Second grand volet technique de notre série d’articles concernant l’événement Intel Foundry Direct Connect, Hardware & Co s’est penché sur les technologies de liaison de tuiles des bleus, encapsulés sous les dénominations de Foveros et EMIB. Tout cela s’est déroulé dans le cadre de l’Intel Foundry Direct Connect, de manières conjointes aux autres présentations des progrès des bleus en matière de gravure. Comment donc qu'on fait cohabiter tout pleins de morceaux de silicium de technologies différentes ? C'est ce que nous allons voir ensemble !


Kevin O’Buckley, General Manager de Intel Foundry, adore prendre la pose avec un prototype de puce pour datacenter (IA !) dopée à l’EMIB. La somme totale de la surface des dies y est bien plus importante que ce qu’une lithographie monolithique permet de réaliser — limitée par la taille du réticule ; ce qui permet de prolonger la loi de Moore.
50 nuances de Foveros
Dans le monde du stacking (empilement/interconnexion de chiplets que les bleus nomment tuiles), Intel possède deux méthodes : Foveros et EMIB. Le premier consiste à empiler des morceaux de silicium gravés les uns au-dessus des autres à la manière des interposers utilisés par exemple par AMD sur ses GPU, et le second signifiant Embedded Multi-die Interconnect Bridge et se caractérise par des « ponts » de plus petite taille intégrés directement dans le PCB pour interconnecter localement des tuiles entre elles. Par exemple, Lunar Lake est un stacking de type Foveros avec du N3B et N4 de TSMC au-dessus d’un die 100 % interconnect, 0 % transistor en Intel 4, là où les Xeon Max reposent sur de l’EMIB.


Côté EMIB
La grande nouveauté de l’EMIB est l’EMIB-T : une version de cette interconnexion capable de mêler EMIB et TSV afin de stabiliser l’alimentation : une étape cruciale pour le bon fonctionnement de la HBM 4.



En effet, une puce de HBM4 est relativement petite, et, pour rerouter les données entre ses patounes et un accélérateur, la tuile EMIB se doit de couvrir une grande partie des contacts de la mémoire. Or, parmi ces contacts se trouve également l’alimentation, et, au vu de la complexité des signaux et du courant demandé, des TSV deviennent incontournables pour cela. Rajoutez des possibilités d’intégration d’inductances nommées CoaxMIL — déjà dans les tuyaux en 2021 — et d’eMIM (embedded Metal-Insulator-Metal) — datant cette fois-ci d’au moins 2019 — servant à l’intégration de modules de contrôle de tension et de capacitances avec les eDTC (Dans Ton … embedded Deep Trench Capacitor, pardon!). Pour les non-initiés, il est question de primitives de traitement du courant directement que l’on peut désormais caler directement sous les dies pour plus d’efficacité.


Alors que les dies monolithiques/empilements Foveros souffrent de difficultés à grossir — une gravure sans défaut est d’autant plus difficile que les dies sont grands — l’EMIB permet un scalabilité bien plus importante sans faire exploser les coûts. Voilà qui fait rêver les boîtes designant des accélérateurs d’IA !
Côté Foveros
Pour l’empilement 3D à proprement parler, Foveros évolue avec deux nouvelles variantes : Foveros-R et Foveros-B, qui complémentent l’existant Foveros-S (stacking « classique » à base d’interposer). La version R signifie RDL, ou Redistribution Layer interposer. Au lieu d’avoir recours à un die de silicium, la version à couche de distribution de base sur des polymères superposés les uns aux autres, ce qui diminue les coûts de production pour les applications ne requérant pas les densités les plus élevées. Comptez 2027 pour la production de masse, et probablement quelques mois plus tôt pour la production à risque.


De manière complémentaire, Foveros-B (pour Bridge) autorise d’intégration de « ponts » de silicium afin d’apporter localement des composants actifs. Ainsi, des IVR (régulateurs de tension intégrés) et des MIM (des capacitances intégrées dans le silicium) peuvent être placés librement sous les dies pour une meilleure gestion de l’alimentation et/ou du routage des informations. Au total, les améliorations permettraient de grimper à 1 600 connections par mm² et 0,15 pJ par bit transmis : mais que va-t-on faire de toute cette bande passante !


Enfin, Foveros sera parachevé par Foveros Direct, une version de l’empilement remplaçant les billes de cuivre par des liens hybrides (hybrid bonding, aperçus déjà à l’IEDM) reliant directement les couches métalliques sans tiers composé. De quoi réduire davantage les tailles des contacts, diminuer l’énergie (0,05 pJ/bit, soit 3 fois moins que Foveros-B !) et exploser la densité (10 000 contacts par mm²), mais à un coût probablement plus élevé vu la précision supplémentaire requise à l’assemblage.
Quelle finesse de gravure pour les tuiles de base ?
Tout cela est fort intéressant, mais pour pouvoir superposer des dies les uns au-dessus des autres, il faut avoir une gravure capable de supporter cela ; à savoir prenant en charge les différentes manières de coller tout ce beau monde et, surtout, de manufacturer les TSV (Through Silicon Via), ces piliers apportant le jus d’électron aux couches supérieures.

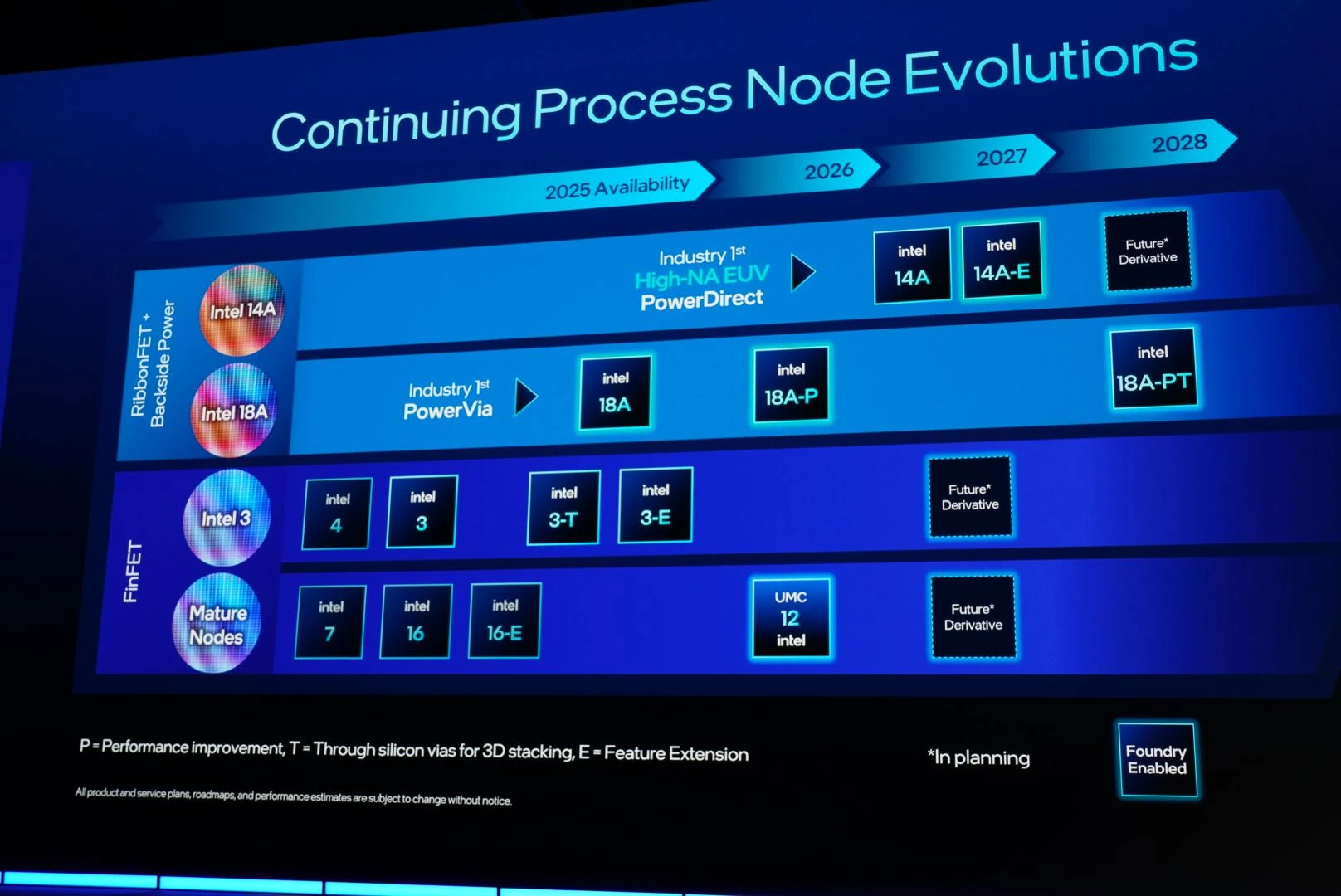
Le portfolio actuel et les promesses des bleus pour l’avenir.
Pour le moment, la seule gravure disponible pour du stacking est l’Intel 4, qui se retrouve sur Lunar Lake et Arrow Lake. Si, dans les deux cas, Intel n’a eu recours à un die passif n’utilisant que la partie d’interconnexion (les metal layers surplombant le silicium), ce choix est dû à des contraintes thermiques et non technologiques. Après l’Intel 3-T (justement pour TSV) viendra le 18A-PT, penchant TSV de l’Intel 18A-P que nous détaillions ici.


Comme son nom l’indique, ce 18A-PT reprend les fondamentaux du 18A (PowerVia et GAA-FET) ainsi que les améliorations apportées par la variante 18A-P issue des besoins spécifiques des clients d’Intel Foundry. Ainsi, le 18A-PT est donné comme 20 à 25 % plus dense en matière de calculs — encore faut-il en avoir l’utilité — 25 à 35 % plus économe, mais surtout 9 fois plus dense du côté des interconnexions entre dies — une conséquence de l’écartement entre billes de cuivre toujours plus réduite. Au besoin, les entreprises peuvent directement piocher dans les designs de Cadence et Synopsys pour trouver quoi intégrer sur les tuiles concernées, puisque les bibliothèques de cellules sont directement compatibles avec celles du 18A-P, elles-mêmes migrables depuis les 18 A. Les deux partenaires ayant lourdement insisté sur la certification de leur contrôleur HBM4, nous nous doutons que les accélérateurs d’IA (voire des GPU ?) seraient en route pour cette nouvelle finesse. Voilà qui laisse au géant bleu de sacrés arguments pour rameuter moult clients dans ses usines : reste à voir les performances !
… et des technologies optiques émergentes
Certes, les technologies d’interconnect optique ne sont pas tout à fait du domaine du packaging, mais Intel compte bien en tirer partie pour les générations suivantes. À vrai dire, des wafers de préséries étaient en exposition, mais également quelques précisions techniques sur la chose.


En interne, il est question de relier une fibre optique au package via un coupleur, ce qui permet de transmettre des informations à une vitesse bien plus grande que les pistes en cuivre traditionnelles. Si aucun produit n’est annoncé, Intel a tout de même déclaré que ces interconnexions silicium-photoniques seraient un composant clef pour les prochaines générations d’accélérateurs d’IA. À voir ce qu’il en est au niveau du coût d’une telle technologie, et de ses performances en pratique !


Intéressant tout ça mais ça manque de concret
Intel 4 meteor lake mobile uniquement arrow / lunar lake tsmc
20a annulé
Les tuiles de base d'Arrow Lake et Lunar Lake sont en Intel 4. Effectivement, les fonderies ont de l'inertie et c'était plus rentable pour Intel (et meilleur pour les consommateurs) d'utiliser du TSMC plus au point que de s'entêter avec une gravure maison inférieure. Vu les faibles gains d'Arrow Lake en perf brute, le choix était justifier. À voir si le 18A tient ses promesse, fin 2025 !
Quand on constate que la miniaturisation est aussi intense et tout cela relativement facilement, on ne peut être qu'étonné de la facilité avec laquelle la matière (lumière comprise) nous permet de jouer avec elle.
Je dis que c'est assez facile car en fait , on est dessus que depuis 1945 et encore, avant 1970, on avait pas avancé beaucoup.
Puis cela s'est emballé à partir de 1990. Loi de Moore ou non, les progrès semblent sans limite.
Parce qu'il reste l'histoire du traitement quantique des calculs.
Et tout cela uniquement grace à un univers qui a dans ses lois fondamentales la possibilité d'accéder techniquement à tout cela.
Par contre, la place d'une créature de chair libre et qui pense, me semble compromise dans ce monde technologique.