
Zen 5, une nouvelle fondation architecturale !
Comme indiqué en préambule de ce dossier, AMD intronise donc une nouvelle microarchitecture. S’il n’est pas question de faire table rase du passé comme ce fût le cas au lancement de Zen premier du nom, les modifications sont tout de même suffisamment significatives pour permettre selon le concepteur, des gains moyens d’IPC à 2 chiffres ainsi que poser les bases des futures évolutions. Débutons par les objectifs qui auraient présidé aux choix architecturaux du concepteur texan !


Comme à l’accoutumée, l’idée est (évidemment) de faire mieux que la génération précédente, sans pour autant déséquilibrer le cœur : dans un intérêt économique (et de consommation énergétique), il est inutile de doper aux hormones une seule « partie » du CPU, sous peine de le voir freiné par les autres éléments. Comme pour la haute-fidélité, le résultat global dépend du maillon le plus faible de la chaîne de traitement. Dans cette mouture Zen 5, l’accent a ainsi été mis sur la performance single et dual-thread (le cœur du cœur !), un choix logique vu les améliorations des caches que proposait Zen 4. Pour cette version AMD annonce avoir travaillé sur une nouvelle fondation micro-architectural : comprenez par là que certains choix devraient être sublimés par Zen 6.... Mais revenons à nos moutons. Tout comme Zen 4, ce Zen 5 peut également faire dans l’hétérogène avec un dérivé Zen 5c plus dense, mais dont l’usage est pour le moment restreint aux APU mobiles : place à la performance sur PC du bureau, au moins dans un premier temps ! Dans la même veine, le design est également prévu pour être gravé en 3 nm (en plus du 4 nm à l’œuvre dans cette série 9000), de quoi laisser présager des évolutions côté serveur.
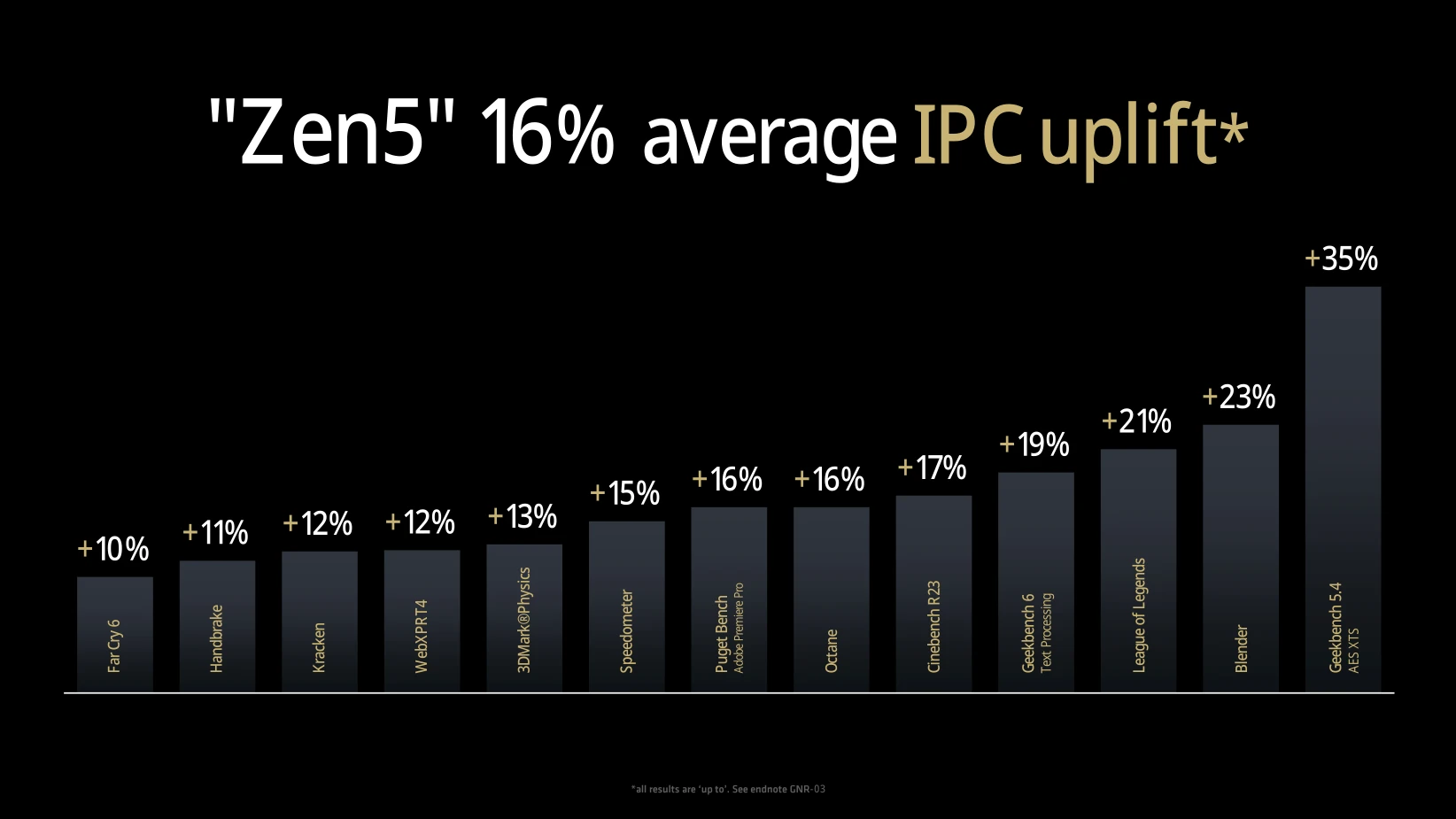
Petite nouveauté de Zen 5, les unités de calculs vectorielles sont configurables pour opérer soit en mode 256-bit (le précédent double pumping), soit 512-bit selon la version intégrée dans chaque produit, limitant de fait la performance de l’AVX-512 dans le premier cas. Un choix qui se justifie sur mobile notamment, où l’importance de ces instructions vectorielles est bien moindre à contrario de la puissance électrique absorbée, tout en laissant la possibilité à la firme de réutiliser le même cœur sur desktop/serveur sans restriction, comme c’est le cas ici. Avec ces idées de designs en tête, les rouges annoncent fièrement un gain moyen d’IPC de 16 % en comparant un Ryzen 9 9950X à un Ryzen 7 7700X à 4 GHz (devinez donc comment l’indice a été calculé sur les tâches multicores…). Comment cela est-il possible ? La réponse directement sur cette page !

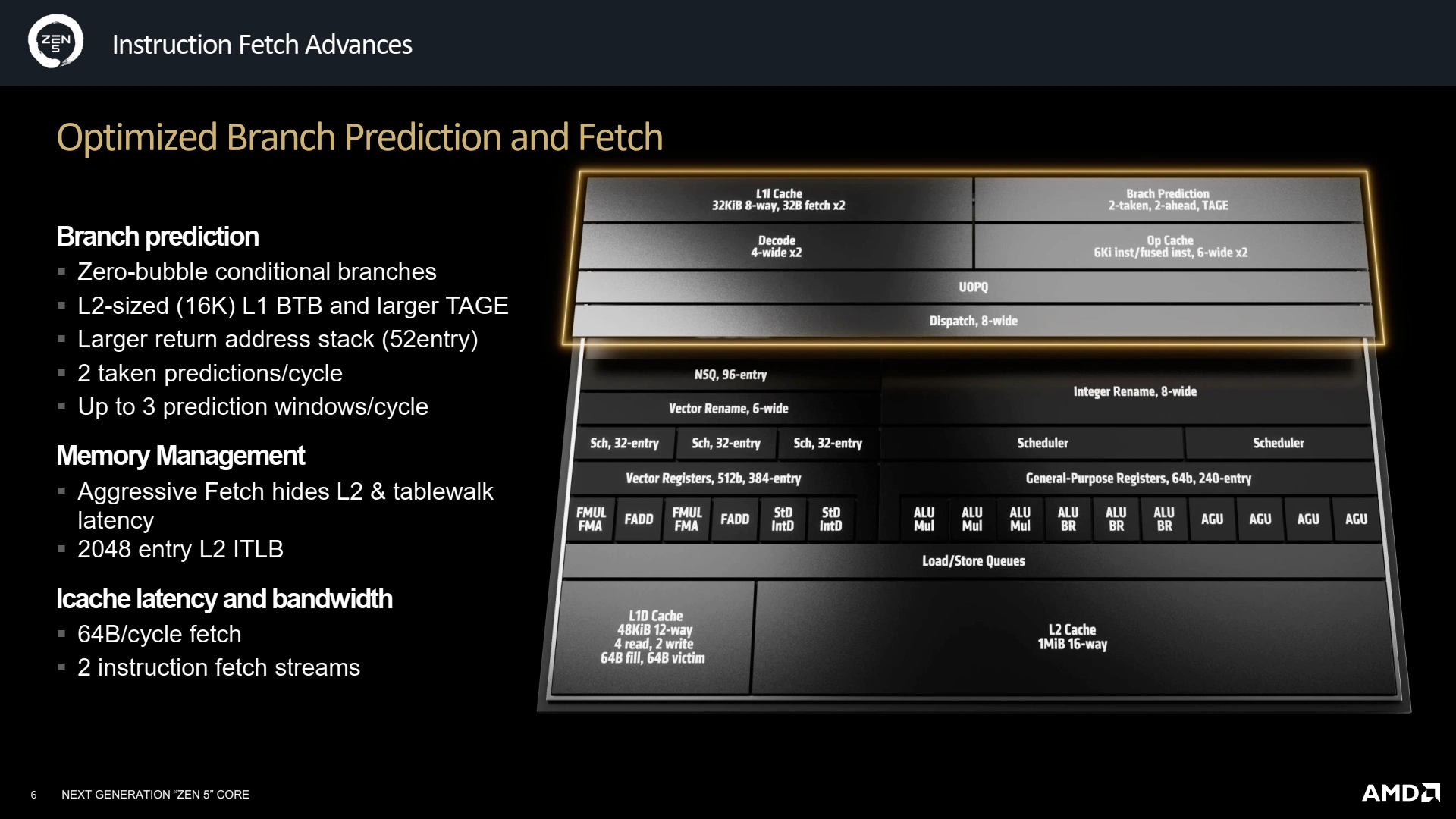
Un Front-End toujours plus agressif
Le Front-End est la partie du CPU responsable d’alimenter les unités d’exécution du Back-End : il comprend le décodage (toute première étape que le code subit, transformant des données brutes en une liste d’instructions, puis de micro-instructions compréhensibles atomiquement par le CPU) ainsi que la prédiction de branchement (paragraphe suivant). Similairement à ce que le concurrent Intel propose depuis quelques générations sur ses microarchitectures (efficientes comme performantes), AMD a opté pour un double pipeline de décodage (grosso modo la duplication de ce qui était fait sur Zen 4), ce qui permet de travailler sur deux flux indépendants d’instructions, bien pratique dès lors que le CPU est intriqué dans de multiples branchements conditionnels spéculatifs… ainsi que pour le SMT ! Les divers buffers accueillant les instructions décodées sont également mis à niveau, avec un OpCache recevant les instructions décodées 33 % plus grand, et opérant désormais sur des instructions au lieu des plus petites micro-instructions (implémentation de Zen 4), afin de gagner en densité. Le tout permet ainsi d’atteindre un faramineux 12 instructions décodées par cycle au maximum : ça décoiffe !


L’autre pendant du Front-End est la prédiction de branchement, qui permet d’éviter d’attendre certains résultats intermédiaires avant de commencer à décoder (puis exécuter) la suite du programme ; une opération cruciale pour les performances puisque c’est elle qui extrait un nombre d’instructions suffisant pour peupler le ReOrder Buffer (alias ROB) et, ainsi, nourrir toutes les unités de traitement. Depuis l’invention du TAGE par André Seznec (cocorico), l’essence du prédicteur n’a pas beaucoup changé, et Zen 5 doit faire comme tout le monde : un plus gros cache L1 d’historique des branchements (BTB), qui passe à 16K entrées, une taille de L2 ! Le L2 est quant à lui plus modeste avec 8K entrées, il fallait bien économiser de la place quelque part. Pourquoi ce choix d’un L2 plus petit que le L1 ? En fait, la prédiction a été gonflée pour pouvoir sortir 2 branchements prédits par cycles (sur 3 fenêtres de prédiction), ce qui nécessite de doubler l’étage de décodage ainsi que le BTB — une entrée pour chaque prédiction, quoi ! Toujours du côté des évolutions, la pile des retours d’adresses, utilisée pour les sauts de fin de routines, croît de 20 entrées pour culminer à 52 en tout. Enfin, la prédiction de branchement conditionnel se fait désormais sans latence supplémentaire, bien que la latence en cas de missprediction soit en légère augmentation… sans que nous ayons de valeur exacte officiellement. Officieusement, la valeur culminerait à 13 cycles en moyenne.

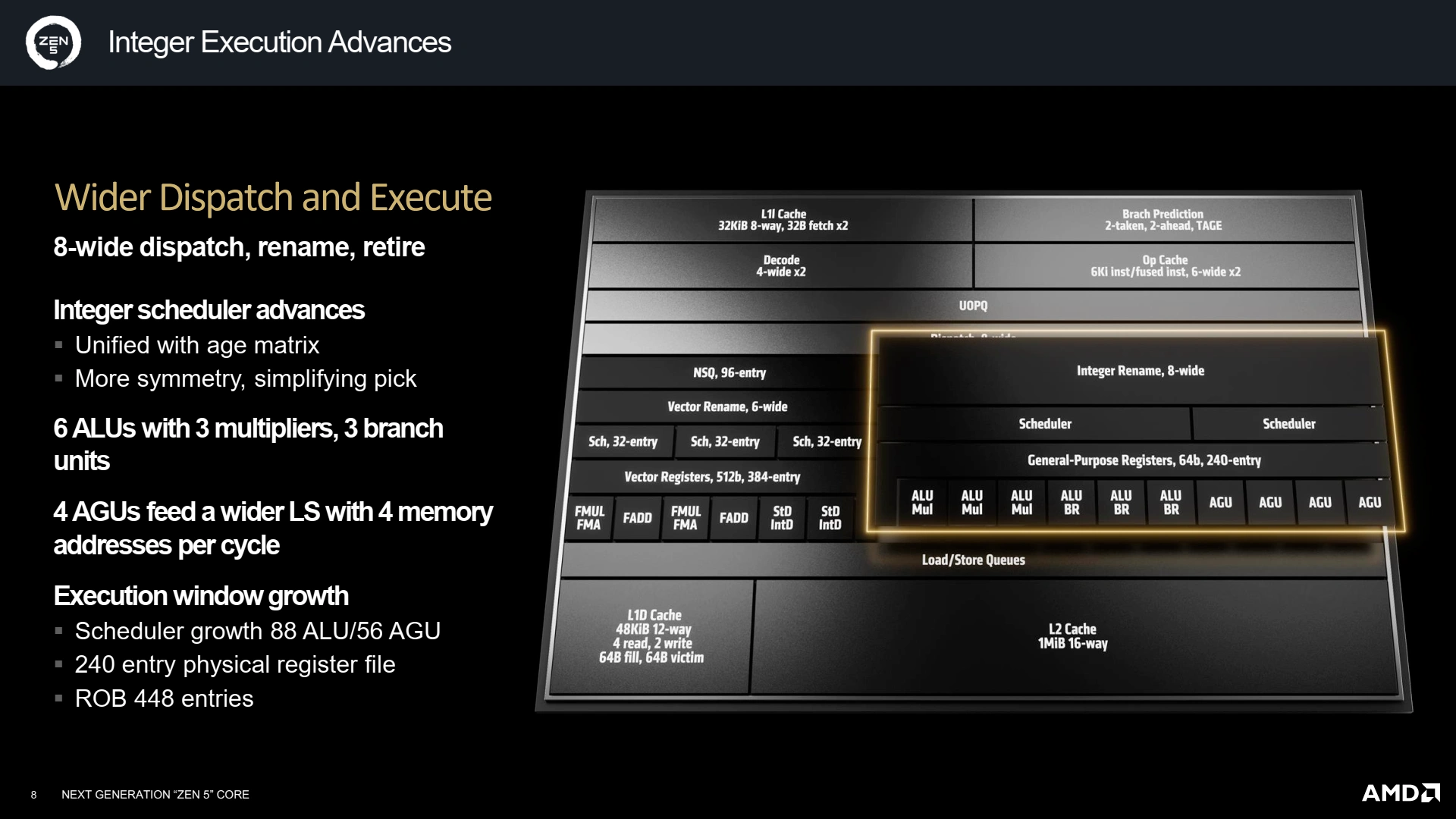
Un Back-End gonflé à l’AVX-512
Si le Front-End grossit, c’est bien pour que le Back-End réussisse à extirper toujours plus de parallélisme des micro-ops décodées et/ou prédites pour pouvoir les exécuter en même temps et ainsi améliorer l’IPC. Mais, pour cela, il faut un nombre plus grand d’unités de calcul/branchement, et un ROB plus gros histoire de retenir suffisamment de micro-ops et ainsi pouvoir en ordonnancer un nombre toujours plus grand par cycle. Cela tombe bien, ce dernier est passé de 320 entrées à 448 sur Zen 5 ! Mécaniquement, les diverses autres mémoires grandissent tel le nombre de registres vectoriels (384 entrées) et entiers (240).
La structure générale du pipeline n’évolue pas, avec une partie gérant l’arithmétique entière et les branchements, secondée par un coprocesseur gérant les instructions flottantes et leurs chargements/rangements. Commençons par la gestion des entiers : AMD a unifié son scheduler (composant chargé d’assigner aux micro-ops disponibles une unité de calcul), ce qui permet de simplifier son implémentation avec une matrice d’âge unique et limiter les risques de stalls. Au niveau des unités de traitement justement, deux ALU (calcul arithmétique et logique) et branchement font leur apparition (une dérivant d’une unité de branchement seule), ainsi qu’une AGU (génération d’adresse), portant la largeur du pipeline à 10 ports. Surtout, comme ils ne sont que de 3 types différents, cela simplifie d’autant les choix d’ordonnancement par symétrie.

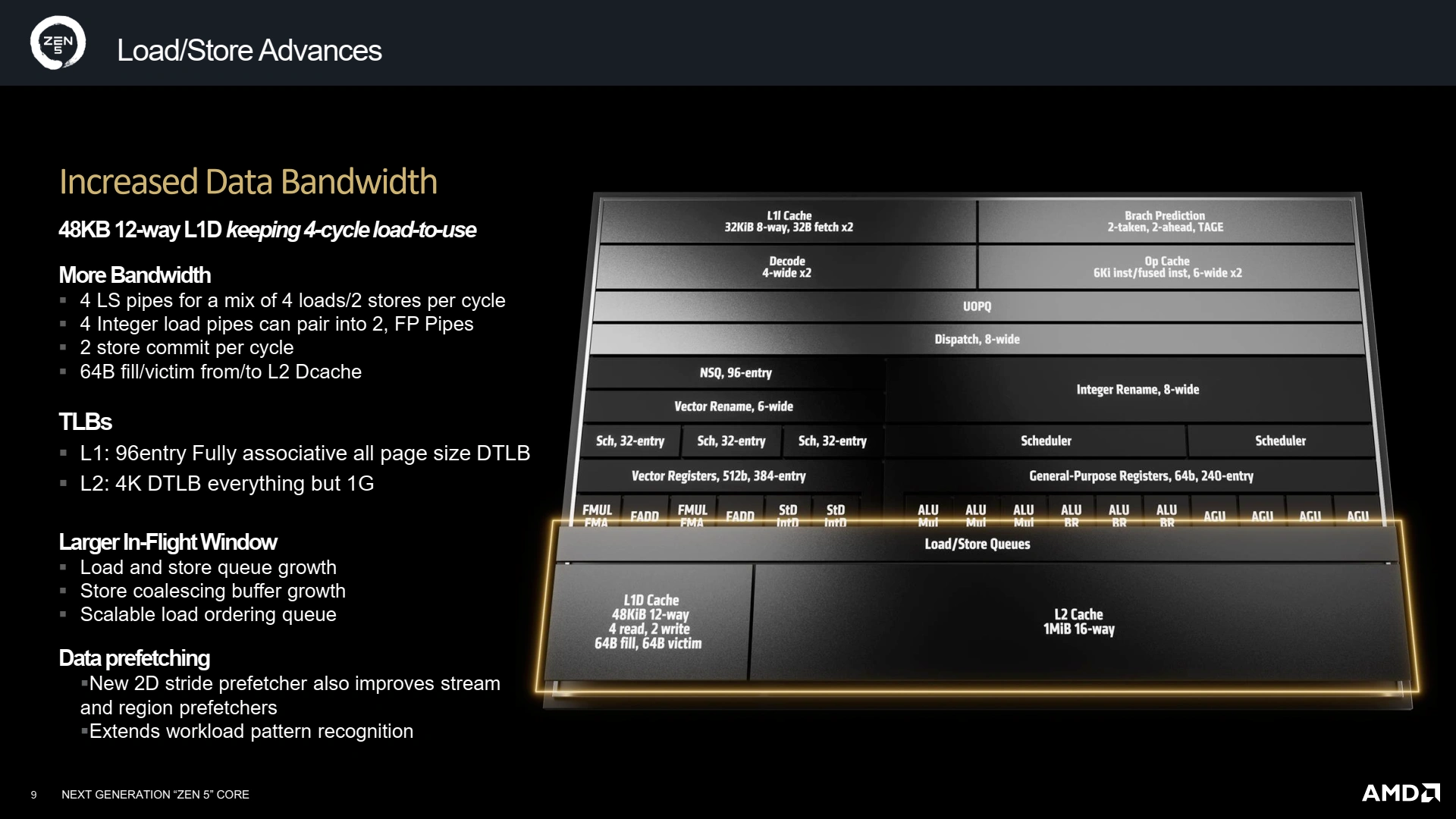
Du côté du pipeline flottant, la largeur ne change pas (6 ports), mais sa composition évolue avec l’intégration d’unités AVX-512 complètes (configurables en 256-bit selon la référence précise du CPU, ici en 512 complet sur Granite Bridge) — la plus grosse avancée —, et la symétrisation des unités de rangement, qui peuvent désormais toutes deux effectuer des écritures dans la mémoire et dans les registres entiers en cas de besoin. Tout ce beau monde est contrôlé par trois schedulers, un par couple FMUL-FMA/FADD et un pour les deux unités de chargement-rangement. Justement, ces unités évoluent avec la possibilité d’effectuer 2 chargements 512-bit par cycle et un rangement 512-bit ; tout comme le FADD (fast-add) qui peut s’effectuer en 2 cycles dans certains scénarii, au lieu des 3 cycles de Zen 4.


Et pour le cache ?
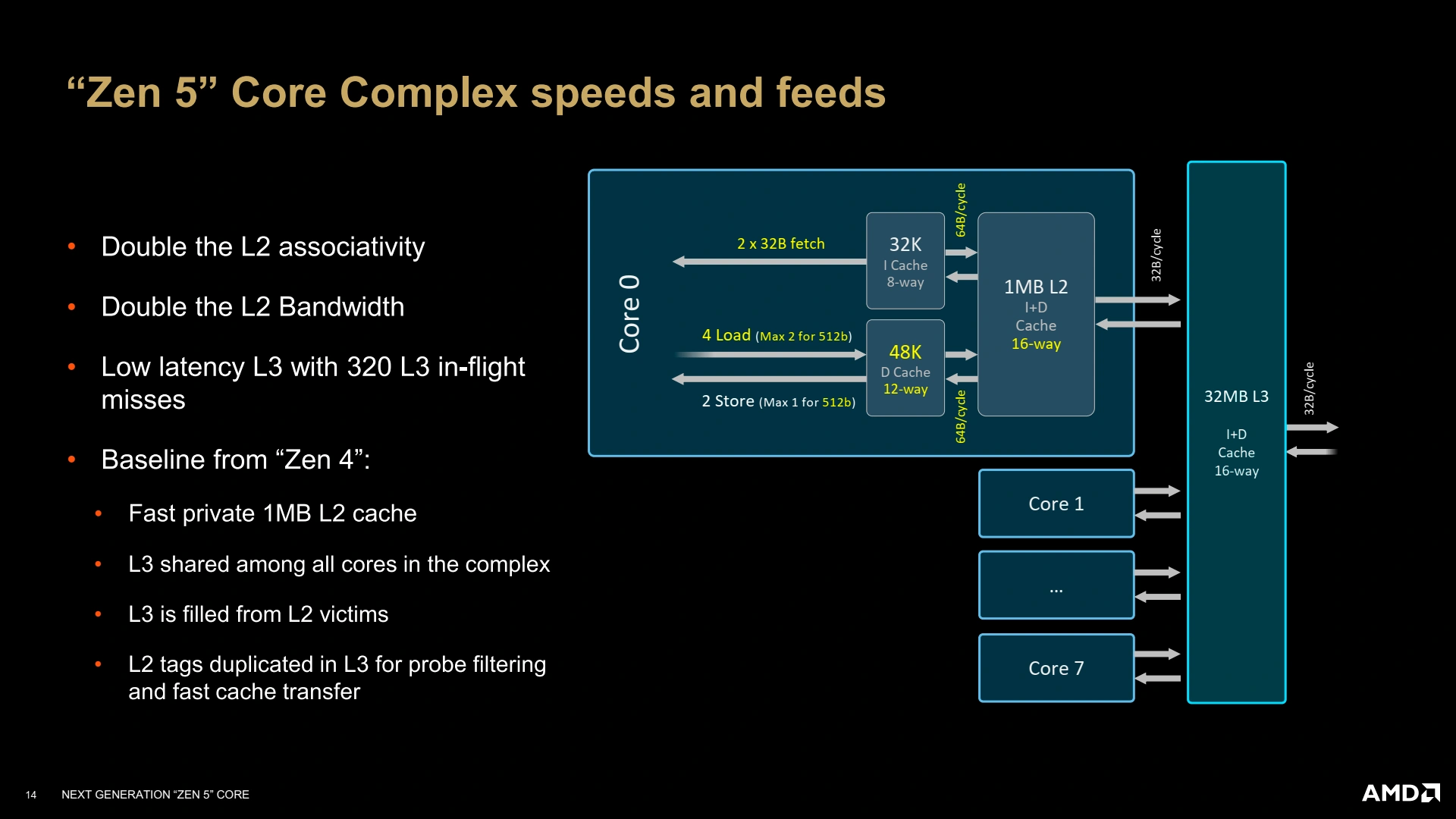
Avoir de la puissance de calcul, c’est bien, mais il faut également que le sous-système mémoire suive pour alimenter tout cela. Ainsi, le L1D passe à 48 Kio partitionnés en 12 voies, tout en gardant une latence de 4 cycles, bien joué ! Le L2 reste à 1 Mio par cœur, et le L3 pourra être configuré de 8 à 32 Mio selon le besoin (mobile, desktop, serveur). En revanche, les TLB (cache de traductions des pages, qui contiennent les structures responsables de l’assignation de RAM à chaque processus) évoluent afin d’offrir toujours plus de performances avec 96 entrées pour le L1 des pages de données, et 4K entrées pour le L2. Un L2 qui contient tous les types de pages sauf celles de 1 Gio (soit uniquement les pages 4 kio et 2 Mio) — il faut dire que supporter 4096 Gio de mémoire mappée en hugepages (4K pages de 1 Gio) n’est pas un usage du plus commun ! Quant aux instructions, leur TLB n’est pas en reste avec un L2 de 2048 entrées. Côté cache non-TLB (L1-I), la bande passante est mise à jour pour pouvoir satisfaire le double décodeur — une opération partagée par le L1-D qui se doit d’être capable de supporter les chargements-rangements AVX-512 ! Enfin, le L2 voit également sa bande passante doublée avec le L1D et le L1I, toujours dans cette logique d’équilibrage du design global.

Un ch'tit peu plus de changements ?
Après ces modifications architecturales, les rouges en profitent pour bonifier le lien avec le système hôte, i.e. les extensions du jeu d’instruction x86. Citons notamment les quelques mises à jour d’instructions, avec le support toujours plus étendu de l’AVX-512 et le rajout d’instructions de streaming permettant de stocker des valeurs sans toucher aux caches, lorsque le programmeur est sûr que la donnée ne sera pas utilisée. De plus, Zen 5 intègre aussi divers utilitaires afin d’isoler les compteurs hardware (des mécanismes chargés de collecter des statistiques sur l’état du CPU pendant les tâches exécutées) dans le cas d’utilisation de machines virtuelles… ainsi que des interfaces remontant des informations lors de l’intégration hétérogène de cœurs, mais cela ne nous intéresse pas ici !




Un petit récapitulatif du bousin !
Et dans un vrai die ?
L’architecture sur papier, c’est bien, mais dans une vraie puce, c’est encore mieux ! Zen 5 va rouler sa bosse dans des Core Complex (CCX), comme tous les cœurs rouges depuis Zen ; et là, l’organisation ne change pas avec une bande passante de 32 octets/cycles avec le L3 (type victime), partagé par tous les cœurs du cluster. Le L3 est également toujours interfacé avec bande passante de 32 octets en lecture/16 octets en écriture (pour des raisons de rétrocompatibilité et d’intégration sur les design en chiplets)… de quoi justifier la castration possible des unités vectorielles AVX-512, vu que le sous-système mémoire est trop faible pour suivre un chargement complet AVX-512 par cycle (64 octets !) depuis le L3 ou la RAM !

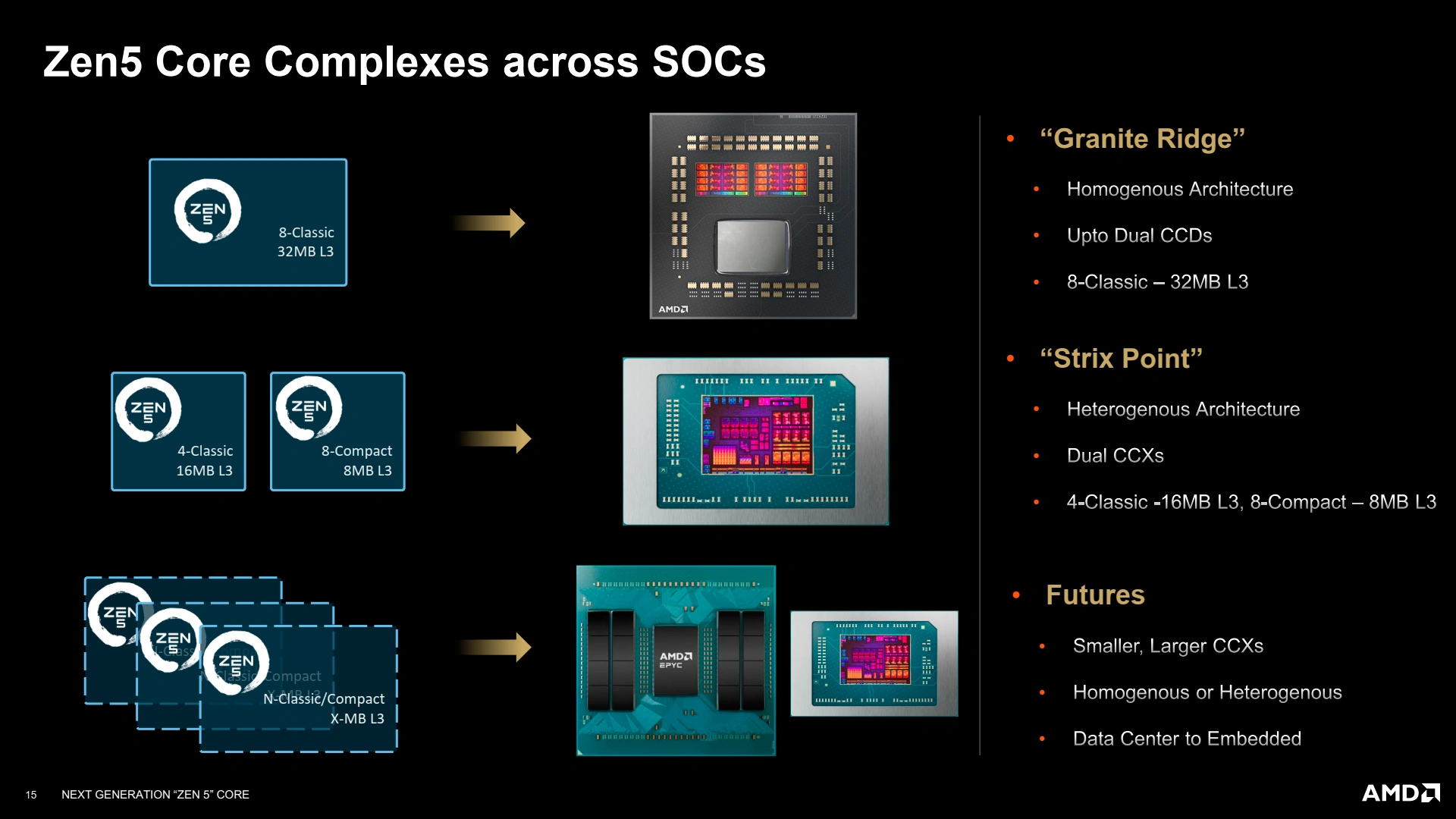
Pour ces Ryzen 9000, Zen 5 prend place dans un ou deux CCD (die de calcul), secondé d’un IOD (die d’entrées/sorties), formant la famille Granite Ridge. Contrairement au concurrent bleu, les Ryzen 9000 reprennent une structure homogène classique (tous les cœurs sont de même architecture et procédé de gravure), et vont jusqu’à recycler le design du CIOD de la génération précédente Zen 4 pour limiter les coûts. Côté CCD, le L3 maximum intégré par puce reste 32 Mio, en attendant les versions X3D capable de porter ce total à 96 Mio… mais ces dernières ne sont même pas encore annoncées !

Dans le détail, voilà la structure des SoC Granite Ridge (ne pas hésiter à passer en plein écran pour tout voir !), comprenant l’interfaçage de l’iGPU (2 CU histoire de faire de la bureautique) et les diverses IO : DDR5 5600 MTr/s, USB 3.2 Gen2 et 28 lignes PCIe 5.0. Vu l’absence criante de communication à ce sujet, le lien avec le chipset semble rester à 4 lignes PCIe 4.0, mais nous aurons probablement plus de détail lors de la sortie des chipsets compagnon d’ici un ou deux mois.

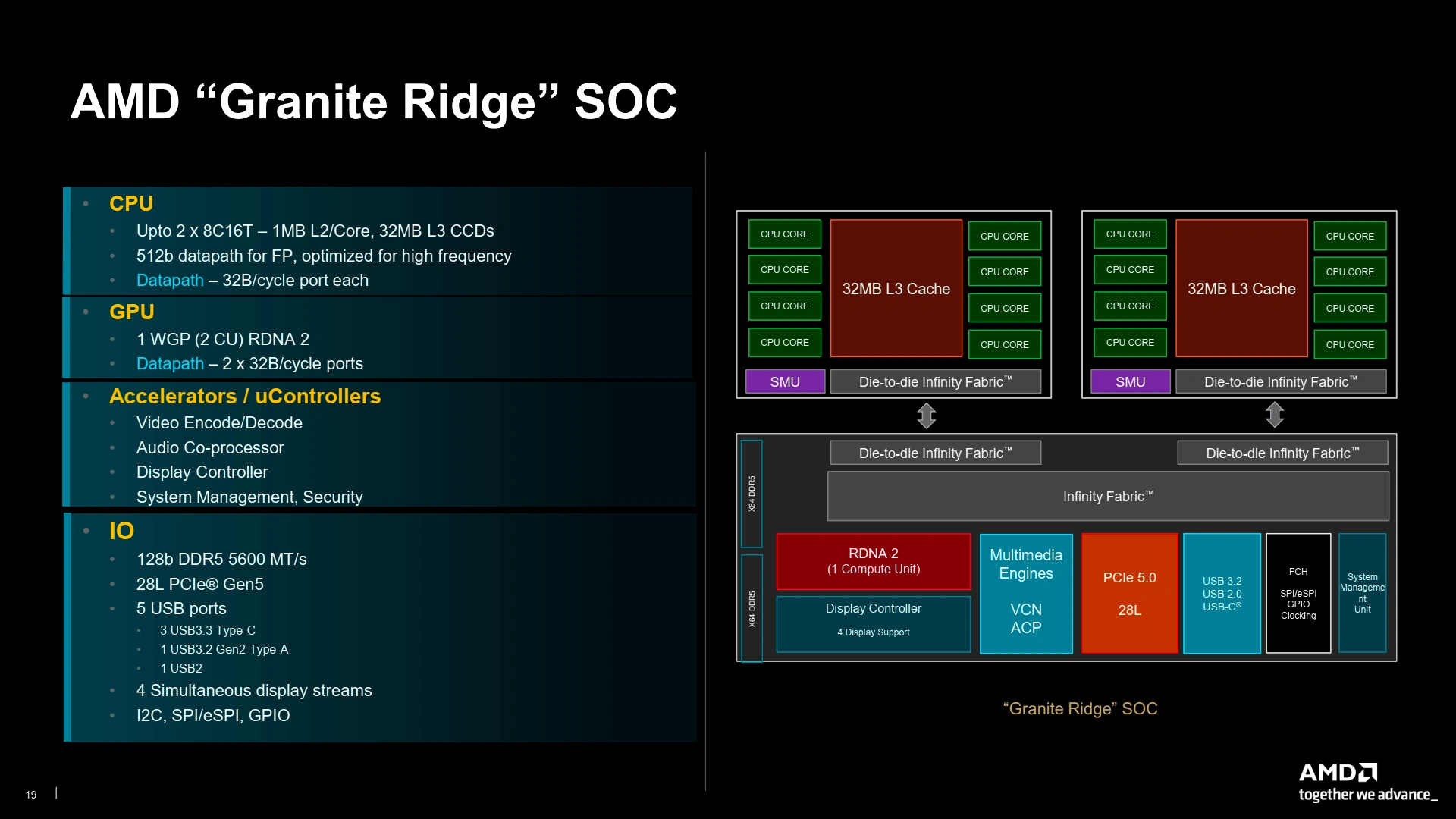
Ici, le datapath correspond au nombre de connexions avec les contrôleurs mémoires via l’Infinity Fabric
Maintenant que vous savez tout ou presque sur l’architecture Zen 5, voyons les processeurs qui utilisent cette dernière.




J'ai pas encore tous lu mais comme quoi mon commentaire sur l'autre news des tarifs était pas si loin de la vérité mine de rien!
Je retourne a la lecture complète cette fois! :)
merci pour ce test fort complet.
Merci pour ce test.
Toujours extrêmement déçu par cette consommation au repos des processeurs AMD... Auriez-vous une explication au fait que les procs récents d'AMD consomment 2 fois plus que ceux d'INTEL ?
D'avance merci :)
Mcm vs monolithe
Je me permets de préciser que les modèles de cartes mères sont différents entre la plateforme LGA1700 (une ASUS TUF GAMING Z790 Pro WiFi qui n'a pas de LED et pas de PCIe 5.0 sur le SSD) et la grosse ASUS ROG CROSSHAIR X670E EXTREME utilisée pour l'AM5. Si tu regardes la consommation à la prise, les différences peuvent aussi venir de ce côté-là (et des diverses optimisation / choix de design de la carte mère) ; le +12 V est bien préférable pour regarder la conso CPU seule (bien que certains module réseaux peuvent aussi aller manger dans ce rail-là). Rajoute aussi les rendements des VRM qui peuvent être un peu différents entre mobales à basse conso, et, comme dit plus haut, les chiplets qui demandent plus de jus que la solution monolithique d'Intel :).
Note que, dans notre cas, on désactive dans le BIOS les cartes réseaux non utilisées (y compris WiFi / BT) ainsi que les contrôleurs LED pour minimiser ces effets. Reste le chipset, et l'influence du "désactivé" sur la conso dépend du bon vouloir du fabriquant... difficile de faire mieux dans notre cas :).
Merci pour cette réponse très complète.
Je pense qu'elle aurait parfaitement sa place dans le test pour expliquer cette consommation trop élevé au repos. L'intégrer à la partie consommation repos ou en conclusion après cette phrase dans la conclusion :
Qu'en pensez-vous ?
Je n'y suis pas favorable car la page verdict est une synthèse de ce qui est écrit précédemment dans le dossier, donc si on doit détailler chaque assertion, autant tout faire tenir sur la même page. Les informations concernant le protocole de test sont présentes dans la page protocole et il est clairement explicité dans la page consommation le pourquoi du comportement des puces AMD à chiplet (qui ne change pas depuis le lancement initial de Zen 2 soit dit en passant). J'ai tout de même rajouté une tabulation pour que cela ne soit pas "noyé" dans l'explication du switch de la méthode de mesure (auparavant uniquement 12 V des connecteurs 4/8 pins et à présent j'ai réintégré la ligne 12V du connecteur à 24 broches) et reformulé légèrement pour que ce soit plus explicit. Merci pour la suggestion 😉.
Merci d'avoir pris le temps de répondre et merci de penser aux néophytes comme moi :)
Ah d'accord, je ne savais pas. En revanche, pourquoi la consommation au repos à encore augmenté de 50% entre Zen 3 et Zen 4/5 ?
Désolé si c'est une redite, mais cette différence je ne la comprends pas à moins que cela vienne de la différence entre l'AM4 et l'AM5 ?
D'avance merci pour votre réponse.
Il n'y a pas de mal à poser les questions y compris des redites, la section commentaire est là pour ça 😉. Pour ce qui est de l'augmentation entre Zen 4 et Zen 5 c'est une bonne question à laquelle je n'ai malheureusement pas de réponses officielles de la part d'AMD. Ce que je peux dire c'est que ça se passe au niveau du CIOD puisqu'il absorbe (selon HWiNFO64) la plus grosse partie de l'énergie du CPU au repos. Comme il est bien plus complexe avec l'intégration de l'IGP (il est désactivé via le bios mais pour autant les transistors concernés ont-ils une consommation nulle dans cet état) mais surtout du PCIE Gen 5 qui a mon avis est source d'une bonne part de cette augmentation significative de la puissance absorbée au repos par rapport à l'AM4.
Merci d'avoir pris le temps pour une réponse aussi détaillée.
Très bon test comme toujours
J'ai du mal a comprendre le choix de réduite le tdp d'une gen a l autre surtout sur le 9700x
Bon dans l'absolue mais trop cher vu le reste du marché
Merci pour le test ! 😁
Visiblement pour cette génération AMD s'est concentré sur mobile et server.
EDIT: Sous Linux (chez Phoronix) ça semble bien poutrer : +15% pour le 9700X face au 7700X, et +25% pour le 9600X face au 7600X. Rien que sous TensorFlow les gains sont très différents. Un problème sous Windows?
les tensor flow utilise avx 512 il me semble d'ou les gains
Notre test TensorFlow est sous Linux, mais il est très différent de ce que peux faire phoronix. Il n'est pas en AVX-512 car cela nécessite des dépendances différentes entre CPU selon leur compatibilité, ce qui n'a pas été intégré dans la version actuelle de notre image disque (mais c'est une remarque tout à fait pertinente que je m'en vais corriger). De plus, le test ne fait pas de l'inférence mais de l’entraînement, et effectue également de la quantisation des résultats... autant dire qu'on est assez loin d'un ResNet-50 seul, ce qui explique les disparités dans les résultats.
Merci pour ta réponse, c'est intéressant. Je prenais Tensorflow pour l'exemple; chez Phoronix les gains sont significatifs dans beaucoup de benchmarks. Il faudrait étudier dans le détail ce qui est mis en avant (AVX-512, mémoire, etc), mais ça diffère sensiblement de ce que je peux lire ailleurs, ici inclu. D'ailleurs personne ne semble avoir les mêmes résultats : Tom's trouve le 9700 bon en jeux quand tout le monde ne voit pas de gains, voire des régressions chez Techspot.
EDIT: Sinon, il faut quand même souligner qu'AMD vous a envoyé deux CPU, pas mal après même pas 1 an et demi d'existence!