
Préambule : une intelligence, vous dites ?
Commençons par la face la plus visible du bazar : la dénomination grand public de la chose. Si le terme d’Intelligence Artificielle fait penser — remercions les œuvres de science-fiction pour cela — à des machines disposant de libre arbitre par un truchement informatique, il ne s’agit pas (encore ?) de cela. Ce concept se nomme Intelligence Artificielle Générale, et désigne un tel programme qui pourrait apprendre à faire « tout », pourvu qu’on le lui montre. Si le sujet passionne les philosophes et pose des questions éthiques, il ne s’agit pas des IA actuellement vendues comme révolutionnaires par diverses firmes (quant à leurs capacités réelles, direction le paragraphe suivant !), nous fermons donc cette parenthèse sans scrupule.
Du coup, que renferme ce terme d’IA ? Eh bien, du machine learning , traduit en français par « apprentissage automatisé », ou encore « apprentissage statistique » : il s’agit d’une catégorie de programme dans laquelle le programmeur ne spécifie pas directement la méthode de résolution d’une tâche (par exemple, « superpose deux images en faisant la moyenne des pixels »), mais un moyen de trouver des similitudes entres données (« voici 50 images et, pour chacune, une version upscalée, trouve l’opération qui a été faite »). Ainsi, un algorithme de machine learning se caractéristique par un besoin de données initiales, permettant de forger la base de connaissances du programme. De par le caractère critique de ces données (et des questions de propriété intellectuelle qui y sont liées), la transparence vis-à-vis des données sources a été l’un des points critiques de la réglementation européenne concernant l’IA. Cette dépendance aux données vaut aujourd’hui à l’IA le doux sobriquet de PISS, pour Plagiarized Information Synthesis System, ou « Système de synthèse d’informations plagiées » reflétant davantage le cœur du schmilblick : recracher les tendances présentes dans la majorité des données analysées… ce qui est loin d’être un calque parfait de l’intelligence humaine.

Si les réseaux de neurones se sont imposés comme la méthode canonique d’IA de ces dernières années, elle n’est pas la seule — et de loin. Les machines à support de vecteurs, k-voisins (kNN), k-means ou encore les arbres de décisions sont d’autres familles d’algorithmes entrant dans la catégorie du machine learning. Cependant, du fait d’une précision plus basse, d’une plus grande difficulté d’adaptation aux architectures matérielles actuelles et/ou d’une plus grande difficulté d’étalonnage, ces méthodes ont perdu en popularité au profit des réseaux de neurones, c’est pourquoi nous ne causerons plus que de ces derniers dans la suite de ce dossier. De même, il existe des méthodes d’apprentissage dites non-supervisées dans lesquelles l’apprentissage de l’algorithme se fait sans consigne initiale (c’est-à-dire sans mention explicite du résultat final) ; nous les passerons également sous silence pour des questions de lisibilité !
Du Perceptron à ChatGPT
Si vous êtes probablement très nombreux à connaître ChatGPT, vous êtes très probablement nettement moins à connaître le Perceptron. Si ses consonances pourraient rappeler une rubrique d’un site de hardware francophone bien connu, le terme n’a rien à y voir puisqu’il désigne le premier algorithme de machine learning proprement dit. Alors que l’explosion de l’IA aux yeux du grand public n’a que quelques années, ses premiers pas débutent au milieu du siècle dernier, principalement à partir de résultats… théoriques. Ce n’est qu’une fois le hardware suffisamment performant que la recherche s’est mue de fondamentale à appliquée, et a pu mener à la construction des réseaux profonds et, désormais, d’architectures plus complexes encore. Voyons cela !
Des débuts dans les années 60 !
Nous vous l’expliquions en introduction, l’IA moderne est un programme informatique, défini formellement comme une famille d’algorithme : une liste de course composée d’un nombre fini de choses à faire par une machine. Et, comme son nom l’indique, les réseaux de neurones sont inspirés du vivant en reprenant des idées des neurones présents dans les systèmes nerveux. Leur fonctionnement est évidemment trop complexe — et votre humble serviteur absolument ignorant de ce pan des sciences — pour être détaillé ici, mais ce que les informaticiens en ont extrait est la vision simplifiée suivante :
- un neurone prend ses informations de multiples neurones voisins (via ses dendrites)
- un neurone traite ces informations pour en faire la synthèse
- un neurone transmet ce résultat à un ou plusieurs voisins (via l’axone, relié aux dendrites d’autres neurones par des synapses)

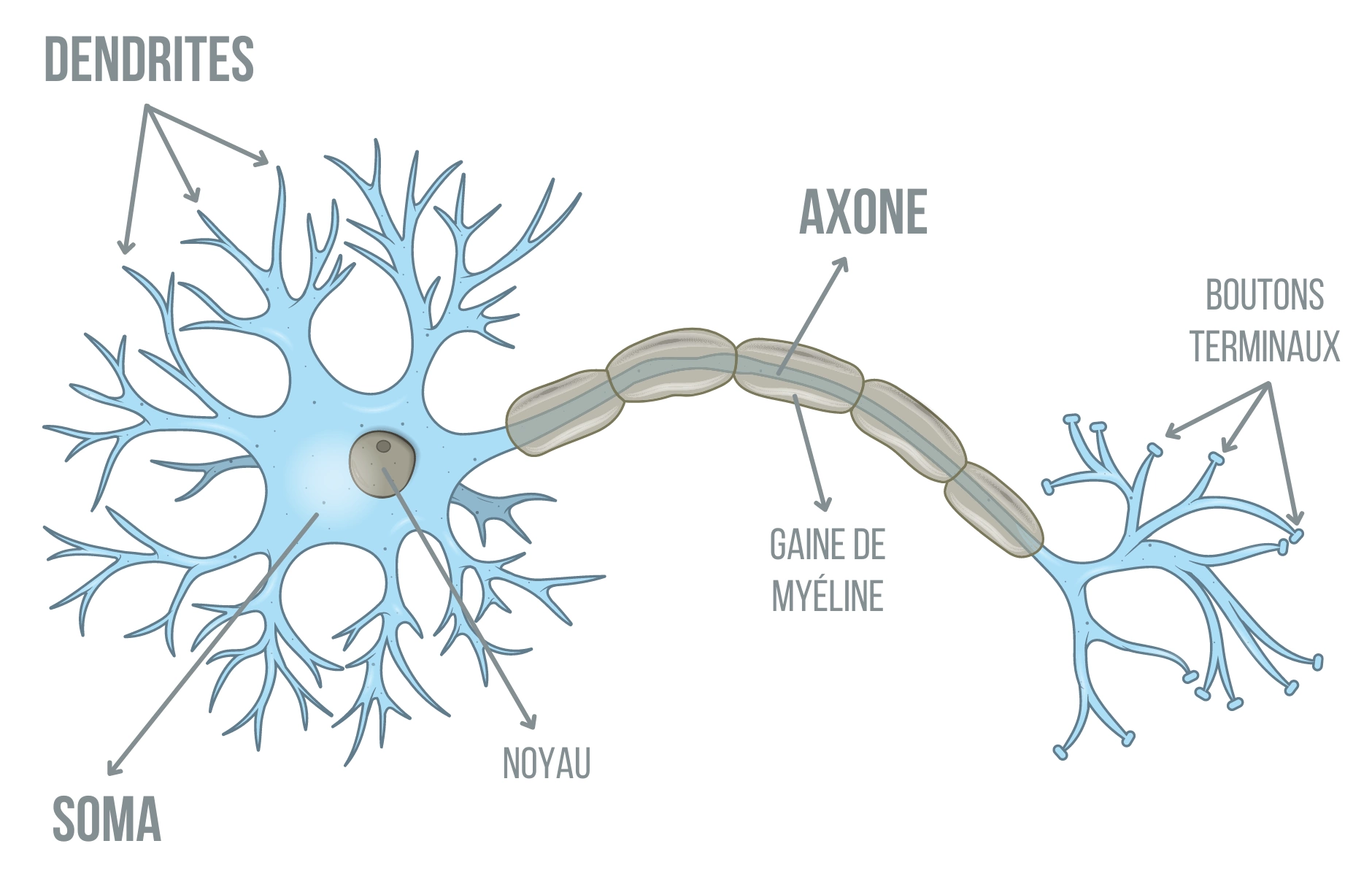
Pour plus de détails, nous vous renvoyons au Laboratoire Parole dont ce schéma est issu
Dès les années 1940, cette structure est mimiquée par une machine (construite en 1957) que l’on nomme perceptron, et qui servait (déjà !) à des tâches de reconnaissance d’image — d’une définition de 20x20 sur la version Mark I, attention les yeux ! De nos jours, le perceptron désigne le programme implémenté par ses machines : un classificateur binaire, c’est-à-dire un programme répondant oui on non à une question, composés de neurones (artificiels).
En entrée de chaque neurone, des nombres x1, x2, ... . En sortie, « oui » ou « non ». Et en interne, la soupe secrète mathématique : on multiple chaque entrée par un nombre (nommé poids et usuellement noté w1, w2,…) et on somme tous ces résultats, en plus d’un biais b, tout ce beau monde étant possiblement positif comme négatif, voire nul. On obtient alors encore un nombre, que l’on convertit en réponse par une fonction d’activation qui est ici une simple comparaison : au-dessus de 0, c’est oui, en dessous, c’est non ! C'est ce que l'on nomme un booléen : une quantité qui ne peut prendre que deux valeurs : 0 (faux) ou 1 (vrai).
Pour les plus matheux, le neurone calcule θ[Σ (xi wi) + b)], soit theta (notre fonction d'activation) appliqué à la somme des xi multipliés par les poids wi et du biais b, une formule qui n’est pas sans rappeler un produit scalaire. Si vous n’avez rien suivi, pas de panique, ce sera la seule formule matheuse de ce dossier !
Multiplier deux nombres pour les rajouter à un troisième, cela porte le doux sobriquet de Multiplication-Accumulation, ou MAC, et parfois de FMA (Fused Multiply-Add) en fonction de la précision de la multiplication. Or, en ajoutant ensemble les sommes des multiplications entrée x poids, on obtient exactement.... des MAC. Ainsi, cette opération (une multiplication suivie d’une addition) est la première intégrée dans tous les bidules accélérateurs d’IA.

Le voilà, le neurone informatique !
Dans ce cas, vous noterez qu’un seul neurone est présent. La première évolution a ensuite été de le répliquer dans le sens de la largeur : plusieurs neurones opèrent en parallèle sur les mêmes xi d’entrée, formant une couche cachée. Puisque chacun de ces neurones possède ses poids et son biais, le produit scalaire précédent composé de MAC se transforme en un produit matrice-vecteur (le vecteur étant l’entrée, et la matrice constituée des poids d’une couche). Quelqu’un a parlé des Tensor Core, qui accélèrent justement les produits de matrices ? Pas si vite, matelots, nous ne sommes que dans les années 80 !
En sortie, un unique neurone condense les résultats issus de la couche cachée précédente :

On commence à se rapprocher des structures de réseaux profonds… patience, ça arrive !
Un potentiel énorme
Outre l’algorithme en tant que tel, ce sont ses propriétés qui ont fasciné, notamment sa capacité d’approximation universelle : avec un nombre suffisant de neurones dans cette couche cachée, à peu près n’importe quoi (tant que la sortie reste « sage » par rapport aux entrées, correspondant à la notion mathématique de contiguité) est approchable, et ce avec n’importe quel niveau de précision. C’est-à-dire qu’avec un nombre infini de neurones et des données d’apprentissage illimitées, le perceptron est tout-puissant. Pour autant, les années 1980 n’ont pas vu d’explosion du machine learning ! La faute incombant à la différence terrible entre théorie et pratique : si, en théorie, il est possible de faire faire tout et n’importe quoi à un perceptron à une couche cachée, cela ne dit pas la quantité de neurones, qui devient rapidement énorme, ni le temps à passer pour choisir les bons poids et biais. À une époque où l’informatique est loin des TFLOPS actuels, cette convergence restait inexploitable.
Or, dans les années 1990, une nouvelle manière d’assembler des perceptrons a le vent en poupe : en empilant les couches, plutôt les faisant grandir à l’infini. On parle alors de perceptron multicouche, ce qui a le double avantage d’être tout aussi expressif (i.e. puissant dans leur capacité à apprendre) tout en étant plus facilement entraînable, car moins gros : c’est la genèse des réseaux de neurones profonds (DNN) modernes. Dans le même temps, d’autres fonctions d’activations que le passant/pas passant voient le jour (citons le ReLU, qui a le bon avantage de transmettre un entier positif et non plus un booléen), ce qui simplifie davantage l’implémentation sur les machines d’époque tout en améliorant la précision.

Un perceptron à 3 couches cachées, 5 entrées et 4 sorties
Et l’inférence dans tout ça ?
Le perceptron multicouche peut être vu comme le modèle de base dont dérivent tous les réseaux actuels. Pour l’utiliser, c’est-à-dire pour réaliser la tâche apprise au préalable — on parle alors d’inférence — il faut traverser toutes les couches une à une. En partant de l’entrée encodée sous la forme d’un ensemble de nombres (qu’il s’agisse de texte, d’image, de sons, etc...), l’action des neurones consiste à multiplier et sommer tout ce beau monde ensemble, puis appliquer la fameuse fonction d’activation pour obtenir un nouvel ensemble de nombres (possiblement de plus grande ou plus petite taille que celui des données de départ), nommé résultat intermédiaire. L’opération se répète couche après couche, jusqu’à la dernière qui a pour caractéristique de comprendre autant de neurones que de nombres en sortie. À la fin, il ne reste plus que le résultat de la digestion des multiplications/activations successives de notre entrée, qui est interprétée différemment selon l’utilisation du réseau : son, image, probabilité de présence, etc. Ta-da ! Pour l’intelligence, par contre, difficile de la voir depuis cet angle...
En résumé, la genèse des réseaux de neurones remonte aux années 1960, puis 1980, sans pour autant que le matériel ne puisse apporter la puissance de calcul nécessaire pour révéler leur plein potentiel. Rendez-vous page suivante pour comprendre comment le perceptron a évolué pour donner les DNN actuels !



Merci beaucoup pour cet article, j'en avais bien besoin. J'ai découvert de nombreux détails, notamment la problématique du sur apprentissage.
Heureux de t'avoir été utile :D !
Pas encore lu, mais sur la vignette miniature de la colonne des dossiers, j'ai bien cru que c'était le majeur qu'il tendait. Ça commence bien...
"F*ck, la race humaine" 🤣
Merci pour ce dossier que j'ai lu avec beaucoup de retard. C'est complet, détaillé, et surtout pointu malgré la presque absence de maths.