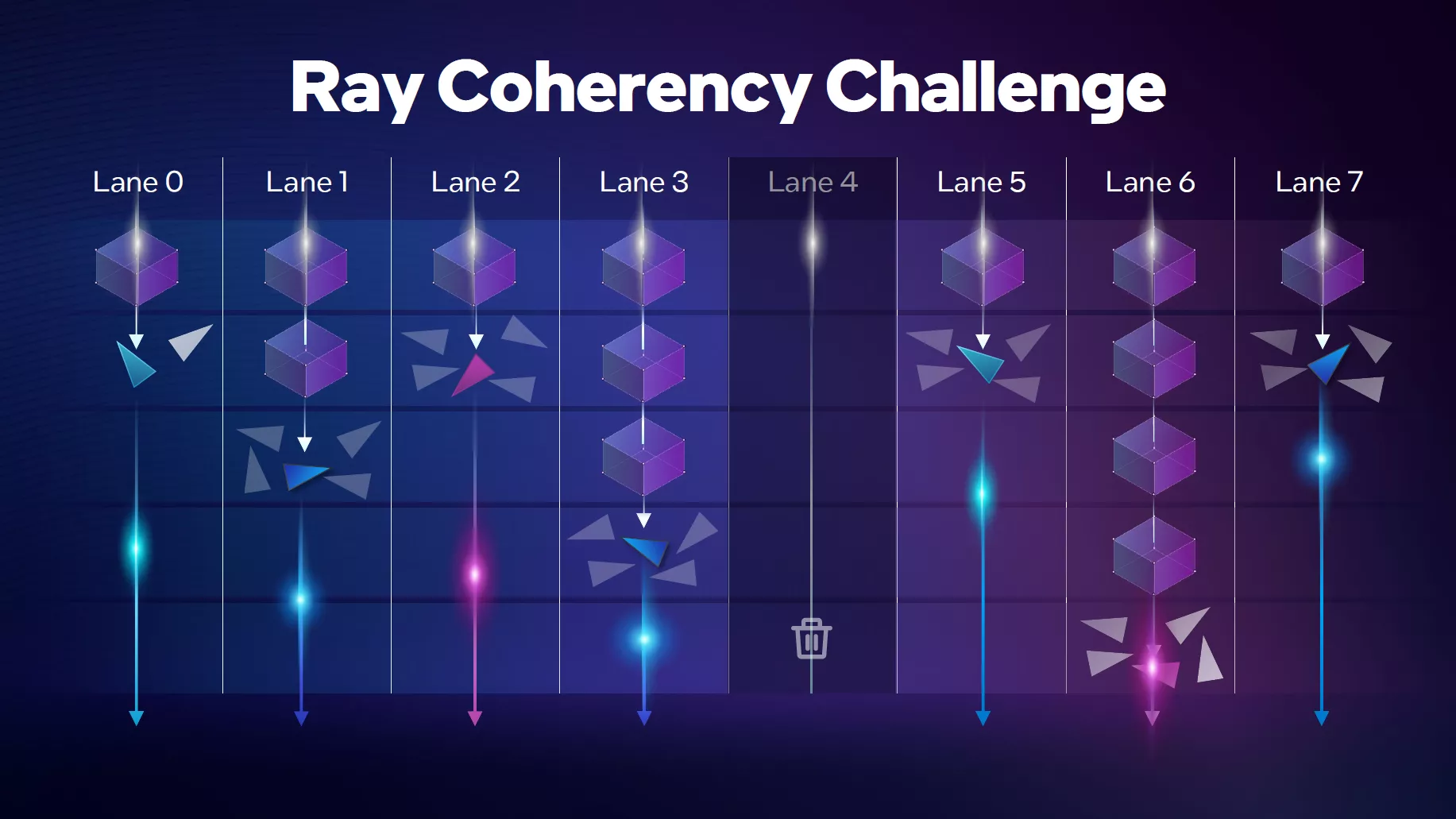 Les défis du Ray Tracing
Les défis du Ray Tracing
 L'ordonnancement RT
L'ordonnancement RT
Les défis de l'accélération hardware du RT
Intel résume le fonctionnement de son approche par le biais des schémas suivants, mettant en évidence la nature asynchrone par essence du Ray Tracing et la pertinence de son approche pour une exécution optimale. Les bleus ont, semble-t-il, pris le temps d'analyser tous les tenants et aboutissants de ce mode de rendu et proposé dès l'itération initiale, une solution qui semble plus aboutie pour cette accélération du BVH que la proposition initiale d'AMD avec RDNA 2, probablement davantage étudiée dans l'urgence.

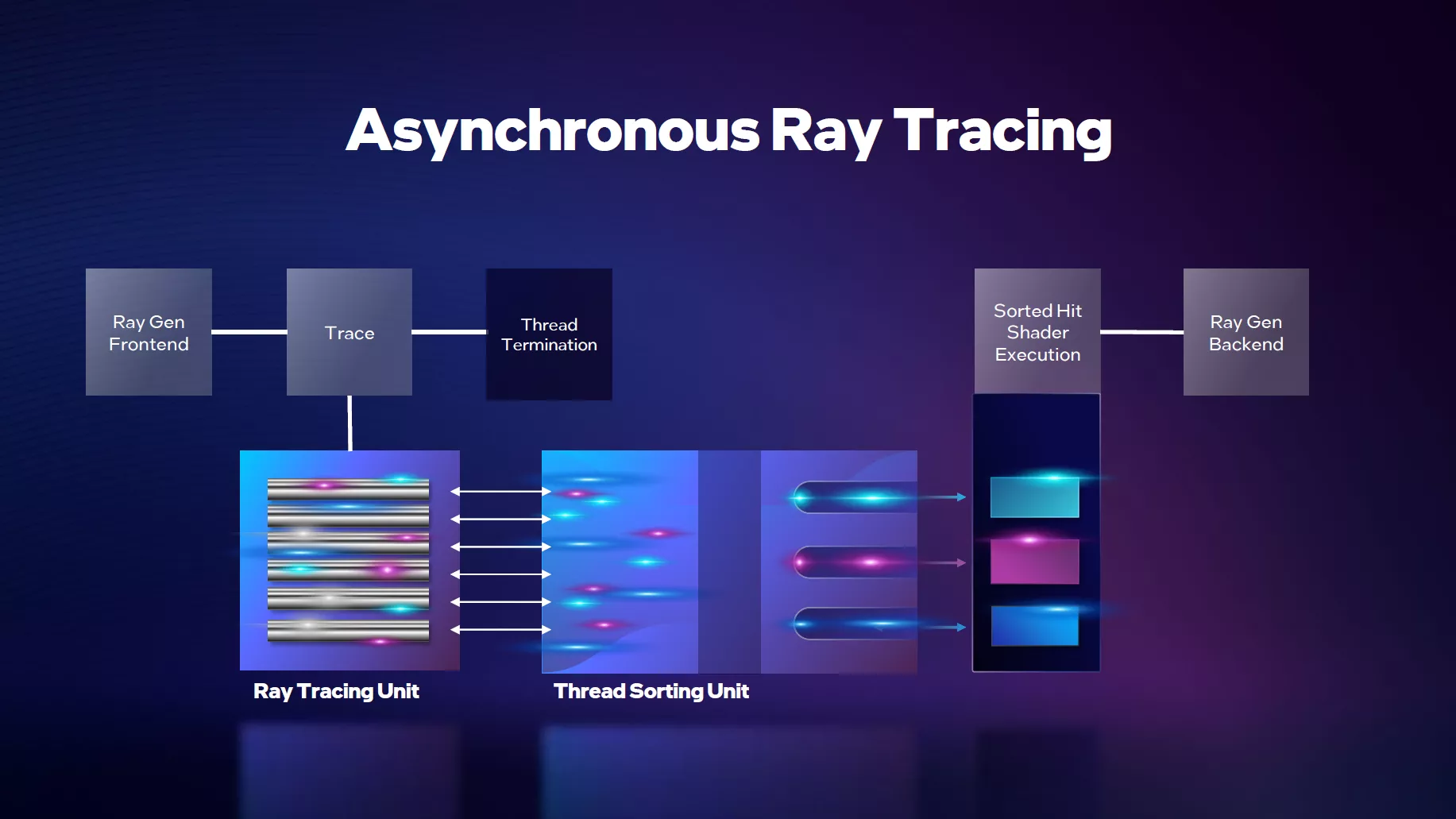 Le Ray Tracing par nature asynchrone pour un GPU
Le Ray Tracing par nature asynchrone pour un GPU
 Les capacité en RT d'Alchemist
Les capacité en RT d'Alchemist
L'implémentation de l'accélération RT selon Intel
Des moteurs multimédias et d'affichage dernier cri
Un mot rapide sur le moteur d'affichage, qui prend en charge jusqu'à 4 flux vidéos simultanés. Côté norme, le HDMI se limite à la version 2.0b, pas de panique pour autant puisqu'il est possible pour les fabricants de proposer sur leur modèle la version 2.1, via un convertisseur Display Port vers HDMI 2.1 optionnel. À propos de Display Port, la norme 2.0 10G est enfin de vigueur (même si la 1.4a n'est en rien limitante pour la plupart des usages). Du côté moteur vidéo, là aussi les dernières itérations sont supportées, et ce autant en décodage qu'en encodage, soit une première pour l'encodage pour de l'AV1 (partagée avec Ada Lovelace).


Des moteurs d'affichage et vidéo dernier cri
Voilà, c'est tout ce que nous pouvions vous dire sur cette nouvelle microarchitecture Xe-HPG, passons à présent à celle d'AMD en page suivante.




Merci pour ce gros test !
Super boulot ! Merci ! Les explications de fonctionnement sont super informatives.
Je pourrai abuser et demander l'ajout de la gamme en dessous : une 3060, une 4060, une 6600 de chez dédé ? ou tout du moins l'une d'elle ? :oS
Sinon ce serait super d'avoir une représentation des résultats en 3D (interactive ?) x: perf synthétique sur les 20 jeux, y: nuisance sonore, z: conso ... bon pi quand les humains auront évolué pour le percevoir, un 4ème axe "prix" ça serait au poil :D car c'est un peu de cette optimisation que chacun prend sa décision d'achat ;) Et ça serait marrant de voir des gros outliers sortant du lot.
Alors non, désolé et ce pour une raison simple : ces cartes ne sont pas adaptées du tout pour les définitions et réglages sélectionnés pour ce dossier. Même parmi l'échantillon de test, certaines références se retrouvent dans une situation inconfortable parce qu'elle ne sont pas utilisées dans leur plage adaptée (principalement en UHD). Le souci, c'est que cela conduit à une hiérarchie pour ces cartes qui n'est pas pertinente (parce que structurellement (plus de VRAM, de ROP, etc.) la référence A serait moins limitée que la référence B dans ces conditions qui ne font pas partie de leur plage nominale et ce même si cela ne rend pas le réglage jouable pour autant) et qui pourra induire en erreur le lecteur qui se contente de regarder l'indice moyen (et il y en a bcp).
C'est pour ça que je suis contre les plages de références trop larges du fait de ce biais. On pourrait le contourner partiellement en rajoutant le FHD en plus des QHD/UHD, mais d'une part cela va multiplier de manière conséquente la durée des mesures (et le risque qu'une nouvelle version de pilotes ou un patch de jeu sorte obligeant à reprendre toutes les cartes déjà testées), et d'autre part la pertinence retrouvée via cette nouvelle définition pour ces cartes entrainera aussi une absence de pertinence (pour cette même définition) pour certaines autres références qui pour le coup vont être totalement limitées par le CPU et se tourner les pouces rendant la hiérarchie biaisée à nouveau même si pour d'autres raisons. Nous avons toutefois réalisé d'autres dossiers où l'on retrouve des références communes qui permet d'extrapoler quelque peu le positionnement des références demandées.
Nos graphs dynamiques ne permettent pas de folie de ce genre pour le moment, mais probablement un type radar à l'avenir. Par contre les nuisances sonores sont fortement liées à la version choisie : on ne peut pas inférer ce que sera le niveau d'une Asus, Gigabyte, MSI, etc. en se basant sur la prestation à ce niveau de la carte de référence.
Pour ça il y a nos guides d'achat, ils vont être remis à jour prochainement.
Ça c'est du test de qualité (et de quantité) non de diou ! Merci Riton pour l'investissement !
Je me suis régalé en page 2 3 4, c'est tellement bien détaillé !
Merci pour le test Eric, comme d'hab' au top!
Content que ça t'ait plu 😉