
Des E-Core efficients, mais tout de même sacrément puissants
Comme nous vous le racontions à la page précédente, Lunar Lake a été conçu pour peu consommer et couper complètement ses P-Core en cas d’inactivité. De ce fait, les E-Core se doivent d’être complètement indépendant architecturalement (et dans leur circuit d’alimentation), ce qui explique la filiation de Skymont (la microarchitecture des E-Core de Lunar Lake) comme provenant des 2 LP-Core de Meteor Lake — ceux de la tuile SoC, et non des E-Core de cette même architecture — ceux collés sur la tuile de calcul. En revanche, cette deuxième option est toujours possible et sera très probablement employée pour Arrow Lake, ne vous faites pas de souci ! Cela permet en outre de comparer les gains en matière de consommation et de performances à une implémentation basée sur de l’Intel 7… au moins, cela a l’avantage d’être sémantiquement correct.


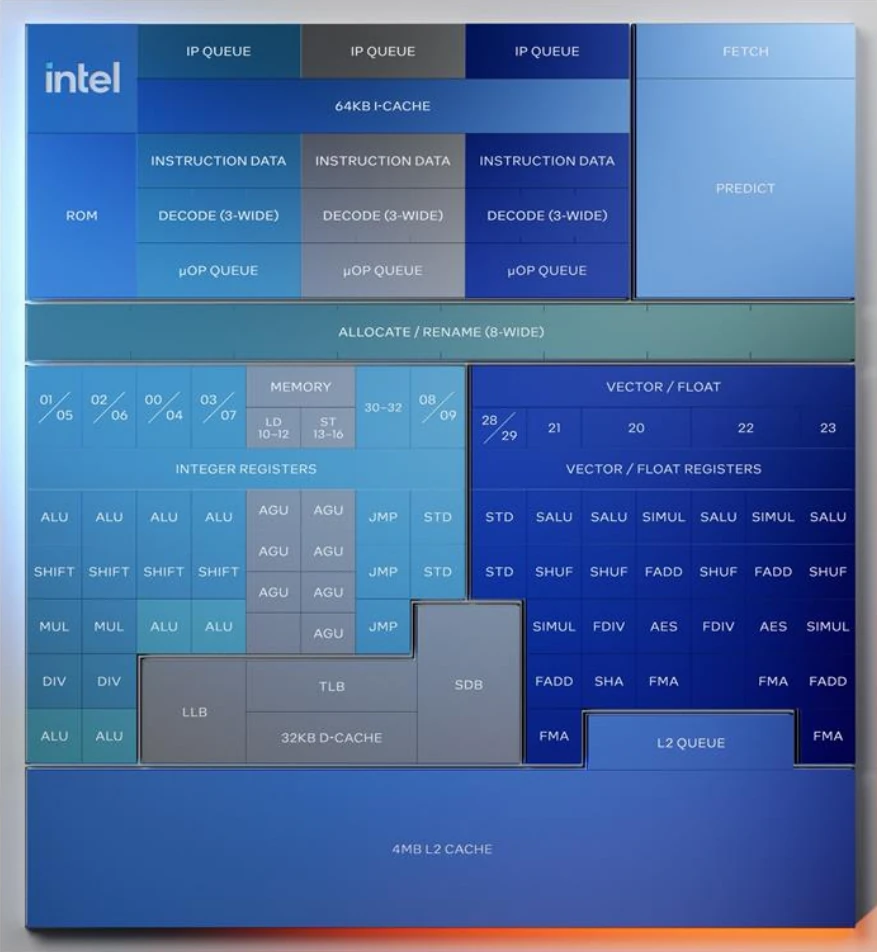
Architecturalement, ces progrès sont dus — une fois encore — à un travail combiné sur le front comme le back-end. Côté front, la prédiction de branchement prédit jusqu’à 128 octets en allant chercher un maximum de 96 instructions. Ce beau monde est confié à 3 décodeurs (contre 2 auparavant), qui permettent de casser les blocs d’instructions, par exemple suite à un branchement. De plus, la dépendance au microcode est supprimée en utilisant un mécanisme nommé « nanocode », qui n’est ni plus ni moins qu’un accès multiple au microcode par tous les décodeurs, évitant ainsi la sérialisation forcée. Enfin, la queue des µOps est aussi agrandie avec 96 entrées, qui atterrissent dans un ROB de 416 entrées (contre 256 précédemment).


Côté back-end, contrairement à ce que l’on pourrait penser, Skymont contient en fait davantage de ports que Lion Cove : 26 très exactement. Cela s’explique par une spécialisation plus importante de ces derniers, ce qui permet de gagner en simplicité. Ces 26 ports se décomposent en :
- 8 ports d’exécution de calculs entiers (4 doublés)
- 3 ports de branchement (sauts)
- 3 ports de chargement
- 4 ports de stockage (2 entier, 2 vectoriel et flottant)
- 4 ports de calcul flottant (aiguillant vers des unités… SSE)



Sur le papier, le sous-système flottant permet d’exécuter 4 FMA vectoriels SSE par cycle, soit un total de 16 FLOP/cycles. En revanche, il sera compliqué de les utiliser de cette manière, puisque seuls 3 ports de chargement 128-bit sont disponibles. Certes, il est possible de les faire fonctionner en AVX-2, ce qui monopolise 2 unités FMA 128-bit pour un FMA 256-bit (AVX2, quoi !), mais ne règle pas le souci ne permettant de charger qu’un total de 384 bit par cycle. Intel nous a confié avoir utilisé une telle répartition pour simplifier la tâche du scheduler, mais admet que le pipeline n’est pas totalement équilibré. Un choix d’autant plus étrange que des Xeon — Sierra Forest — feront également usage de ces E-Core sans modification (sans AVX-512 à fortiori). Certes, une partie des usages des data centers sont des tâches de type serveur web ou les flottants sont en écrasante minorité (et les bandes passantes des caches auraient dû être revues, ce qui aurait pris plus de silicium), mais il est difficile de ne pas y voir une occasion manquée de designer un CPU spécialement pour le machine learning, avec un front-end plus léger mais un débit et une densité démentiel - similairement aux grands principes de conception des GPU, en fait. La chose est d'autant plus étrange que Skymont est compatible avec les extensions VNNI pour le machine learning, portées en AVX2 !


Pour ce qui est de la mémoire, le L2 double (en prenant pour base les 2 LP-Core de Meteor Lake !) pour culminer à 4 Mio, mais de bande passante améliorée (128 octets par cycle, soit 32 octets/cœur : tout pile 2 chargements vectoriels 128-bit chacun). De plus, la cohérence de cache entre L1 de cœurs différent est améliorée pour être plus rapide, un bon point pour le multithreading. Côté TLB, ce dernier suit le L2 et passe de 3192 entrées à 4192, sachant que le L1-I conserve ses 64 kio, et le L1-D ses 32 kio. Basse performance consommation, on a dit !
Tout ce beau monde est bien difficile à évaluer niveau performance, car ces E-Core pourront, au choix, être utilisées comme des unités d’appoint des P-Core (pour Arrow Lake) ou comme des cœurs basse consommation dans un but d’autonomie maximale. Cela signifie que le design possède différents points d’utilisation sur la courbe vitesse/consommation, qu’il est difficile de comprendre dans la totalité au premier abord. Ainsi, par rapport aux LP E-Core, en monothread :
- La consommation est réduite de 66 % à isoperformance
- OU les performances sont améliorées d’un facteur 1,7 à isoconsommation
- OU la performance double, sans qu’Intel nous communique la consommation finale
Mais ce n’est pas tout ! En multithread, les cœurs affichent des gains encore plus faramineux, mais à 4 contre 2, le match est évidemment pipé… En revanche, en utilisation auxiliaire (c’est-à-dire sur les prochains Arrow Lake), le bousin affiche (par rapport à Raptor Lake — wouhou —, en monothread et calcul entier [en flottant, tout doit s’effondrer !]) :
- 40 % de gain en consommation à isoperformances
- OU 20 % de gains en performance à isoconsommation



Ainsi, nous avons sur Lunar Lake des P-Core affutés pour de la performance single-thread entière et flottante, et des E-Core conçus pour une réduction maximale de la consommation en accélérant très efficacement les calcul entiers et les applications à flot de contrôle irrégulier, mais s’effondrant en charge flottante/vectorielle. Se pose alors la question du placement des threads sur ces unités… à laquelle Intel répond par Intel Thread Director, que nous étudions à la page suivante !



Tout cela est très intéressant
Ça peut paraître bizarre qu intel produit un cpu pas avec ça gravure
Le n3b est le die le plus efficient et le plus dense actuellement en plus intel est mauvais en transistors gpu ( haute densité ) voulant faire ultra compact et efficient c'est une bonne idée
A l'inverse le die soc en n6 me surprends
Pas besoin du n3b pour ce die il est ultra cher pour un gain très réduit ( les transistors hors ceux pour la logique progresse très peu voir quasiment pas vs le n5 )
Le n6 est "vieux" maintenant alors oui il est moins cher mais j'aurais plus vu n5 ou un de ses dérivé piur gagner en taille et en consommation
Bon après lecture approfondie j'ai l'impression que intel est revenue en arrière sur un point
Meteor lake avait explosé en mcm
La on revient comme avant Meteor lake le compute die intègre se qu'avait le die gen 13/14 et le second due c'est le chipset qui était côté
C'est la même chose mais emballé en 2.5d avec une nouvelle gravure
Le SMT s’avère surtout être une faille de sécurité perpétuelle, entre les fix et les patchs pas sur que ce soit vraiment une perte de performances de le virer 😅
Intel avec son lunar lake, qualcomm avec son xlite, amd machin truc et nvidia cpu machin truc... windows qui va devoir jongler avec les 4 ... Et tous les logiciels qui ne sont pas en natif et sans oublier tous les dell, asus et autre qui vont faire des variantes matérielles de leur ordinateur....
Quelle horreur la complexité des variantes et la fragmentation infinie que ça va engendrer et les bugs que Windows ne sait pas gérer...
Bonne chance pour que ça fonctionne sans accroche.... Faudrait songer à utiliser apple
Passez chez Apple, ils ont peu de variantes matérielle, ils créent leur propre puce, Ils font leur propre OS, tous les logicielles suivent Apple.
Amd et intel c'est du x86 donc pas de soucis et arm il y a emulateur apprement aussi performant que rosetta 2
Donc ça devrait aller
Apple ces gens qui décident arbitrairement quand ton ordinateur est obsolète en arrêtant de le mettre a jour, non merci 😬
Article beaucoup trop "technique" pour moi et mes maigres connaissances néanmoins je suis sûr que cela a fait plaisir à d'autres lecteurs qui ont du apprécier votre expertise et c'est bien là l'essentiel.
J'ai eu l'impression de relire certains articles de HFR !
C'était le bon temps hfr
J'avoue c'est complexe mais c'est aussi complet du coup
Après il y a les slides et les graphiques d intel plus simple à comprendre
Je ne cache pas que HFR ça a été notre référence et que c'est le type de contenu que nous visons. Le souci c'est qu'il faut vulgariser 20 ans de progrès hardware avant de lister les changements de la nouvelle génération ; dur dur pour quelqu'un qui débarque ! Cependant, avec un format récurrent expliquant certains mécanismes CPU peut etre une bonne idée pour pouvoir les référencer à divers endroits du dossier :-)
Moi jai compris les autres ..... 🤣
Super analyse très détaillée! En effet ça semble prometteur, faudra voir la réalité dans les produits.
La suppression de l'HT va forcément avoir un coût sur certains workloads, notamment ceux orientés I/O (stockage ou réseau) où il est possible d'avoir les drivers bindés sur les threads pairs et le userland sur les thread impairs, partageant ainsi le cache L2 avec une ultra-faible latence. Intel avait déjà fait ça sur les core2 en disant "meuh non de toute façon ça servait à rien" puis ils l'avaient réactivé sur les Core en disant "regardez ce qu'on vous a ajouté, c'est bien non?".
Pour le coup, la suppression de l'AVX512 est une ânerie. Ils ont investi plein d'extensions là-dedans, encouragé les clients à s'en servir, et au moment où leur concurrent préféré l'adopte de manière assez fûtée, ils baissent les bras. Pour moi ils auraient dû faire comme leur concurrent, et splitter les instructions 512 sur 2 ports 256 et n'en faire qu'une par cycle, et éviter ainsi d'affecter la consommation et la fréquence de fonctionnement. Ca permettrait au moins de profiter de certaines fonctionnalités utiles comme l'IFMA, très utile pour la crypto asymétrique.
A suivre...
Avx 512 va revenir avec avx 10
L'avx-512 reviendra pour les pro, mais ca fait depuis Alder Lake que ça n'est plus sur les proco grand public car les E-Core sont anémiques en calcul flottant (cest ~ du SSE derrière) et l'OS ne supporte pas des extensions différentes sur un même cpu
Pourquoi donc? Et le Thread Director, il n'est pas fait pour ça?
Non, Thread Director apporte un conseil sur un coeurs possiblement optimal pour placer. Un conseil n'est pas une contrainte !
Il faudrait que tous les processus déclarent en avance si ils utilisent de l'AVX512, et ça cassera la rétrocompatibilité (pour le moment c'est "tu lis un bit dans un registre interne, et si c'est une certaine valeur, alors tu as l'AVX-512", or si l'OS dit que tu est compatible, et que tu te fais scheduler sur un coeur dépourvu... boum). En plus, l'AVX-512 est très peu utilisé par le grand public et prend quand même un peu de place : sur un SoC basse conso, l'avoir est moins d'être une nécessité