
Un réseau oui, mais pas n’importe lequel !
Avoir des couches capables de traiter correctement les informations spatiales et temporelles, c’est bien ; encore faut-il avoir une architecture de réseau capable d’en tirer parti ! Au fur et à mesure des années, les réseaux ont évolué, gagné en taille et en précision : nous résumons ainsi ici une petite sélection totalement partiale de réseaux ayant, en leur temps, marqué un pas de plus vers l’IA moderne. En piste !
LeNet (1998)
Le perceptron multicouche, cela vous parle ? Espérons-le, puisque nous en avons causé une page plus tôt… et qu’il est exactement ce qui compose LeNet, à l’exception près d’utiliser de mixer convolutions, pooling (sélection) et couches denses classiques (et d’utiliser une fonction d’activation nommée tangente hyperbolique). Ce réseau a été développé par un certain Yann LeCun, français (cocorico !) de son état, prix Turing en 2018 (équivalent du Nobel, ce n’est pas de la gnognotte !) et actuellement Chief AI Scientist à Meta : un gars plutôt respectable ! En fait, le papier qui décrit son architecture (du réseau, pas du monsieur…) est si fondateur que Google lui recense 64 347 citations, un montant astronomique pour un article de recherche ! Pour en revenir au réseau, ce dernier prend en entrée une image de 28 px par 28 px en nuances de gris, et reconnaît les chiffres (0 - 9), permettant de détecter automatiquement les codes postaux avec un taux d’erreur de seulement 1 % (oui, en 1998 !). En fait, la sortie est composée de 10 nombres représentant la probabilité que l’image représente l’une des 10 classes apprises (une par chiffre), le montant le plus grand indiquant le chiffre le plus probable d’avoir été rédigé. Cela correspond à la sortie d’une tête de neurones dense de 3 couches, au-dessus de 2 couches de convolutions séparées par une couche de sélection (pooling) chacune.

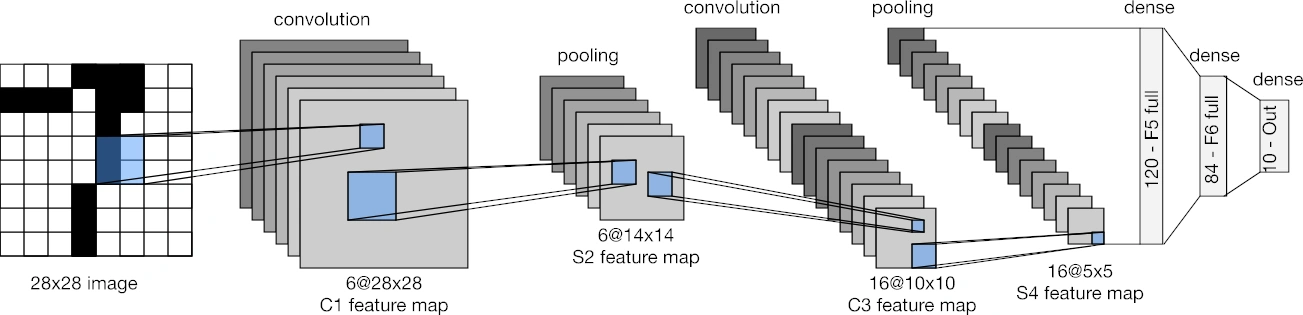
Lenet, en image ! (Crédit : d2l.ai)
AlexNet (2012)
Plus grand, plus profond, plus puissant, telle aurait pu être la devise d’AlexNet. Reprenant les idées de LeNet, AlexNet bénéficie de la puissance de calcul accrue de son époque pour passer à des images de taille 224x224 et en couleur (donc 3 canaux RGB en entrée au lieu du noir seul), et sort une classification de l’image parmi 1000 classes. En fait, ce réseau fut créé pour participer à une compétition de machine learning populaire à l’époque reposant sur le jeu de données ImageNET (vainqueur de la version ILSVRC-2012) et reposait sur pour son entraînement sur… une implémentation CUDA ayant moulinée 5-6 jours sur deux GTX 580 3 GB, en partageant de manière astucieuse les couches pour bénéficier des 6 Gio de mémoire au complet. Au jeu des citations, le papier fondateur en accumule à l’heure actuelle 155 225, ce qui s’explique par une précision de 15,3 % sur les 5 premiers résultats (dans 84,7 % des images, le réseau sortait la réponse correcte parmi ses 5 suggestions les plus probables), ce qui mettait une tarte (10 points !) aux ténors de l’époque. Au niveau de sa structure, le réseau compte 5 couches de convolution et une tête composée de 3 couches denses (bien plus larges que LeNET, on parle de 4096 neurones ici, contre 120 maximum en 1998), avec la particularité d’utiliser une technique nommée dropout pour limiter la présence de connexions inutiles (faibles poids) au sein des couches denses, et une fonction d’activation ReLU.

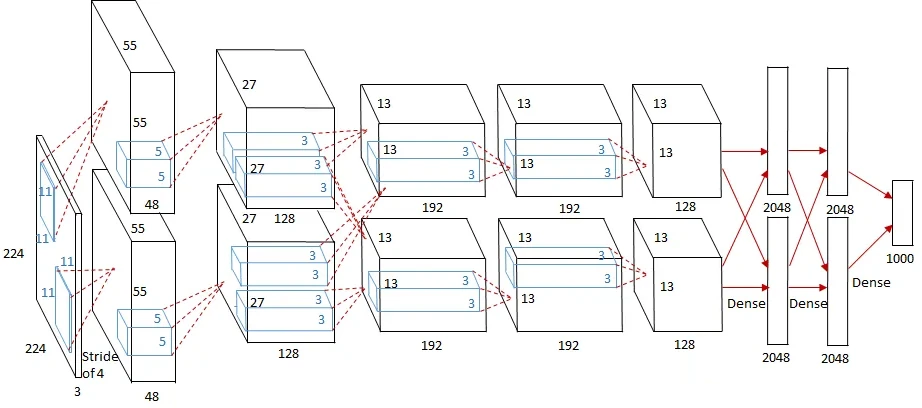
L’achitecture d’AlexNet en image : un cube représente une sortie d’une couche, par exemple 55x55 éléments x 48 features pour la première sortie, immédiatement après l’image d’entrée 224x224 px sur 3 canaux. Notez les couches parallèles (sens de la hauteur), une optimisation scindant en deux les couches pour faire tourner le gros réseau sur deux GTX 580 3 GB en parallèle. (Crédit : medium.com)
VGG (2014)
Toujours dans les CNN, VGG représente leur aboutissement en allant toujours plus loin et plus profond. L’originalité a ici consisté à réduire au maximum la fenêtre de vue des neurones à un carré de 3 px par 3 px (contrairement au 5x5 ou 11x11 plus populaires auparavant), pour gagner en profondeur : pas moins de 16 ou 19 couches de convolutions sont présentes (selon la variante VGG16 ou VGG19), suivies d’une même tête de 3 couches denses. Tout le pataquès habituel se répète : le réseau gagne ILSVRC son année avec une précision de 92,7 % sur le jeu de donnée ImageNet, et son article introducteur tope les 122 825 citations ; sachant que le GPU retenu pour l’apprentissage fut une Titan Black (NVIDIA toujours, mais quelle surprise !), et que le processus a duré 2 à 3 semaines !

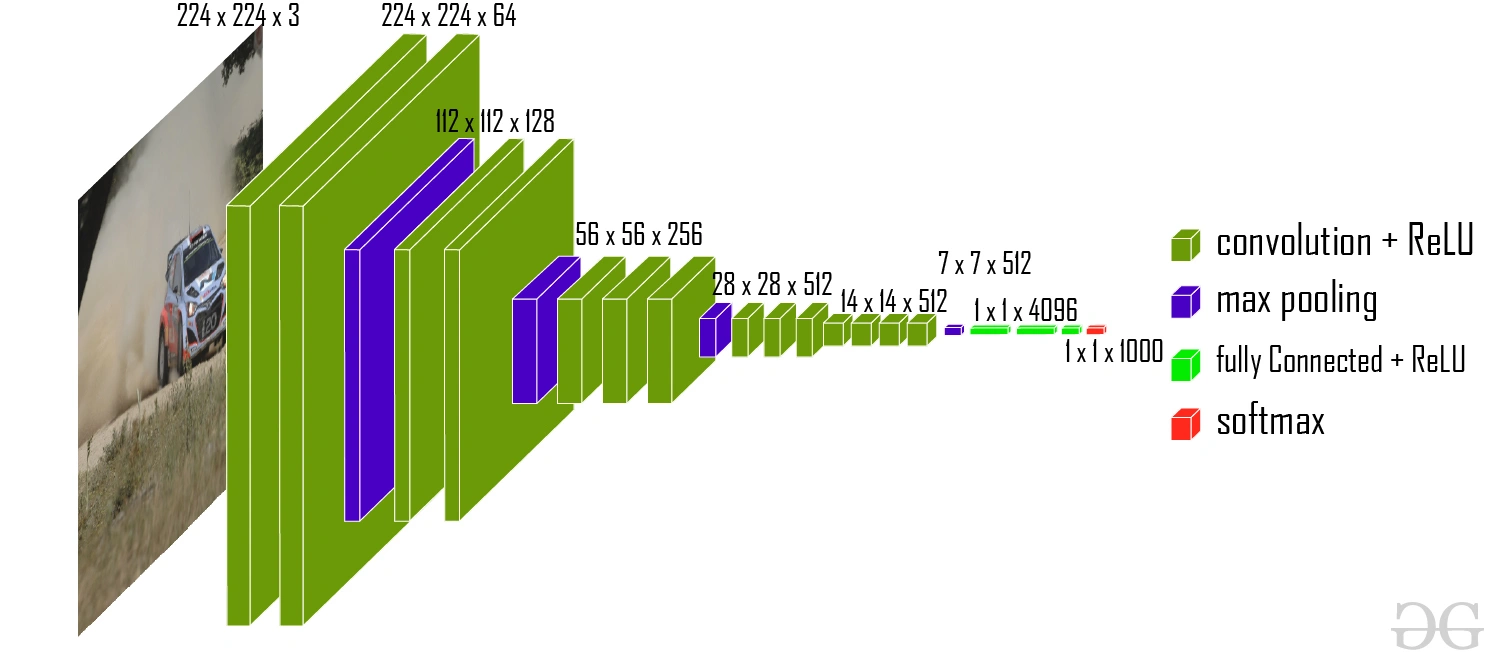
L’architecture de VGG16 (crédit : GeekForGeeks)
ResNet (2015)
Pour vous donner une idée de l’ampleur de ResNet, son papier est tout bonnement celui le plus cité du Machine Learning du XXIe siècle avec 217 234 citations à l’heure actuelle selon Google. La raison est compréhensible : les chercheurs se sont rendu compte qu’empiler les couches pour aller plus profond encore que VGG avait un effet contre-productif, contrairement à ce qui les mathématiques prétendent (plus le réseau est gros, plus il est expressif et donc plus il est performant). La raison provient de l’entraînement, que nous détaillons dans deux pages : à faire trop profond, le réseau devient trop complexe pour correctement apprendre, si bien que certaines couches (les premières du réseau) ne sont que très peu modifiées, et ainsi inaptes à leur tâche. Ainsi, le principe de ResNet a été d’utiliser des résidus, c’est à dire des connexions coupant plusieurs couches pour rapporter des informations potentiellement perdues lors des transformations vers les couches externes.

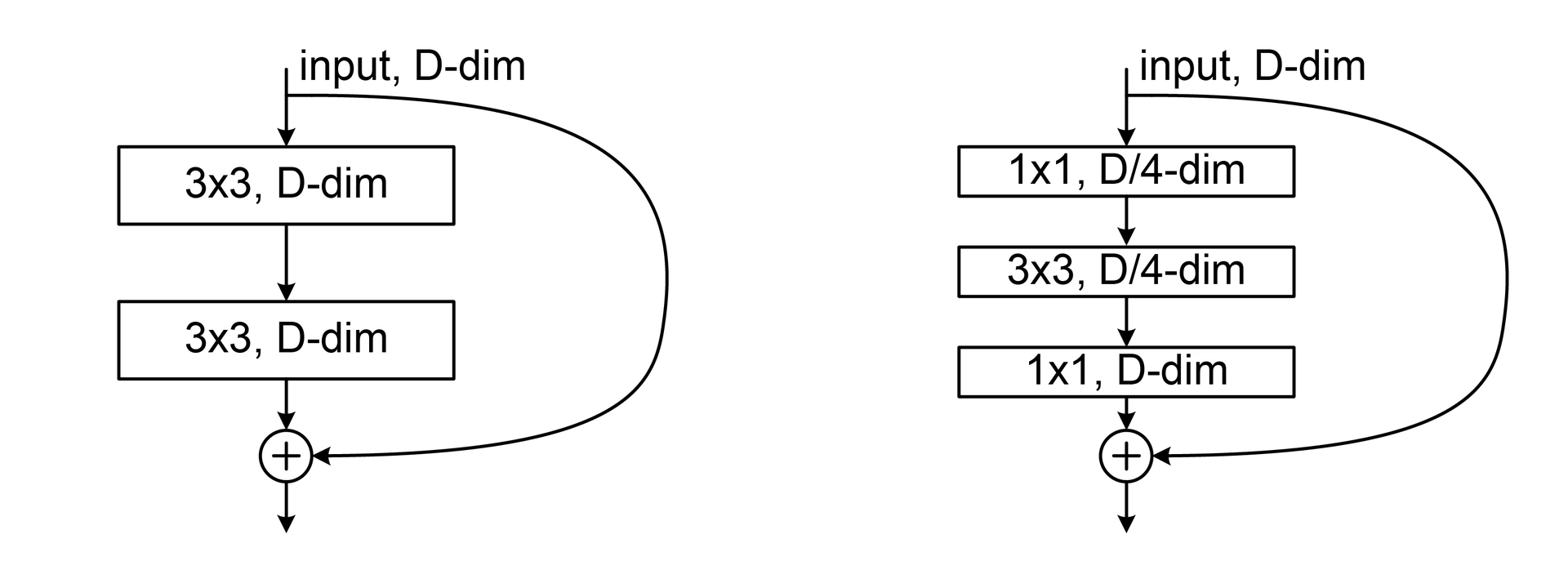
Au lieu d’utiliser une couche, ResNet utilise un bloc résiduel composé de 2 ou 3 couches et une liaison résiduelle (flèche courbe sur la droite), qui est sommée avec les sorties du bloc (Crédit image : By LunarLullaby—Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=131466161)
Cela a l’avantage de faciliter grandement l’entraînement, car les couches profondes sont alors mathématiquement rapprochées et donc plus facilement corrigibles du fait de ces liens. De ce fait, ResNet a pu exploser le nombre de couches en poussant le curseur jusqu’à 152 couches, portant sa précision à 4,49 % sur ImageNet et remportant ILSVRC 2015. Dans le même état d’esprit des connexions résiduelles, U-Net (2015) propose lui aussi des liaisons résiduelles entre couches, cette fois-ci via une architecture commençant par (classiquement) diminuer la taille spatiale des données, puis réaugmenter cette dernière. De ce fait, les liaisons résiduelles (qui ne peuvent être effectuées qu’entre données de même dimension) sont effectuées entre les premières et les dernières couches, puis entre celles du milieu-début et du milieu-fin et ainsi de suite, d’où de nom de réseau en « U » : la première barre descendante correspond à la réduction de taille, suivi par une-réaugmention ; les liaisons résiduelles étant alors des lignes horizontales au sein de ce même U.

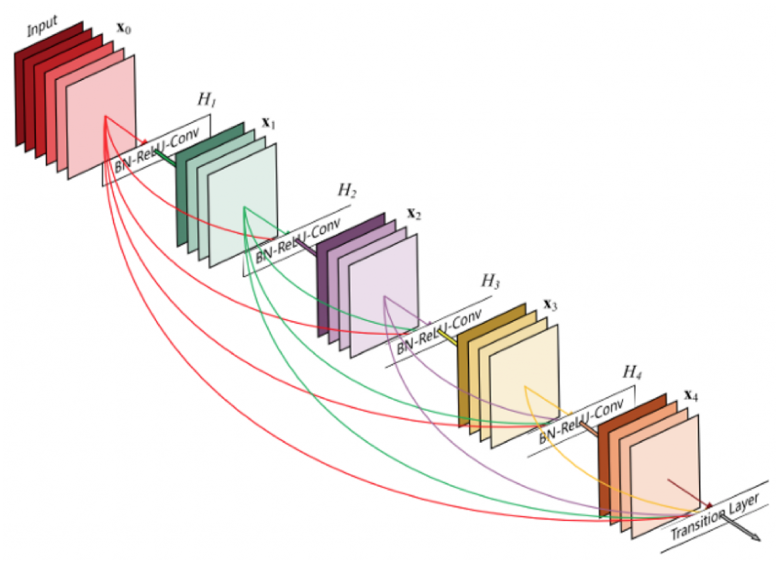
Un extrait de ResNet : les blocs résiduels (ici représenté par « BN-ReLU-Conv ») reçoivent un mix des informations de la couche immédiatement précédente, mais également des toutes celles avant lui.
Vous l’avez sûrement constaté, l’IA ne s’est pas arrêtée en 2015, loin de là ! En revanche, c’est là que s’arrêtent les modèles compréhensibles sous l’angle du perceptron multicouche : au-delà, nous allons devoir nous contenter de descriptions plus haut niveau afin de (tenter) de résumer le schmilblick… C’est parti, dès la page suivante !



Merci beaucoup pour cet article, j'en avais bien besoin. J'ai découvert de nombreux détails, notamment la problématique du sur apprentissage.
Heureux de t'avoir été utile :D !
Pas encore lu, mais sur la vignette miniature de la colonne des dossiers, j'ai bien cru que c'était le majeur qu'il tendait. Ça commence bien...
"F*ck, la race humaine" 🤣
Merci pour ce dossier que j'ai lu avec beaucoup de retard. C'est complet, détaillé, et surtout pointu malgré la presque absence de maths.