
RDNA 3
À l'instar de ce qu'a fait Nvidia avec Ampere, RDNA 3 est une évolution notable de RDNA 2 qui était elle, très proche de la première itération. Quelques mots donc pour rappeler le contexte de RDNA (1) : il s'agit d'une refonte en rupture avec la précédente microarchitecture GPU des rouges (GCN). Son objectif était d'améliorer drastiquement les performances par watt, en soignant l'IPC via réduction de la dépendance au compilateur parallélisant les instructions. Pour ce faire, AMD a sérieusement repensé le fonctionnement et l'organisation de ses unités de calculs, mais aussi leur alimentation par un sous-système mémoire revu, en particulier la hiérarchie des caches. Les progrès en efficience ont été significatifs, mais elle accusait un retard important au niveau des fonctionnalités supportées (RT, VRS, Mesh Shader, etc.)
Pour la seconde itération de cette architecture, les rouges ont poursuivi en ce sens, avec 3 contributeurs principaux d'amélioration. Le premier était l'augmentation significative de l'IPC, en particulier avec l'inclusion d'un cache L3 très conséquent, réduisant d'autant les couteux accès à la VRAM. Le second était la réduction de la puissance nécessaire pour atteindre une fréquence donnée ou exécuter certaines tâches (là aussi aidé par cet Infinity Cache, la dénomination marketing du L3), et enfin le dernier consistait à améliorer la capacité à monter en fréquence de la microarchitecture (redondance des signaux, etc.). A cela, s'ajoutait la nécessaire remise à niveau des fonctionnalités (RT, VRS, etc.). Quid de RDNA 3 cette fois ? Commençons comme pour les concurrents par le diagramme de blocs du plus gros GPU, ici Navi 31.

 Diagramme de blocs Navi 31
Diagramme de blocs Navi 31
Tout comme son prédécesseur, nous y retrouvons les composants standards des rouges. Un processeur de commande central est toujours chargé de planifier et ordonner les différents threads. Selon AMD, il est à présent 2,3x plus performant que son prédécesseur pour les commandes de rendus multiples, permettant de réduire l'overhead CPU au niveau des pilotes ou de l'API. À ses côtés se trouvent les unités chargées de l'organisation et de la gestion des tâches Compute, ainsi qu'un processeur géométrique central et le cache L2. Diverses interfaces, moteurs vidéo & d'affichage, complètent cette partie du GPU. Le cache L3 et les contrôleurs mémoires sont à présent répartis au sein de 6 dies dédiés (nous détaillerons cela un peu plus bas). L'exécution des programmes est toujours réalisée au sein des Shaders Engine, équivalents grosso modo aux GPC / Xe-Core. Chacun dispose de leurs propres caches L1, unité de rastérisation (découpe des triangles en pixels), Primitive Unit (génération et traitement des triangles), ainsi que 32 ROP (unité de rendu/sortie) et 8 Dual Compute Unit, (contre 10 par Shader Engine sur Navi 21) comprenant comme leur nom l'indique, 2 CU dont la structure est similaire à celle de la génération précédente.
Des unités de calculs modifiées

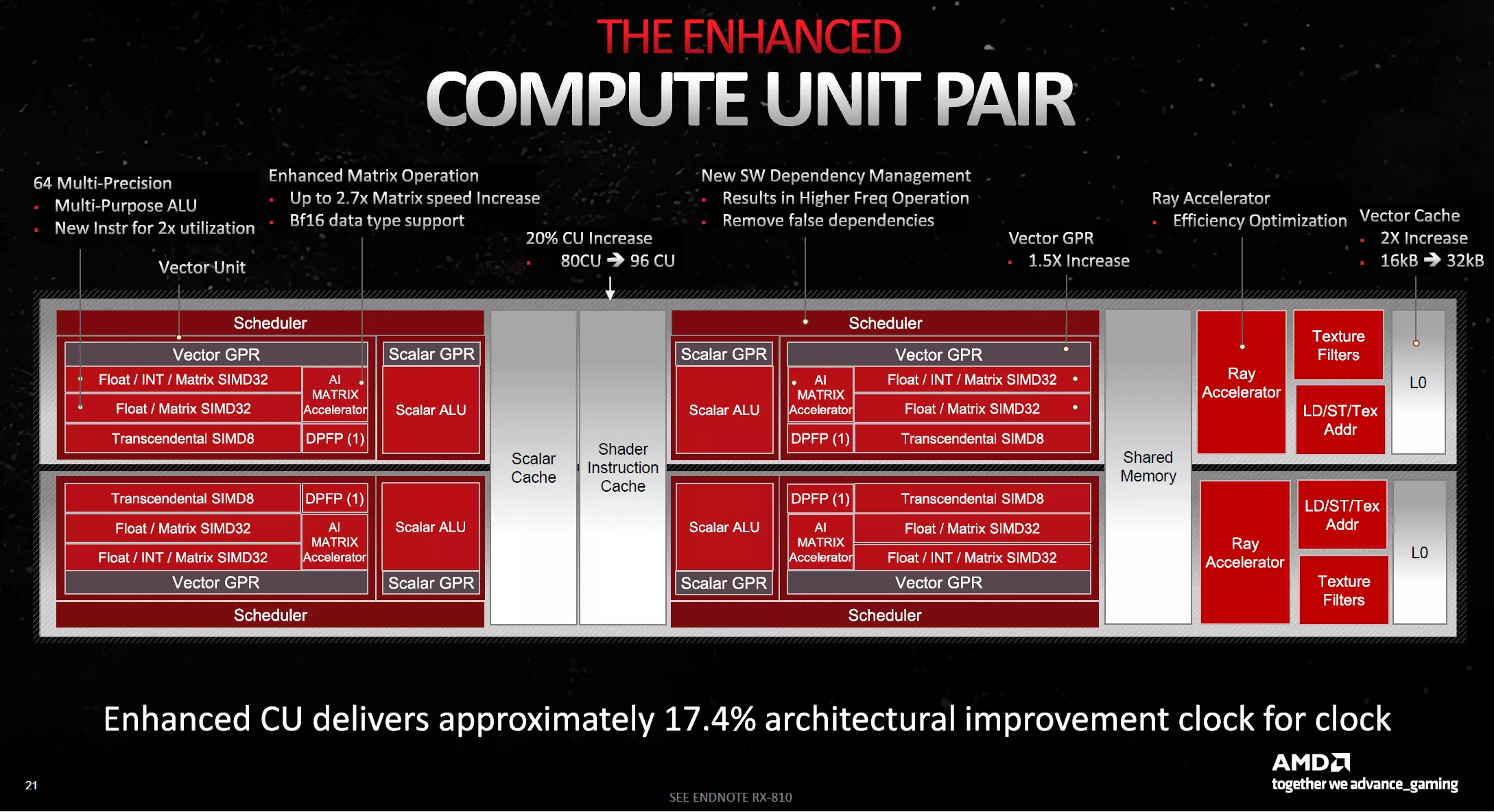 Compute Unit Pair
Compute Unit Pair
Mais similaire ne veut pas dire identique, loin de là. Car une des nouveautés de ces Compute Units, est la possibilité de doubler le taux d'exécution via Dual Issue. Comment tout cela fonctionne-t-il ? Eh bien, AMD a tout simplement doublé le nombre d'ALU FP32 par SP au sein des unités vectorielles. Elles sont donc théoriquement capables d'exécuter 2 instructions FP32 par cycle. Toutefois, afin que l'implémentation ne soit pas trop coûteuse, il y a des contraintes à leur utilisation. Ainsi, à l'instar du caméléon, ces unités supplémentaires vont devoir partager leur disponibilité entre virgule flottante et entier. Qui plus est, ce doublement ne sera effectif que lorsque le compilateur sera capable d'extraire une seconde instruction d'un même WaveFront (liste de tâches à traiter envoyées au GPU). C'est mine de rien un gros changement de philosophie, et si RDNA 2 ne changeait pas grand-chose à ce niveau par rapport à l'itération originelle, ce n'est pas le cas ici et on revient à une philosophie plus proche de GCN. L'efficacité de cette implémentation dépendra donc fortement de la partie logicielle en fonction du type de tâches à traiter.

 Fonctionnement SIMD des Vector Units
Fonctionnement SIMD des Vector Units
Autre gros changement, la possibilité d'utiliser les unités vectorielles pour le traitement type matriciel des faibles précisions. Cet usage est fortement utilisé en IA, en particulier pour les tâches d'inférence, mais aussi d'apprentissage. AMD rejoint donc Nvidia et Intel en implémentant une telle fonctionnalité au sein de son architecture grand public, à une nuance près toutefois. Les bleus comme les verts disposent d'unités dédiées pour ces tâches, pouvant dès lors fonctionner de manière concomitante avec les ALU "classiques". Ce n'est pas le cas ici, puisque le fonctionnement matriciel remplace purement et simplement celui classique en SIMD (Single Instruction on Multiple Data). Du fait de cette limitation, il semble peu probable que les rouges ajoutent de sitôt une composante IA au FSR, à contrario des DLSS et XeSS, mais sait-on jamais.

 Fonctionnement matriciel des Vector Units
Fonctionnement matriciel des Vector Units
RT de seconde génération
Un des points faibles indéniable de RDNA 2, est son implémentation faiblarde de l'accélération du BVH pour le Ray Tracing. AMD indique avoir retravaillé cela sur plusieurs axes. Le premier est la prise en charge de marqueurs géométriques, permettant d'éviter de lancer une traversée du BVH pour rechercher une intersection entre rayon et triangle, si ce dernier peut être éjecté préalablement (culling), car non visible dans une scène.

 RT 2ème Gen : Culling
RT 2ème Gen : Culling
Le second point d'amélioration concerne le filtrage et tri des rayons préalablement à leur entrée dans le BVH, afin d'éviter des itérations supplémentaires lors de la traversée de ce dernier. Ainsi, les rayons sont classés en fonction de la distance les séparant du premier impact, mais aussi ceux qui vont présenter des chevauchements (ombres) ou se terminant à la première intersection.

 Organisation RT
Organisation RT
Enfin, la dernière optimisation est une prise en charge Hardware directement au sein des Ray Accelerator, de l'ordonnancement et la traversée du BVH, qui étaient auparavant directement réalisés via shaders sur les unités de calcul traditionnelles, les libérant ainsi pour d'autres instructions, d'autant que l'organisation SIMD se prête plutôt mal à ce genre de tâches. Les caches liés au RT ont également été gonflés, afin de mieux supporter les charges RT lourdes.
AMD précise également qu'un nouvel algorithme d'ordonnancement permettrait d'optimiser l'usage des ressources, à l'image du SER des verts ou de son équivalent chez les bleus. Enfin, les rouges indiquent que le débit brut de ces Ray Accelerator, progresse de 50 % par rapport à la génération précédente. Au final, toutes ces améliorations pourraient conduire à des gains allant jusqu'à 80 % lors de l'usage du Ray Tracing (à fréquence GPU identique).

 Optimisation BVH RT
Optimisation BVH RT
Des caches évoluant légèrement
Un mot concernant les différents caches. Le L2 progresse de 50 %, suivant ainsi l'augmentation du nombre de Shader Engines, la progression est par contre plus marquée pour les L0 et L1, qui sont eux, doublés. En définitive, seul le L3 (Infinity Cache) recul au niveau de sa capacité, à 96 Mo maximum pour Navi 31 contre 128 Mo pour Navi 21. On notera toutefois une progression de la bande passante entre niveaux de cache.

 Hiérarchie des caches
Hiérarchie des caches
Des chiplets sur GPU
Même si ce n'est pas vraiment un concept architectural, il nous semble important d'évoquer ce sujet concernant RDNA 3. Qu'est-ce qu'un chiplet ? Voici une définition simple : au lieu de concevoir une seule puce monolithique de taille conséquente, il est préférable, selon AMD, de créer plusieurs puces plus petites dédiées à des fonctions précises. Elles seront ainsi plus aisées à produire et pourront utiliser des procédés de fabrication différents. Pourquoi utiliser des procédés de fabrication distincts ? Toujours selon les rouges, certaines parties d'un GPU ne profitent que très peu des nouvelles finesses de gravure, tant du côté de la densité que des performances des transistors. Comme dans le même temps, le coût de production des dernières lithographies explose, il parait plus que légitime de réserver ces dernières aux seuls éléments qui vont en tirer un réel bénéfice (les unités logiques) et se contenter d'un procédé moins coûteux pour d'autres (interfaces & mémoires).

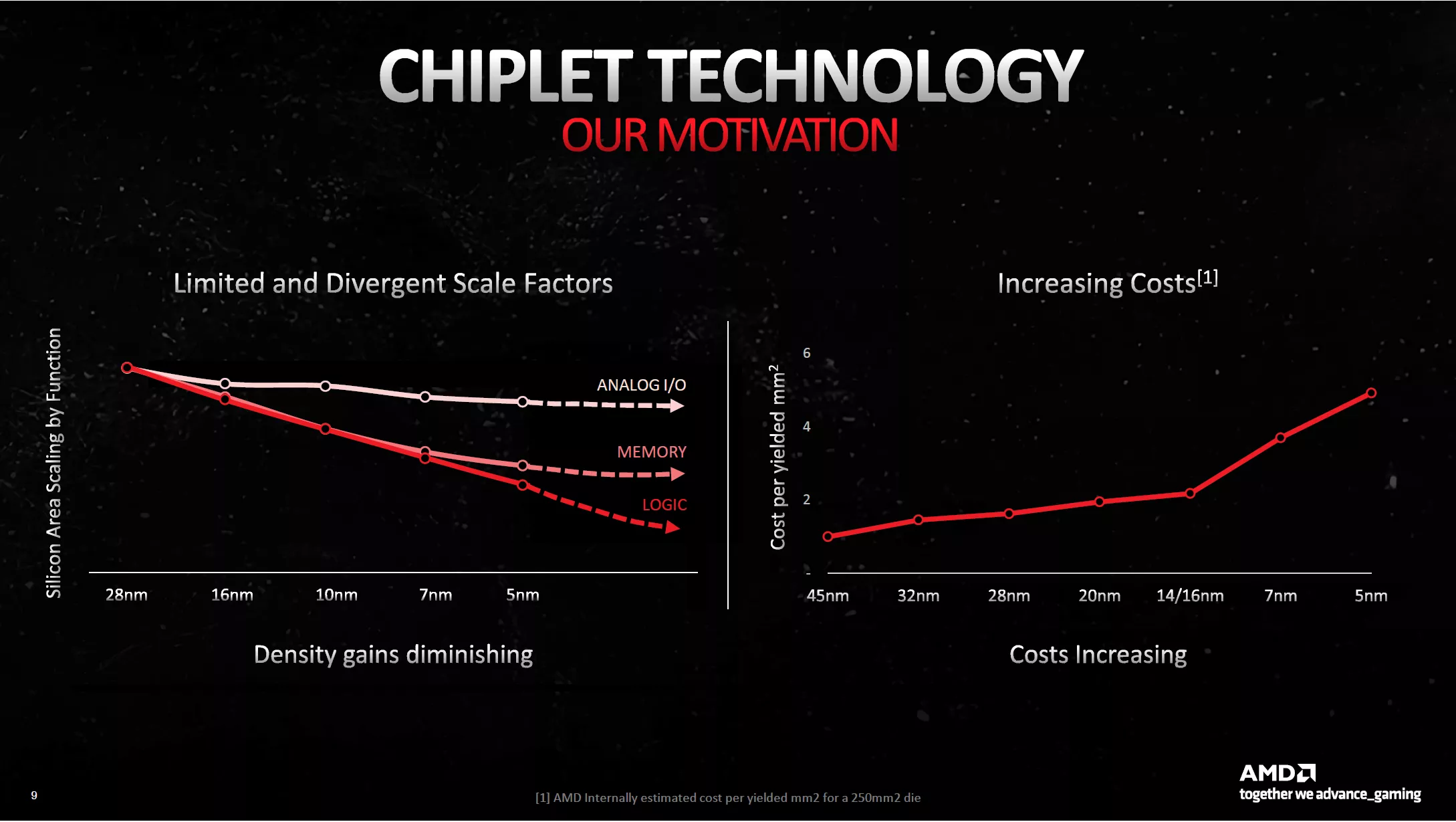 Transistor scaling
Transistor scaling
Voilà pour la théorie, mais identifier les éléments qui vont pouvoir profiter ou non de l'amélioration de la lithographie est une chose, être capable de les désolidariser au sein de dies séparés, en est une toute autre. Car le plus gros défi qui se pose ici vient de la complexité de l'interconnexion entre éléments d'un GPU, sans comparaison avec celle d'un CPU. Pour imager cela, AMD compare le besoin d'interfaçage entre dies d'un CPU Epyc et des "blocs comparables" au sein d'un GPU. Le rapport de complexité est de 1 pour 100, ce qui signifie que les rouges ne pouvaient pas se contenter de copier-coller la solution déjà existante pour ses CPU.

 Différences CPU / GPU en bande passante
Différences CPU / GPU en bande passante
Pour commencer, il a fallu déterminer où procéder à la scission. Après analyse, les rouges ont identifié que le cache L3 (qui constitue l'avancée majeure de RDNA 2) profitait finalement assez peu d'un passage à la gravure 5 nm. Il en est de même pour les interfaces mémoire GDDR6, ce sont donc ces éléments qui ont été logiquement désignés comme pertinents à extraire du die principal (Graphics Compute Die), pour les transférer sur des chiplets annexes (Memory Cache Die) conservant un procédé de gravure similaire (6 nm = nœud de gravure 7 nm) à la génération précédente.

 Ou partitionner un GPU ?
Ou partitionner un GPU ?
Voilà pour répondre à la question "où pratiquer la séparation au sein d'un GPU ?", restait maintenant à définir le "comment procéder ?". Car ce n'est pas une mince affaire, sachant que la bande passante nécessaire entre GCD-MCD, est plus de 10 fois supérieure à celle entre chiplets CPU. Il a donc fallu revoir les techniques de packaging pour proposer une interface jusqu'à présent inédite entre dies.

 Bande passante des interconnexions
Bande passante des interconnexions
Cette dernière est nommée Infinity Fanout Links par AMD. Comme son nom l'indique, elle s'appuie sur l'Infinity Fabric qui autorise dans cette implémentation, jusqu'à 9,2 Gb/s. La bande passante cumulée de tous les MCD (6) avec le GCD, culmine ici à 5,3 To/s, soit un peu moins de 900 Go/s entre un MCD et le GCD.

 Interconnect GCD - MCD
Interconnect GCD - MCD
Pour cette interconnexion au sein du packaging, AMD n'utilise plus de substrat organique comme c'était le cas jusqu'à présent. Les rouges ne vont pas plus loin dans les détails à ce niveau, cela doit de toute façon faire appel à de la chimie complexe, excédant nos compétences en la matière. Ce qu'il faut en retenir, c'est que cette technologie permet de doubler le nombre de lignes d'interconnexion au sein de l'interface, en comparaison de ce qui peut se faire via un traditionnel substrat organique.

 Densité de l'interconnect
Densité de l'interconnect
AMD précise également que cette interface n'est pas seulement performante, elle a aussi été développée pour être économe. Pour ce faire, la tension de fonctionnement est faible, et l'ajustement des fréquences est très agressif, pour permettre de réduire ces dernières dès que c'est possible. Selon les rouges, cela permettrait de sauver 80 % d'énergie par bit en comparaison de liens d'un packaging traditionnel. Au final, une bande passante effective de 3,5 To/s, ne couterait que 5% de la puissance électrique totale du GPU d'après AMD.

 Efficience de l'interconnexion
Efficience de l'interconnexion
Un dernier mot concernant l'augmentation de latence induite par cette interface. Toujours selon AMD, cette dernière serait limitée en comparaison d'une approche monolithique traditionnelle. Néanmoins, pour la compenser, AMD a augmenté de respectivement 43 % et 18 % la fréquence de fonctionnement de l'Infinity Fabric et du GPU. Ces deux actions combinées conduiraient à une baisse de 10 % de la latence d'accès au cache L3 sur Navi 31, en comparaison de celle mesurée pour Navi 21.

 Latence de l'interconnexion
Latence de l'interconnexion
Des moteurs d'affichage et vidéo aux dernières normes
S'il y a un point sur lequel AMD a particulièrement insisté lors de l'annonce de ses cartes, c'est bien sur le moteur d'affichage qui prend en charge la norme Display Port 2.1. À un point que les performances étaient presque reléguées au second plan (à dessein ajouterons les mauvaises langues). Quoi qu'il en soit, c'est une très bonne nouvelle que les rouges aient décidé d'adopter cette norme DP 2.1, la décision des verts de ne pas le faire (ne serait-ce que le 2.0 à l'instar des Intel ARC) reste incompréhensible, pour des cartes censées être au sommet de la technologie. Alors bien sûr, le DP 1.4 est parfaitement suffisant pour permettre des affichages en haute définition et fréquences de rafraîchissement confortables avec le complément du DSC, proposant une compression sans perte, mais cela fait toute de même pingre pour des cartes à ce tarif. Nous saluons donc les décisions d'Intel et AMD de les incorporer à leur GPU 2022.

 Moteur d'affichage
Moteur d'affichage
Finissons avec le Media Engine, qui lui aussi progresse de manière significative. Si la génération précédente avait apporté le décodage AV1, c'est l'encodage de ce codec qui est à présent assuré par Navi 31, rejoignant ainsi les puces Ada Lovelace et Alchemist. AMD précise également que la fréquence de son moteur vidéo a été augmentée de 80 %, de quoi lui permettre de traiter simultanément décodage et encodage des flux H.264/H.265.

 Moteur encodage/décodage vidéo
Moteur encodage/décodage vidéo
Voilà pour cette dernière microarchitecture GPU, il est temps de passer aux spécifications des cartes et quelques tests synthétiques page suivante.




Merci pour ce gros test !
Super boulot ! Merci ! Les explications de fonctionnement sont super informatives.
Je pourrai abuser et demander l'ajout de la gamme en dessous : une 3060, une 4060, une 6600 de chez dédé ? ou tout du moins l'une d'elle ? :oS
Sinon ce serait super d'avoir une représentation des résultats en 3D (interactive ?) x: perf synthétique sur les 20 jeux, y: nuisance sonore, z: conso ... bon pi quand les humains auront évolué pour le percevoir, un 4ème axe "prix" ça serait au poil :D car c'est un peu de cette optimisation que chacun prend sa décision d'achat ;) Et ça serait marrant de voir des gros outliers sortant du lot.
Alors non, désolé et ce pour une raison simple : ces cartes ne sont pas adaptées du tout pour les définitions et réglages sélectionnés pour ce dossier. Même parmi l'échantillon de test, certaines références se retrouvent dans une situation inconfortable parce qu'elle ne sont pas utilisées dans leur plage adaptée (principalement en UHD). Le souci, c'est que cela conduit à une hiérarchie pour ces cartes qui n'est pas pertinente (parce que structurellement (plus de VRAM, de ROP, etc.) la référence A serait moins limitée que la référence B dans ces conditions qui ne font pas partie de leur plage nominale et ce même si cela ne rend pas le réglage jouable pour autant) et qui pourra induire en erreur le lecteur qui se contente de regarder l'indice moyen (et il y en a bcp).
C'est pour ça que je suis contre les plages de références trop larges du fait de ce biais. On pourrait le contourner partiellement en rajoutant le FHD en plus des QHD/UHD, mais d'une part cela va multiplier de manière conséquente la durée des mesures (et le risque qu'une nouvelle version de pilotes ou un patch de jeu sorte obligeant à reprendre toutes les cartes déjà testées), et d'autre part la pertinence retrouvée via cette nouvelle définition pour ces cartes entrainera aussi une absence de pertinence (pour cette même définition) pour certaines autres références qui pour le coup vont être totalement limitées par le CPU et se tourner les pouces rendant la hiérarchie biaisée à nouveau même si pour d'autres raisons. Nous avons toutefois réalisé d'autres dossiers où l'on retrouve des références communes qui permet d'extrapoler quelque peu le positionnement des références demandées.
Nos graphs dynamiques ne permettent pas de folie de ce genre pour le moment, mais probablement un type radar à l'avenir. Par contre les nuisances sonores sont fortement liées à la version choisie : on ne peut pas inférer ce que sera le niveau d'une Asus, Gigabyte, MSI, etc. en se basant sur la prestation à ce niveau de la carte de référence.
Pour ça il y a nos guides d'achat, ils vont être remis à jour prochainement.
Ça c'est du test de qualité (et de quantité) non de diou ! Merci Riton pour l'investissement !
Je me suis régalé en page 2 3 4, c'est tellement bien détaillé !
Merci pour le test Eric, comme d'hab' au top!
Content que ça t'ait plu 😉