
Un méga-NPU pour de la méga-AI
Pour finir, que serait un SoC tellement-2024 sans son accélérateur d’IA ? Ne répondez pas, même sarcastiquement, la question était rhétorique. Avec Lunar Lake, Intel nous dévoile la 4e génération de son NPU, hérité du rachat de Movidius en 2016. Par rapport à l’itération précédente (et similairement au GPU), les bleus ont gonflé le nombre d’unités pour parvenir à leurs fins. Ainsi, nous retrouvons 6 NCE (Neural Compute Engine), les accélérateurs matriciels basés sur une architecture systolique, en lieu de place des 2 intégrés sur les Core Ultra 100. De quoi porter de suite la puissance de calcul brute à 12K MAC par cycle, et obtenir un magnifique ratio 2 de performance à consommation égale par rapport à la génération précédente — la nouvelle gravure de chez TSMC aidant très probablement sacrément de ce côté-là —, et une augmentation d’un facteur 4 des performances lorsque la consommation est laissée libre. Les 48 TOPS ne sont tout de même pas gratuits en watts !

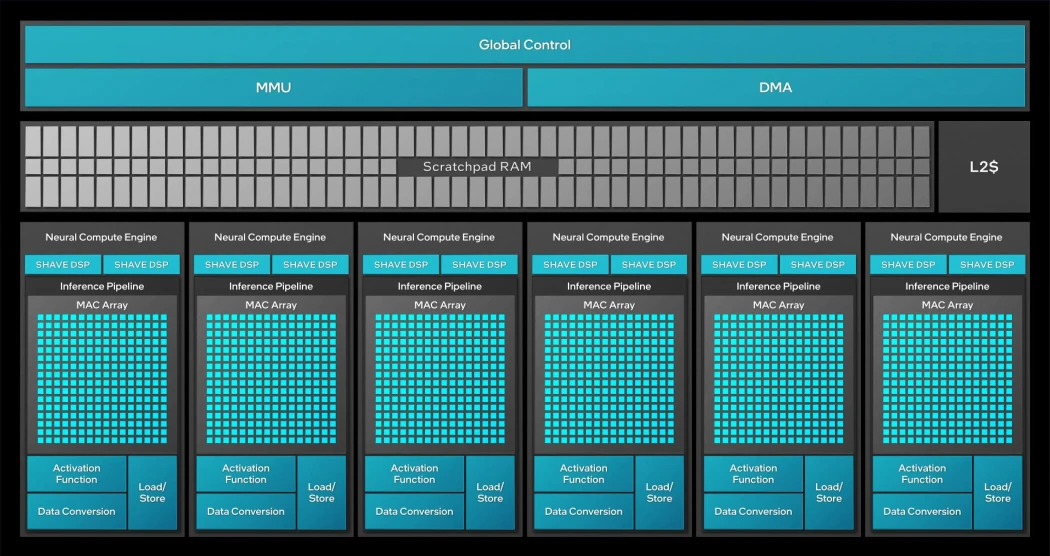
Outre l’accélérateur de multiplication de matrice INT8/FP16 en ratio 2:1 (et BF16, bien qu’actuellement désactivé) représenté par l’ensemble de petits carrés cyan sur le schéma), un NCE est également composé d’une MMU chargée de communiquer avec la mémoire (d’où son nom de Memory Management Unit) possédant un accès direct (DMA, pour Direct Memory Access), doublé par rapport à la génération précédente. Comptez aussi une unité permettant de calculer la fonction d’activation (un post-processing du vecteur de sortie) et une unité de conversion de données, par exemple pour encoder un résultat FP16 sur des valeurs INT8, et nous avons quasiment fini…



Pour un gros récap' des principes du machine learning, c’est par ici !
… car le NPU serait bien vide sans ses 2 DSP nommés SHAVE (Streaming Hybrid Architecture Vector Engine), des mini-processeurs VLIW dont la puissance de calcul a été multipliée par 4. Ces p’tits bidules calculent des opérations bien pratiques en machine learning comme le softmax (une normalisation) sur des vecteurs de 512 bits à raison de 32 opération FP16 par cycle et par DSP, pas étonnant que le bousin prenne grosso modo un sixième de la surface de la puce après ça !


Après avoir vu en détail toutes les unités de Lunar Lake mais aucune fréquence ni chiffre de performance, à quelle conclusion pouvons-nous arriver ? Le suspens est insoutenable, mais pas de panique, le cliff hanger se termine à la page suivante !


Tout cela est très intéressant
Ça peut paraître bizarre qu intel produit un cpu pas avec ça gravure
Le n3b est le die le plus efficient et le plus dense actuellement en plus intel est mauvais en transistors gpu ( haute densité ) voulant faire ultra compact et efficient c'est une bonne idée
A l'inverse le die soc en n6 me surprends
Pas besoin du n3b pour ce die il est ultra cher pour un gain très réduit ( les transistors hors ceux pour la logique progresse très peu voir quasiment pas vs le n5 )
Le n6 est "vieux" maintenant alors oui il est moins cher mais j'aurais plus vu n5 ou un de ses dérivé piur gagner en taille et en consommation
Bon après lecture approfondie j'ai l'impression que intel est revenue en arrière sur un point
Meteor lake avait explosé en mcm
La on revient comme avant Meteor lake le compute die intègre se qu'avait le die gen 13/14 et le second due c'est le chipset qui était côté
C'est la même chose mais emballé en 2.5d avec une nouvelle gravure
Le SMT s’avère surtout être une faille de sécurité perpétuelle, entre les fix et les patchs pas sur que ce soit vraiment une perte de performances de le virer 😅
Intel avec son lunar lake, qualcomm avec son xlite, amd machin truc et nvidia cpu machin truc... windows qui va devoir jongler avec les 4 ... Et tous les logiciels qui ne sont pas en natif et sans oublier tous les dell, asus et autre qui vont faire des variantes matérielles de leur ordinateur....
Quelle horreur la complexité des variantes et la fragmentation infinie que ça va engendrer et les bugs que Windows ne sait pas gérer...
Bonne chance pour que ça fonctionne sans accroche.... Faudrait songer à utiliser apple
Passez chez Apple, ils ont peu de variantes matérielle, ils créent leur propre puce, Ils font leur propre OS, tous les logicielles suivent Apple.
Amd et intel c'est du x86 donc pas de soucis et arm il y a emulateur apprement aussi performant que rosetta 2
Donc ça devrait aller
Apple ces gens qui décident arbitrairement quand ton ordinateur est obsolète en arrêtant de le mettre a jour, non merci 😬
Article beaucoup trop "technique" pour moi et mes maigres connaissances néanmoins je suis sûr que cela a fait plaisir à d'autres lecteurs qui ont du apprécier votre expertise et c'est bien là l'essentiel.
J'ai eu l'impression de relire certains articles de HFR !
C'était le bon temps hfr
J'avoue c'est complexe mais c'est aussi complet du coup
Après il y a les slides et les graphiques d intel plus simple à comprendre
Je ne cache pas que HFR ça a été notre référence et que c'est le type de contenu que nous visons. Le souci c'est qu'il faut vulgariser 20 ans de progrès hardware avant de lister les changements de la nouvelle génération ; dur dur pour quelqu'un qui débarque ! Cependant, avec un format récurrent expliquant certains mécanismes CPU peut etre une bonne idée pour pouvoir les référencer à divers endroits du dossier :-)
Moi jai compris les autres ..... 🤣
Super analyse très détaillée! En effet ça semble prometteur, faudra voir la réalité dans les produits.
La suppression de l'HT va forcément avoir un coût sur certains workloads, notamment ceux orientés I/O (stockage ou réseau) où il est possible d'avoir les drivers bindés sur les threads pairs et le userland sur les thread impairs, partageant ainsi le cache L2 avec une ultra-faible latence. Intel avait déjà fait ça sur les core2 en disant "meuh non de toute façon ça servait à rien" puis ils l'avaient réactivé sur les Core en disant "regardez ce qu'on vous a ajouté, c'est bien non?".
Pour le coup, la suppression de l'AVX512 est une ânerie. Ils ont investi plein d'extensions là-dedans, encouragé les clients à s'en servir, et au moment où leur concurrent préféré l'adopte de manière assez fûtée, ils baissent les bras. Pour moi ils auraient dû faire comme leur concurrent, et splitter les instructions 512 sur 2 ports 256 et n'en faire qu'une par cycle, et éviter ainsi d'affecter la consommation et la fréquence de fonctionnement. Ca permettrait au moins de profiter de certaines fonctionnalités utiles comme l'IFMA, très utile pour la crypto asymétrique.
A suivre...
Avx 512 va revenir avec avx 10
L'avx-512 reviendra pour les pro, mais ca fait depuis Alder Lake que ça n'est plus sur les proco grand public car les E-Core sont anémiques en calcul flottant (cest ~ du SSE derrière) et l'OS ne supporte pas des extensions différentes sur un même cpu
Pourquoi donc? Et le Thread Director, il n'est pas fait pour ça?
Non, Thread Director apporte un conseil sur un coeurs possiblement optimal pour placer. Un conseil n'est pas une contrainte !
Il faudrait que tous les processus déclarent en avance si ils utilisent de l'AVX512, et ça cassera la rétrocompatibilité (pour le moment c'est "tu lis un bit dans un registre interne, et si c'est une certaine valeur, alors tu as l'AVX-512", or si l'OS dit que tu est compatible, et que tu te fais scheduler sur un coeur dépourvu... boum). En plus, l'AVX-512 est très peu utilisé par le grand public et prend quand même un peu de place : sur un SoC basse conso, l'avoir est moins d'être une nécessité