
Et le hardware dans tout ça ?
Vous n’avez pas pu le manquer, l’IA façonne les dernières tendances des architectures matérielles, et ce depuis quelques années déjà. Si nous avons déjà abordé que le produit matriciel est la clef de voute du machine learning (entraînement comme inférence), cela ne se limite (heureusement) pas à cela. Mémoires, précisions et parallélisme sont également à prendre en compte et à calibrer correctement par rapport au rôle souhaité : de quoi expliquer pourquoi les marques nous inondent d’accélérateurs dans à peu près tout ce qui est programmable. Vous l’avez compris : c’est parti pour passer en revue le hardware, sauce ML !
Les GPU mènent la danse !
Difficile de causer IA sans causer GPU. Si les balbutiements des réseaux de neurones ont été effectués en laboratoire sur des CPU pour cause de facilité de programmation (l’idée originelle est de montrer que cela fonctionne, avant d’optimiser), l’idée de déporter les calculs sur carte graphique a été rapidement évoquée. Dès 2003, une équipe sud-coréenne avait déjà réussi à implémenter un perceptron multicouche sur… une ATi RADEON 9700 PRO (128 Mio de VRAM, 8 ROP et 325 MHz de fréquence… pas de doute, nous sommes bien dans les années 2000).
Pourtant, ce n’est pas ATi — racheté par AMD en 2006 — qui a mené la danse du machine learning sur GPU, mais NVIDIA. La raison est plus politique que technique : si ATi a été le premier à mettre en pratique le concept de GPGPU (effectuer du calcul scientifique sur les unités graphiques) avec leur API Close To Metal (CTM) en 2006, la concurrence des verts fut rude avec CUDA, lancé initialement en 2007, qui s’est imposé par la suite comme « la » référence pour programmer sur GPU dans la sphère professionnelle. Sentant l’IA arriver, le caméléon a été dégoter du personnel capable d’effectuer des optimisations ou de la recherche dans le secteur, et a pu ainsi asseoir sa domination par un cercle vertueux apportant renommée, ventes, argent puis cerveaux et performances.

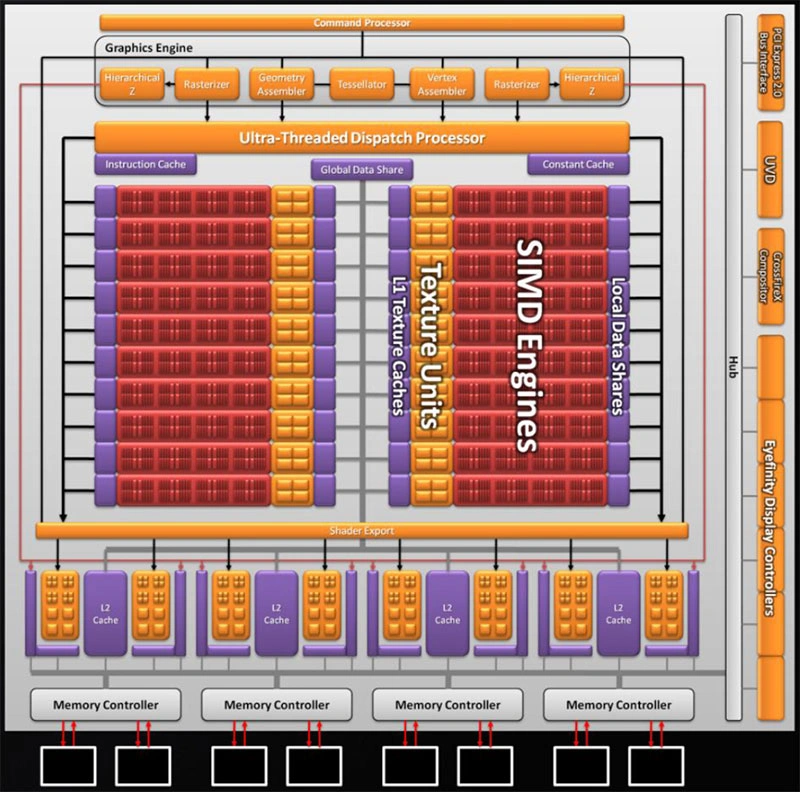
Représentation logique d’une Radeon HD 5870. Tous les cœurs rouges sont des unités capables d’effectuer des multiplications-accumulation (MAC) en parallèle : le paradis des réseaux de neurones !
Néanmoins, ce serait mentir que de prétendre que NVIDIA a tordu le cou des réseaux pour les faire tenir sur GPU. Il y a plutôt eu un sacré coup de chance : naturellement, les réseaux de neurones demandent une quantité de calcul énorme, mais régulière (la même suite de calcul doit être effectuée pour toutes les couches : pas besoin d’attendre la valeur de données pour savoir quoi faire ensuite) et surtout parallèle. Un neurone se fiche pas mal des neurones adjacents de la même couche : il se contente de faire ses multiplications en partant de ses entrées. C’est parfait, car c’est exactement ce pour quoi les GPU ont été faits : des calculs de rastérisation dans lequel un pixel se fiche pas mal des valeurs des pixels adjacents au moment du rendu ! Difficile en fait d’imaginer une application aussi parfaitement adaptée, tout du moins à l’époque des empilements simples de perceptrons, et dans laquelle les architectures vectorielles (i.e. basée sur des calculs parallèles au niveau des cœurs GPU, à contrario des architectures scalaires, à plus grand nombre de cœurs, mais traitant une seule donnée à la fois) dominaient ! Visionnaires, les verts ont su prendre la vague au bon moment et développer/imposer leur écosystème basé sur CUDA au sein de l’industrie en coupant l’herbe sous le pied d’ATi/AMD — pourtant tout aussi capable de machine learning à l’époque —, une stratégie qui a encore des répercussions aujourd’hui sur la popularité des cartes du caméléon.
Depuis, les architectures ont évolué vers le scalaire, mais embarquent chez NVIDIA depuis 2017 (microarchitecture Volta) des unités dédiées nommées Tensor Cores permettant de déporter une partie des calculs matriciels, les plus lourds, des unités standards. Un choix révélant l’importance de l’IA parmi les clients du caméléon, car ces unités spécialisées perdent fatalement en flexibilité d’usage ; bien que certaines simulations numériques bénéficient elles aussi de produits matriciels accélérés.

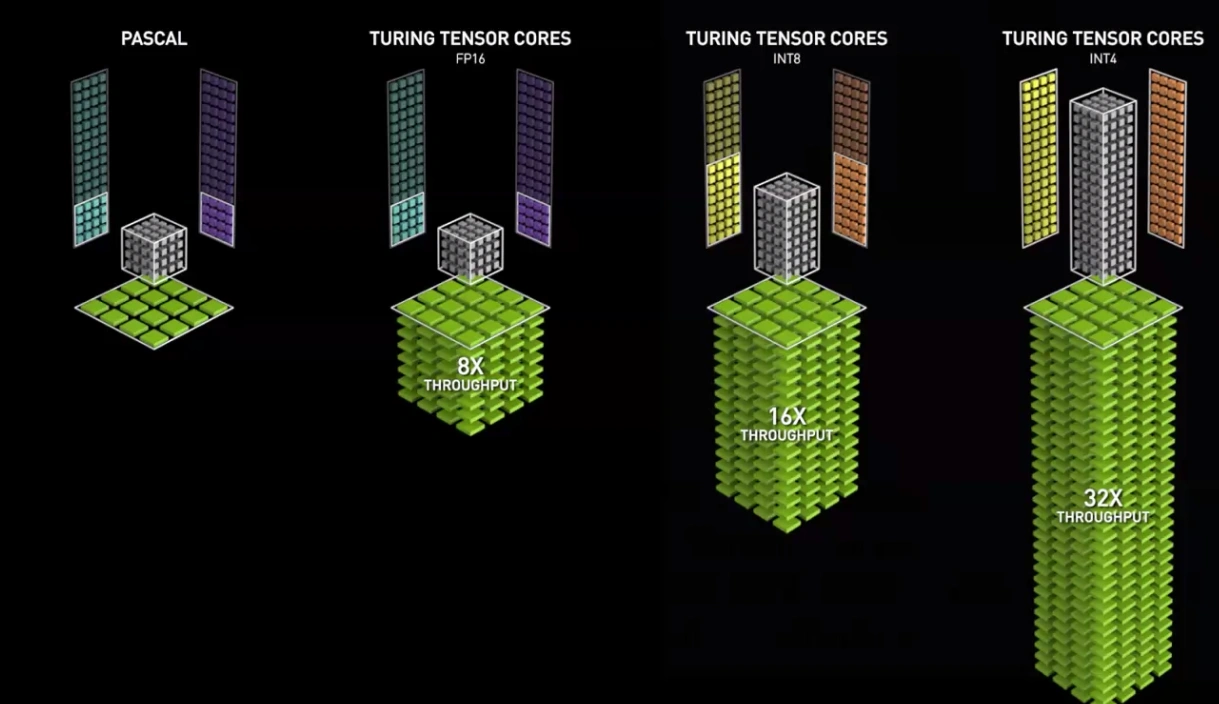
Le Tensor Core : l’unité canonique de Machine Learning pour NVIDIA
Cependant, un écueil de taille reste : les multiplications de nombres, une fois mises en parallèle, cela reste gourmand, en temps comme en énergie. Il est alors venu une idée aux concepteurs de réseau : passer d’une représentation en nombre flottants 32-bit à une représentation sur 16-bit, voire en utilisant des nombres entiers ou en précision à virgule fixe. Sans trop rentrer dans les détails, cela correspond à changer la manière dont les 0 et 1 matériels représentent des nombres, ce qui troque leur précision et leur capacité à exprimer des grands nombres pour des calculs plus rapides et moins énergivores. Évidemment, tout cela ne se fait pas sans une dose de mathématique limitant l’impact sur les performances des réseaux et est principalement utilisé lors de l’inférence sur des appareils plus contraints en puissance, ce pourquoi nous y reviendrons dans la dernière section de cette page : gardez juste en tête que les compatibilités FP16, BF16, FP8 et INT16/INT8 servent principalement à l’inférence de masse sur GPU, en gardant les mêmes architectures de réseaux que celle vues précédemment.
Avec les dernières tendances de réseaux creux (c. f. notre page « Le multicouche et le modernisme »), NVIDIA a revu sa copie et propose depuis quelques années un Tensor Core adapté pour cet usage, c’est-à-dire capable de fonctionner sur des données possédant moins de 50 % de zéros en utilisant une représentation compressée, mais dédiée des matrices, reposant sur une contrainte de régularité des zéros. Si cela n’est pas aussi efficace qu’une architecture 100 % sur-mesure, difficile de faire mieux sans exploser les bandes passantes, où revoir complètement la puce pour verser dans les accès aléatoires à la VRAM, typiques des représentations compressées de matrices creuses… de quoi laisser penser qu’une séparation des architectures IA et GPU est possible, voire déjà à l’œuvre. En effet, avec la scission des générations grand public/pro (Turing vs Volta, Lovelace vs Hopper), les GPU pour datacenter intègrent déjà en avant-première les technologies d’IA et font usage de mémoires HBM plus rapides. Et, si jamais les pros veulent une architecture plus flexible, des dérivés des joueuses RTX leur sont également proposés : une carte pour chaque utilisation !

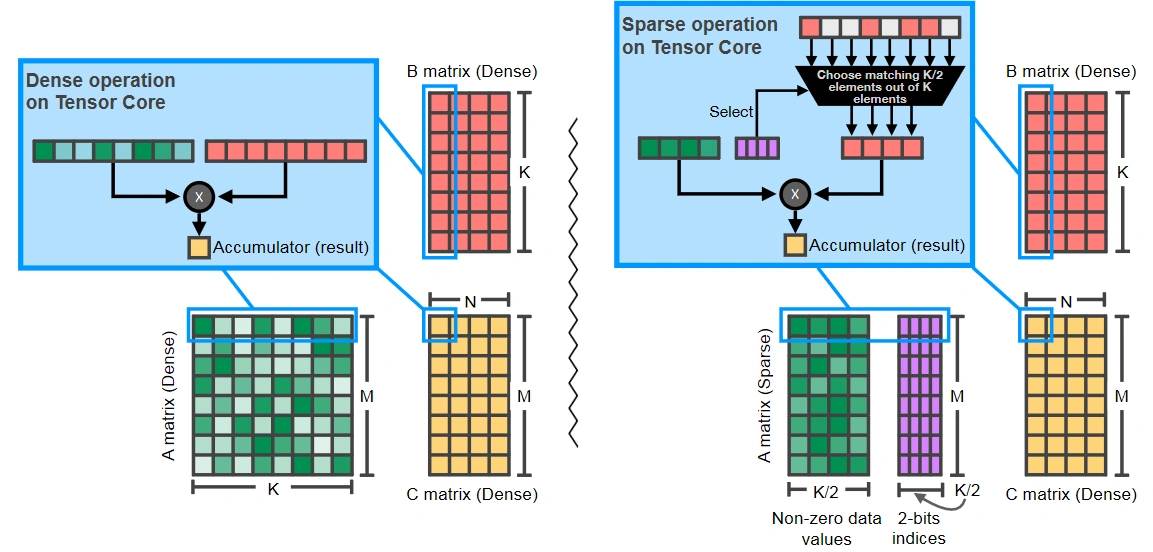
Version dense à gauche, creuse à droite : une sélection se fait au moyen d’un tableau des indices pour lesquels les valeurs sont non-nulles.
Du côté de la concurrence, les architectures présentent de légères variations, comme chez Intel ou les unités matricielles nommées XMX directement au sein de son bloc de base Xe-Core et accélérant les opérations en fonctionnant sur une largeur de donnée de 1024 bits. Chez AMD, la Mi300, basée sur CDNA3 (version pour serveurs de calcul des architectures graphiques d’AMD) offrent également un support de la sparsité, s’alignant ainsi sur le leader vert.
Et les CPU ?
Pour les CPU, l’histoire est plus complexe. Leur facilité de programmation les a mises sur la première ligne lorsque les réseaux de neurones étaient encore une utilisation de niche, mais les processeurs ont rapidement été délaissés au profit des GPU dès qu’il est question d’utilisation dédiée au machine learning. Cependant, tout n’est pas perdu pour eux, car certains centres de calcul ne servent pas uniquement à l’IA, et certaines configurations (typiquement des ordinateurs portables) ne peuvent pas utiliser de GPU dédié faute d’en avoir un ! Ainsi, les processeurs ont évolué en rajoutant des unités de calcul vectorielles (i.e. capable d’effectuer des additions/multiplication en parallèle), ce qui est parfait pour nos réseaux ! Notez tout de même que, tout comme les GPU, ces unités ne sont pas arrivées pour le machine learning, mais se sont révélées bien utiles une fois ce dernier grandement répandu.

Lier un back-end vectoriel avec une charge de travail d’IA, tel est le rôle DL Boost d’Intel.
Cependant, des extensions tel DL Boot (chez Intel, également nommé VNNI) sont apparues pour améliorer l’utilisabilité des unités vectorielles dans le cadre du machine learning. Dans le même genre, le déploiement progressif de l’AVX-512 (du vectoriel toujours plus parallèle) et l’ajout du support du BFloat16/Int8 sont autant d’adaptations des processeurs aux tâches de machine learning. Contrairement aux GPU, les CPU sont prévus pour faire tous les types de calcul « moyennement bien », il est donc peu probable que la tendance d’intégration d’instructions dédiées à l’IA s’amenuise ! En revanche, pour améliorer les performances dans des tâches d’inférences légères, il faut alors soit passer sur GPU, soit s’équiper d’un accélérateur dédié… Que nous abordons au paragraphe suivant !
Et… autre chose ?
Du matériel spécialisé
Impossible de passer à côté tant la chose est matraquée lors de toutes les annonces : les SoC mobiles, les CPU Meteor Lake, les CPU Ryzen with AI sont tous équipé d’un « coprocesseur d’IA », ou encore un « NPU » voir « DPU » pour Neural Processing Unit et Deep Leaning Processing Unit. Une puce magique étant tout simplement l’équivalent d’un GPU pour l’IA. Vient alors l’interrogation suivante : si un GPU est déjà « naturellement adapté pour l’IA », qu’est-ce donc que ces bidules-ci ?

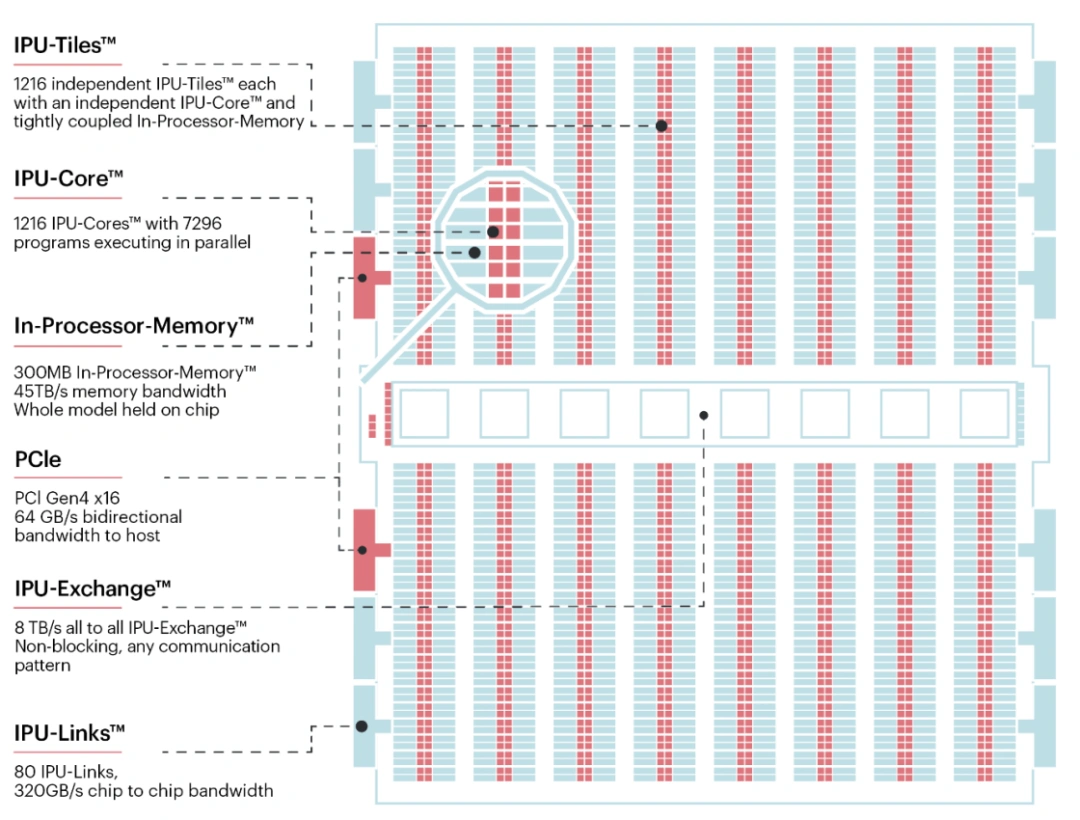
Chez GraphCore, la sauce est claire : des unités indépendantes mises côte à côte avec une mémoire locale et un interconnecte qui poutre pour échanger les résultats partiels.
Hé bien, un GPU, cela peut encore faire du calcul graphique, du Ray Tracing ou de la simulation. Pour gagner sur le rapport performance/consommation (comprendre : consommer le moins possible d’énergie pour chauffer le moins possible, et prendre le moins d’espace sur une puce), cette flexibilité de programmation est jetée dans la corbeille pour ne garder que les primitives essentielles : les multiplication-accumulations et les produits matriciels. Ainsi, un accélérateur d’IA n’est rien de plus qu’une série d’unités de calcul matriciel reliées la plupart du temps dans un interconnect en mesh (on parle alors de réseau systolique) facilitant les échanges de résultats entre les accélérateurs adjacents, ce qui convient parfaitement aux couches d’un réseau appliquant leur transformation les unes après les autres. Selon la cible — entraînement de masse ou inférence légère dans un smartphone — les technologies mémoires et les tailles des puces seront grandement variables, mais le principe global restera similaire. Dans le domaine, vous trouverez ainsi du Gaudi (Intel), Google Tensor Processing Unit et GraphCore pour de l’entraînement haute performance en data center, et du Movidius ou du Qualcom Hexagon pour de l’inférence plus légère sur des produits embarqués.

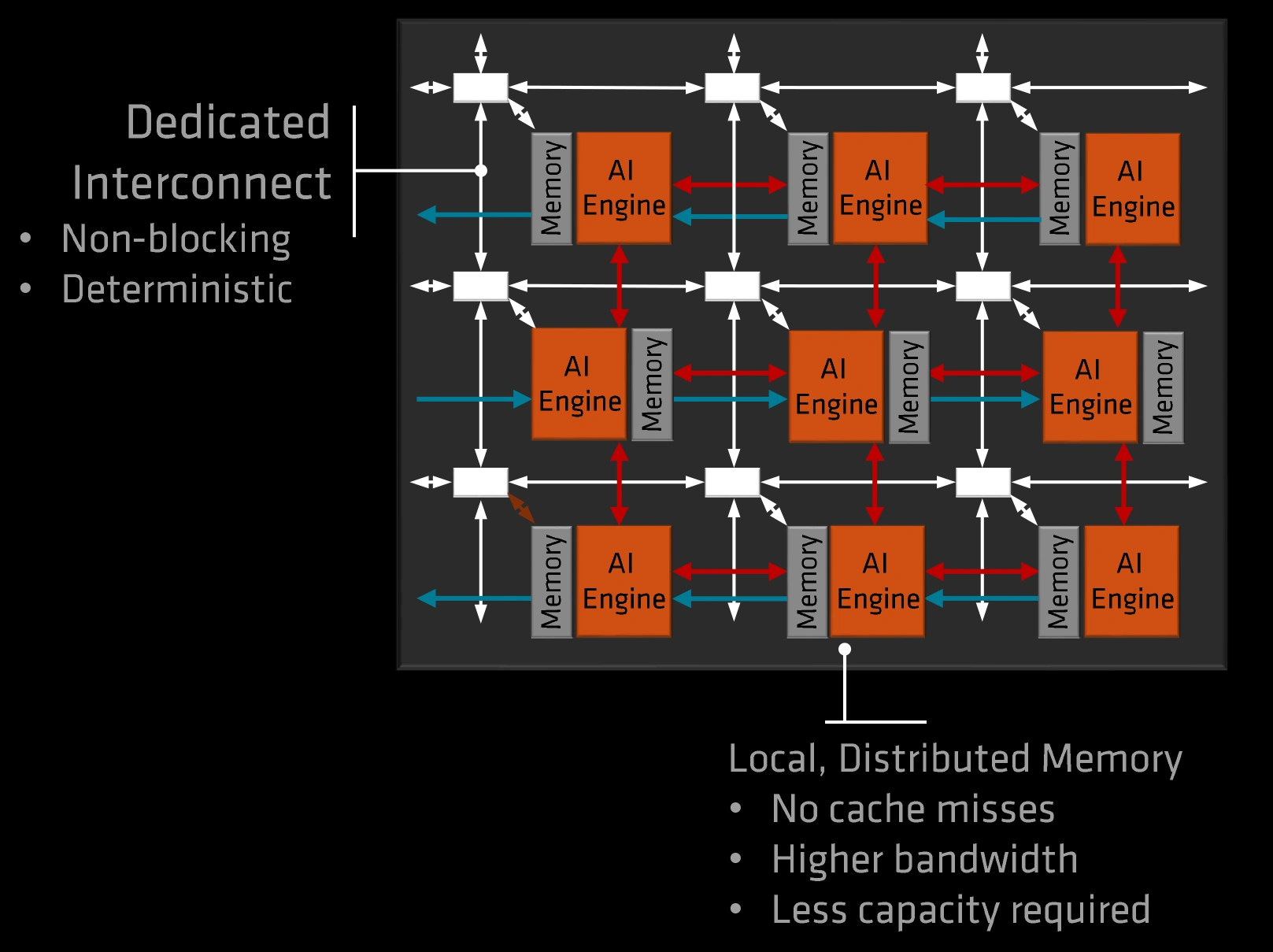
AMD XDNA : une grille fixe d’accélérateurs matriciels, simple et efficace pour de l’accélération embarquée !
Une histoire d’encodage de nombres
Une des difficultés principales en lisant les spécifications d’un accélérateur est de décoder sa puissance réelle. En effet, les constructeurs y vont chacun de leur sauce pour afficher des nombres toujours plus grands sans que cela fasse parfois grand sens (coucou, NVIDIA et les TFLOPS en matrice creuse, c’est-à-dire en comptant les opérations du type 0 +0, qui ne sont pourtant jamais exécutées !). Une partie de cette confusion vient du format des données, qui correspond à la manière de représenter un nombre sur un ordinateur.
Deux familles de format existent : les entiers et les flottants. Les premiers correspondent directement à un nombre sans virgule en suivant une logique identique à notre système décimal, précédé par un bit (une valeur 0 ou 1) indiquant s’il s’agit d’un nombre positif ou négatif. Il a l’avantage d’être très facilement manipulable pour effectuer des opérations courantes (addition/multiplication), mais ne permet pas de représenter des nombres « très grand » comme plusieurs milliards de milliards, ou très petit comme des millionièmes de pourcent. Pour cela, on utilise des flottants, qui se composent de deux entiers (et du bit de signe) : l’un, nommé mantisse représente effectivement une valeur, mais l’autre un exposant qui permettra de multiplier la mantisse par un nombre grand, moyen ou petit et ainsi obtenir des nombres très grands ou très petits ! Pour voir donner un ordre d’idée, avec 32 bits, l’entier maximal est 2 147 483 647 et le plus petit (le plus proche de zéro différent de 0) est 1, alors que le plus grand flottant est environ 3,40 suivis de… 38 zéros (!) pour un nombre le plus petit proche de zéro de 1,40 précédés de… 45 zéros avant la virgule. Diantre ! La chose est d’autant plus complexe qu’il est possible de modifier le nombre total de bits, et, dans le cas des flottants, de changer la répartition exposant/mantisse afin de mieux coller aux besoins d’un réseau : ainsi est né le BFloat16 (Brain Float-16) et, récemment, les flottants 8-bits qui ne faisaient pas partie du standard initial. À cela s’ajoutent les précisions entières : Int32, Int16, Int8 et parfois même Int4.

Un bit de signe (s), et le reste se partage entre exposant (exp) et mantisse.
Avec des représentations aussi différentes, les performances sont fatalement, elles aussi, différentes. Le flottant a l’avantage d’être plus précis, mais gourmand en ressources, alors que les entiers sont bien plus économes, mais nécessitent une opération nommée quantization pour transformer un réseau flottant en entier, ainsi qu’une seconde étape d’apprentissage supplémentaire pour tenter de corriger en partie la perte de précision induite par le passage en entiers. C’est donc sans surprise que les meilleures performances se retrouvent en Int4 sparse.... mais bon courage pour les exploiter dans des tâches d’entraînement ! C’est ainsi que les coprocesseurs d’IA tels ceux intégrés dans le Snapdragon X mesurent leur performance en TOPS et non en TFLOPS : pour économiser de l’énergie, seules les opérations Int sont accélérées à pleine vitesse. Couplé à l’économie réalisée en partageant la DRAM avec la DDR du CPU, ces accélérateurs réalisent l’exploit d’offrir des performances satisfaisantes en inférence pour une fraction de la consommation des GPU : bien pratique pour des tâches continues comme du sous-titrage automatique ou des effets applicables sur une webcam.
Quoi qu’en prétende le marketing, un réseau FP32 et un réseau INT8 sont deux choses différentes, quand bien même l’un serait dérivé directement de l’autre. Leur précision de prédiction est différente, tout comme leurs besoins hardwares. Il est donc aussi pertinent de les comparer l’un avec l’autre que de comparer FXAA et MSAA : si l’un comme l’autre servent à la même chose, les résultats comme le coût en performances peuvent être radicalement différents !
Les FPGA
Cela tombe bien, il existe également toute une famille de puces très efficaces sur le calcul entier et reconfigurable, c’est-à-dire adaptable facilement en fonction du réseau souhaité : les FPGA. Bien que plus gourmands qu’un accélérateur dédié, les FPGA sont capables de rivaliser avec les GPU sur le plan du ratio performance/consommation dès lors que les opérations s’effectuent en INT et non en FP. Il n’est donc pas surprenant de voir AMD, concepteur de CPU et de GPU, racheter en 2020 Xilinx, un fabriquant de FPGA, et installer dans ses APU Ryzen une partie « IA » XDNA directement transposée des FPGA Versal de la firme gobée. À l’inverse, Intel ayant racheté Altera en 2015 (l’autre concurrent), a plus ou moins manqué le tournant IA, ce qui explique en partie sa récente prise d’indépendance. De ce fait, l’accélérateur intégré sur Meteor Lake provient de Movidius, une start-up dévorée par les bleus en 2016.
Pour autant, les FPGA restent les plus discrets dans la course à l’IA, d’une part par des outils de programmation encore jeunes (ou un langage imbitable type VHDL pour encoder la chose !) et une flexibilité d’utilisation ayant du mal à se justifier par rapport à un accélérateur dédié… surtout lorsque Intel, AMD, Qualcomm et NVIDIA offrent déjà des solutions clef en main pour l’embarquée. Mais, qui sait, le futur révélera peut-être ces unités programmables aux yeux du grand public, comme Apple avait essayé de le faire sur un de ces Mac Pro, qui embarquait une de ces puces pour améliorer les performances en encodage vidéo !

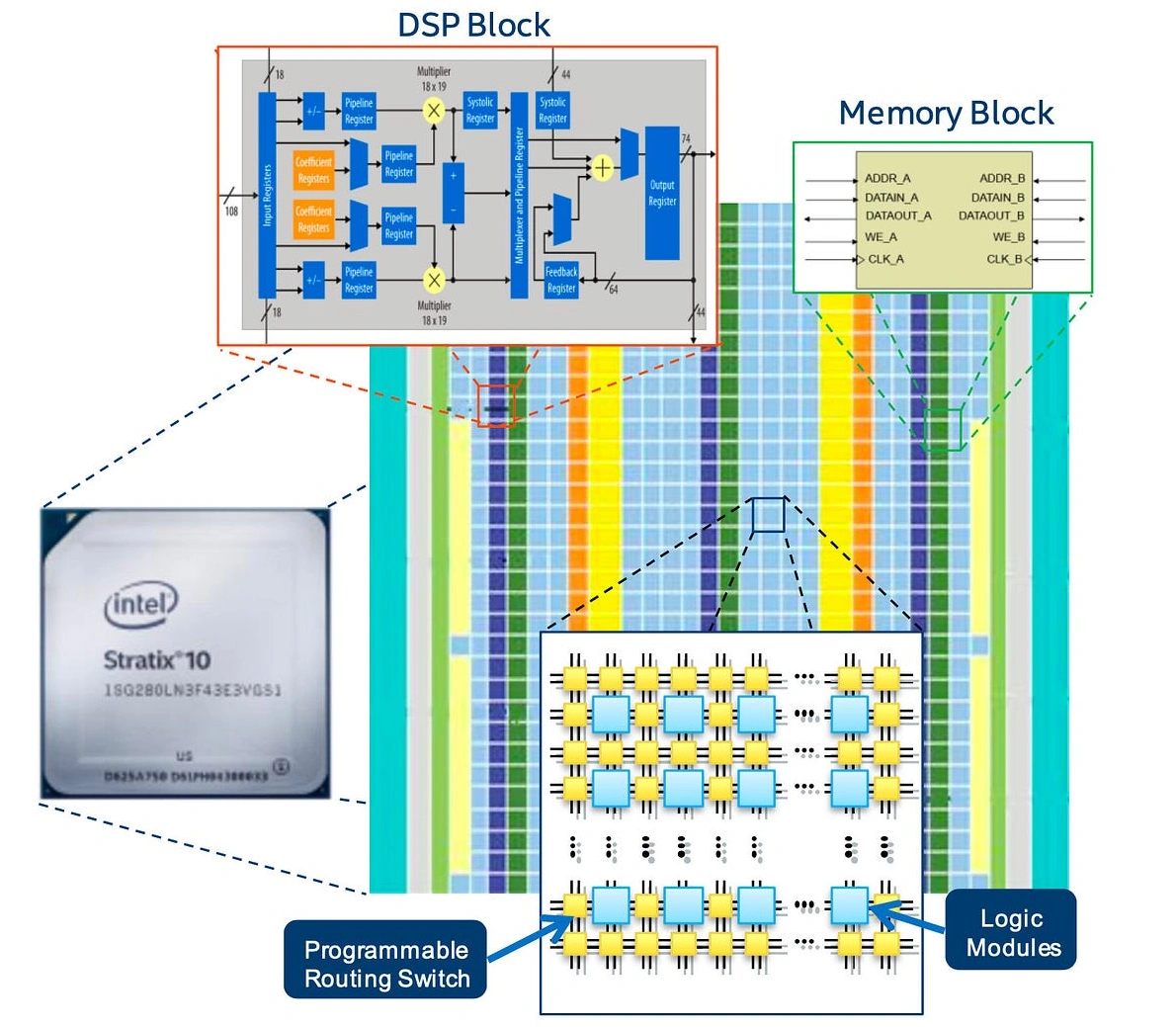
Une grille d’unités de calcul, des mémoires parallèles, des petits accélérateurs (DSP)… sur le papier, un FPGA a de sérieux arguments pour accélérer des réseaux de neurones ; et pourtant son utilisation reste rare face aux GPU et autres accélérateurs embarqués.
Avec toutes ces explications, vous voilà un peu plus armés pour déchiffrer la sauce marketing balançant des TOPS à tort et à travers ! Terminons ce dossier par un petit récapitulatif conclusif à la page suivante.



Merci beaucoup pour cet article, j'en avais bien besoin. J'ai découvert de nombreux détails, notamment la problématique du sur apprentissage.
Heureux de t'avoir été utile :D !
Pas encore lu, mais sur la vignette miniature de la colonne des dossiers, j'ai bien cru que c'était le majeur qu'il tendait. Ça commence bien...
"F*ck, la race humaine" 🤣
Merci pour ce dossier que j'ai lu avec beaucoup de retard. C'est complet, détaillé, et surtout pointu malgré la presque absence de maths.