
Quoi de neuf côté gaming ?
Avec une version musclée dotée de 12 cœurs Xe au programme, Intel ne pouvait pas faire l’impasse sur une mise à jour de sa partie iGPU. En dépit du récent accord passé avec NVIDIA, la feuille de route du géant bleu continue côté microarchitectures graphiques — de toute manière, les délais de développement empêchent toute influence du partenariat avec le caméléon sur cette génération. Ainsi, notre Panther Lake introduit pour la première fois Xe a.k.a. Celestial dans sa version 3 auprès du grand public, tout comme Lunar Lake présentait en avant-première Xe2 — Battlemage. En ce temps-là, l’iGPU était nommé Intel Arc 140V dans une optique de rupture avec les iGPU Intel Iris / Arc précédents… mais en totale incohérence avec la série B (B580/B570) sortie dans un second temps sur cartes dédiées. Avec Panther Lake, Intel fait des progrès avec une nomenclature unifiée entre PC portable et PC de bureau, tout en restant dans l’incohérence la plus totale, puisque ce GPU — Celestial, pour rappel ! — sera nommé BXXX, tout comme les Battlemage. Enfer, hérésie ? Techniquement parlant, ce choix est un non-sens ; mais Intel peut encore se rattraper si l’écart en performance demeure similaire à la numérotation. Il n’y a pas si longtemps, un concurrent rouge proposait une gamme de GPU allant de la R7 270X à la R9 290X en recyclant 3-4 microarchitectures différentes sans pour autant verser dans le n’importe quoi. Si (et seulement si !) ces Arc se nomment B350 ou B380 et viennent complémenter les actuelles Battlemage en s’insérant en dessous ; alors "pourquoi pas". Après tout, Alchemist, Battlemage ou Celestial, le consommateur n’en a que faire tant que les performances sont au rendez-vous et la gamme claire.


Tout comme la tuile de compute et la tuile SoC, la tuile GPU a droit à deux versions : une à 4 cours Xe, manufacturée en Intel 3, et l’autre à 12 cœurs Xe, en TSMC N3E. Cela n’empêchera pas la maison-mère de désactiver des unités pour constituer une gamme plus étagée !
Ces considérations de nommage étant éclaircies, passons au gros morceau : la microarchitecture !
Xe3, en exclusivité sur les puces mobiles
Comme la grande majorité des architectures matérielle, Xe3 n’est pas parti d’une feuille blanche : les fondations lancées par Xe et Xe2 sont en grande partie réutilisées, ce qui se ressent dès l’organisation logique : des Rendering Slices sont composées de Xe Cores, eux-mêmes subdivisés en Vector Engines et unités matricielles XMX. Commençons par ces unités élémentaires, avant de remonter petit à petit jusqu’à la tuile graphique dans son intégralité.


Si la structure des unités de calcul des Vector Engines ne change pas — les unités natives SIMD16 sont toujours de la partie —, toute la circuiterie environnante évolue. En effet, l’unité est désormais capable de faire mouliner 25% de threads supplémentaires en passant de 8 à 10, menant fatalement à une meilleure utilisation des unités (moins de temps inactives) et donc des performances en hausse. De plus, les registres sont désormais dynamiquement alloués, ce qui permets d’éviter les couteux spills (allers/retours d’une valeur en mémoire par manque de place) dans le cas où les besoins en registres des différents threads soient hétérogènes. Cette optimisation vous dit quelque chose ? Pas étonnant : cette distribution est l’un des changements apportés par RDNA4, sortie en début d’année dernière ! N’allez toutefois pas prétendre qu’Intel ait copié : une nouvelle microarchitecture se construit sur 3 à 4 ans, il semble donc très improbable qu’un échange d’information ait eu lieu à ce niveau. Enfin, les unités prennent en charge la dé-quantisation FP8, c’est-à-dire la conversion d’un flottant faible précision sur un format plus large, ce qui peut se révéler utile pour de l’optimisation de réseaux de neurones.


Du côté des unités XMX, rien ne change par rapport à Xe2 : même performance par cycle, même précisions. En même temps, l’augmentation du nombre de threads indique une sous-utilisation des ressources : inutile donc d’augmenter la puissance de calcul par unité. En revanche, l’intégration d’un plus grand nombre d’entre elles permet d’afficher de gros gains en performances brutes, c’est ainsi que les 67 TOPS de Lunar Lake se meuvent en 120 TOPS sur Panther Lake. Youpi !
En dézoomant un peu, les cœurs Xe sont (toujours) composés de 8 unités vectorielles et des unités XMX qui leur sont accolées, mais le cache L1 / scratchpad (Shared Local Memory) qu’il intègre progresse de 33 % pour atteindre 256 Kio. Similairement aux CPU, l’ajout de L1 sur un GPU se traduit par une amélioration globale de la performance, les threads étant moins susceptibles de se retrouver bloqués par l’attente d’un chargement mémoire.


Les autres accélérateurs présents dans le GPU, à savoir les Fixed Functions chargées d’exécuter une partie des primitives graphiques et les unités de Ray Tracing, sont elles aussi revues. Pour les premières citées, Intel communique sur un nouveau module de gestion du buffer unifié (l'URB, pour Unified Return Buffer), chargé de partager des données locales au GPU entre threads d’un même contexte, ainsi qu’un doublement du débit en cas de filtrage anisotropique et d’accès au stencil buffer, particulièrement utilisé pour le rajout d’ombres en rastérisation. Pour la raie tracée, les changements sont moins évidents avec un nouveau système de gestion dynamique des rayons, ce qui permet de limiter les synchronisations avec les unités vectorielles et mener à toujours plus de performances. Tout comme la génération précédente, ces unités de RT sont intégrées à raison d’une par cœur Xe : le gain principal en performance reviendra donc à la multiplication des unités — comme très souvent sur un GPU.




Enfin, et cela va rappeler une nouvelle fois le concurrent rouge, Intel a été gonfler son L2 en passant de 8 Mio à 16 Mio, un cache qui permet notamment de stocker la frame en cours de calcul ainsi que certaines des données qui y sont associées. Similairement au L3 des CPU, le L2 des GPU est finement ajusté de manière à de retenir que les données les plus susceptibles d’être réutilisées, la firme nous ayant confiés avoir certaines optimisations secrètes propres aux charges de rendues graphiques à l’œuvre ici. Si la solution technique ressemble fortement à l’Infinity Fabric de RDNA, c’est parce que le but recherché est le même : limiter le traffic avec la mémoire vidéo, pour Panther Lake du fait d’une LPDDR5 / DDR5 limitée à son bus 128-bit et son débit en retrait par rapport à la GDDR ; pour AMD afin d’éviter un coûteux passage à la GDDR7.


Par-dessus toutes ces modifications microarchitecturales, Intel a été améliorer la scalabilité de sa troisième révision de Xe en augmentant le nombre maximal de Xe Cores par slice de 4 à 6. Ainsi, les deux versions de la tuile graphique intègrent au choix soit deux slices de 2 cœurs Xe (version 4 cœurs) ou 2 slices de 6 cœurs Xe (version 12 cœurs).






Notez que les slices munies de 2 cœurs se voient également limitées en partageant un pipeline de transformations géométrique contre 2 pour la version à 12 cœurs ; tout comme le nombre de backend pixels (dernier étape du pipeline de rendu, permettant notamment d’effectuer le mélange des couleurs en RGBA ou HDR), contenu à 1 par slice sur le petit die, 2 par slice pour le gros.


Du côté des performances
Bien qu’Intel se garde de toute mesure de performances absolues — c’est-à-dire de comparaisons en situation réelle —, la firme nous gratifie tout de même d’illustrations démontrant le bien-fondé des changements architecturaux. Dans l’image ci-dessous, l’axe des abscisses correspond à chaque appel de l’API bas niveau effectué lors du rendu d’une frame, et l’axe des ordonnées indique le temps nécessaire pour effectuer chaque opération. Ainsi, une courbe en dessous indique une opération plus rapide, et donc un iGPU plus performant.


Selon l’opération, diverses modifications architecturales permettent des gains plus ou moins significatifs : les prépasses bénéficient des changements des unités vectorielles (plus de threads et allocation dynamique de registres), la passe de base aime le cache L2 plus volumineux puisqu’elle utilise massiblement les données de la frame courante ; et les étapes finales de calcul asynchrones et de shaders raffolent elles aussi des registres dynamiques et du L1, probablement du fait de la présence de variables locales aux threads dépendant des effets calculés.


Une autre manière de quantifier les gains réside dans les microbenchmarks : des petits morceaux de code chargés de mesurer une quantité précise — comme nous faisons pour les latences de caches sur notre protocole CPU par exemple. Vu la progression de 50 % sur GEMM (multiplication de matrice) et FP32, Intel compare ici ses 8 cœurs Xe2 aux 12 cœurs Xe3, mais puisque les deux iGPU se reposent sur 2 slices, la baseline n’est pas si mauvaise.

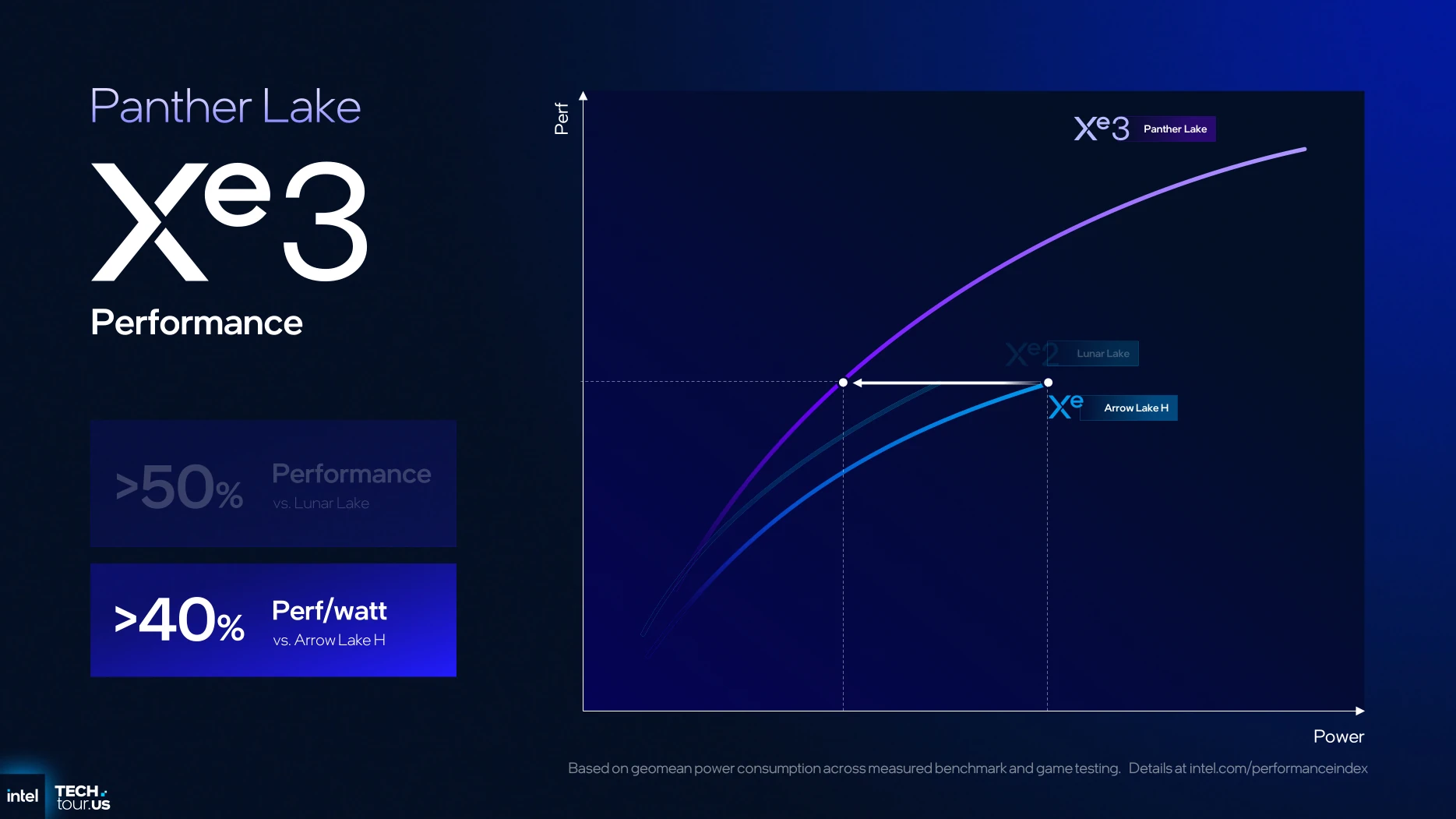
Pour finir sur les comparaisons par rapport à la génération précédente, Panther Lake devrait offrir dans sa plus grosse version quelques 50 % de performances supplémentaire à iso consommation par rapport à Lunar Lake, ou 40 % d’amélioration en matière de performance/watt comparée à Arrow Lake. Reste à voir en pratique !
XeSS3, maintenant avec la génération d’images
Si les évolutions hardware sont passionnantes, la puissance n’est rien sans la maîtrise, c’est-à-dire le logiciel. Et, sur cet aspect-là, les bleus continuent sur leur lancée : commençons par la prise en charge de Cooperative Vectors, une extension de DirectX 12 permettant de standardiser l’utilisation des unités dédiées (XMX en l’occurrence) via l’API DirectX. En décodé, l’utilité est d’uniformiser via DirectX la programmation des upscalers, de manière à éviter la coexistence DLSS/FSR/XeSS dont chacun doit faire appel à ses propres bibliothèques : un vrai casse-tête pour les programmeurs.


Tant qu’à parler d’XeSS, ce dernier se met à jour en version 3 pour apporter le Multi Frame Generation : la capacité à prédire par IA plusieurs images et les intercaler avant le rendu réellement calculé par la carte, tout comme ce que le DLSS 4 avec FG propose chez NVIDIA. Comme à l’accoutumée avec Intel Graphics, la fonctionnalité débarquera d’abord sur Xe2 et Xe3 (Arc série B et Intel Core Ultra 200V), mais devrait rapidement être étendue à toutes les générations Xe équipées d’unités matricielles (soit toutes sauf Xe première du nom en version LP), voire ouvertes aux autres cartes AMD / NVIDIA — nous nous doutons toutefois que cela dépendra de l’état de leurs pilotes et de l’intégration des Cooperative Vectors abordés au paragraphe précédent. Notez qu’Intel utilise ici l’IA et non une unité dédiée pour le calcul du flot optique, la firme affirmant obtenir ainsi un résultat de meilleure qualité, ce que les verts auraient également fait peu après la sortie du DLSS 3 pour les mêmes raisons.


En couleur : unités vectorielles et matricielles, en gris : pipeline de géométrie. En haut : rendu RT traditionnel, en bas, XeSS 3, c’est-à-dire avec upscaling (étape XeSS-SR [Super-Resolution]) et MFG (dernières étapes du rendu).
Pour se plonger dans le futur, Intel nous a — lors d’un voyage presse à huis clos — gratifiés d’une démonstration de rendu en temps réel par IA. Comprenez, en excluant tout pipeline de rendu traditionnel, RT comme rastérisation. Nommée Neural Radiance Field, cette technologie consiste à entrainer un réseau à partir de rayons, en prenant en entrée la position et la direction de ce dernier, pour en déduire la couleur et la densité du matériau. Il en résulte une image dont le cœur est effectivement rendu par IA : est-ce la prochaine direction des moteurs de jeu ? L’avenir nous le dira, mais Intel y est déjà préparé.


Un service de shaders dans les nuages
Le côté logiciel n’est pas fini, car Intel a également été biglouché du côté du Steam Deck pour tenter de solutionner un temps de chargement : celui de la compilation des shaders. En effet, pour pouvoir exécuter des programmes sur le GPU sans distinction de leurs architectures, les jeux embarquent des shaders sous un format générique, ces derniers étant compilés (comprendre, traduits en langage machine pour votre GPU) lors de l’exécution du jeu, soit dans une longue phase au lancement, soit en cours de partie, ce qui peut entraîner des microsaccades. Dans le cas du Deck (et, plus généralement, des consoles), l’uniformité du matériel permet l’utilisation de shaders précompilés (et mieux optimisés), ce qui améliore les performances tout en réduisant les temps de chargement.


Vous le voyez venir ? Oui, Intel a mis en place un cloud, permettant au driver d’interroger un serveur pour vérifier si le shader en question n’a pas déjà été compilé et, le cas échéant, venir le télécharger. Il est ici question de 10 à 100 Mo, soit plus grand-chose en matière de bande passante ; et les bleus insiste sur un procédé qui vient en complément de la compilation locale et non en remplacement — encore heureux, il ne manquerait plus qu’une connexion internet soit requise pour l’intégralité de la ludothèque solo ! Si nous émettons des réserves quant à l’utilité réelle du schmilblick (stabilité de la connexion, risque de sécurité, durée de maintien des serveurs), Intel a au moins le mérite d’innover à ce niveau. De plus, cela ressemble fortement à un appel du pied vers une console portable basée sur Panther Lake 12 cœurs, pourquoi pas pour le CES ? En tout cas, aucune annonce officielle n’a fuité en ce sens… ni dans le sens contraire.
Comment optimiser un APU pour le jeu ?
Avec cette version à 12 cœurs Xe, Intel ne pouvait décemment pas ignorer le public joueur. Pourtant, optimiser un SoC pour cette tâche est plus ardu qu’il n’y parait, notamment du fait d’un équilibre subtil à trouver entre CPU et iGPU. En effet, du point de vue de l’OS, un jeu demande une brève, mais forte charge CPU, et ce de manière régulière. La tentation est forte de réveiller un P-Core, utiliser toute la puissance du turbo boost, puis aller tranquillement le rendormir jusqu’à la prochaine demande.
En limitant les sauts de fréquence…
Sauf que l’écrasante majorité des jeux exécutés dans l’enveloppe thermique prévue pour Panther Lake sont GPU-limited, c’est-à-dire que le taux d’image par seconde est limité par la puissance du GPU par un effet de seuil. Une première optimisation réside dans l’optimisation des politiques de gestion de la fréquence, et est déjà en place sur Lunar/Arrow/Meteor Lake. Nommée Intelligent Bias Control, la technologie s’est vue déployée en version 2 au cours du second semestre 2025 et a dès son arrivée amélioré les performances de la MSI Claw, seule console moulinant sous un SoC Intel à l’heure actuelle.


Son principe : limiter les variations inutiles de fréquence en limitant ces dernières via le firmware lorsqu’un jeu est détecté côté driver. Il en résulte une drastique baisse de la consommation de la partie CPU, ce qui offre de précieux watts à la partie GPU.


Moins de pics de consommation, moins de Watt engloutis pour rien par le CPU : de quoi laisser à l’iGPU la capacité d’exprimer pleinement son potentiel.
Testée sur une Arc 140V — l’iGPU de Lunar Lake, l’amélioration est plus que conséquente, avec des gains à deux chiffres mesurés, tant en matière de 1% low (microsaccades) que de taux d’image par seconde moyen. Bref, une réussite pour les bleus pour l’ancienne génération, qui se retrouve également sur la nouvelle, Panther Lake.


Comment ? De vrais chiffres ? Pas de panique, il s’agit d’une partie graphique déjà disponible sur les étals !
… Et en modifiant l’ordonnanceur !
Avec Panther Lake, Intel a fait une seconde constatation : l’utilisation conjointe des LP E-Core et des P/E-Core du cluster haute performance est, dans la plupart des cas, superflues du point de vue des performances en jeu. Du fait du partage de données entre le L3 et les LP E-Core menant à des aller-retour des données par le bus central — jumelé à une charge GPU-limited, rappelons-le —, les LP E-Core sont tout aussi bien désactivés. Pire encore, les E-Core non LP, gonflés par leur accès au L3, sont dans la majeure partie des cas suffisants pour les jeux, en tout cas dans les réglages utilisés en pratique.


Avec Panther Lake, quand une charge graphique est détectée, le driver va une nouvelle fois interagir avec l’Intel Thread Director par l’intermédiaire de l’Intelligent Bias Control en version 3, et l’informer de ce qui se trame. La politique d’ordonnancement va alors évoluer pour interdire les LP E-Core et prioriser les E-Core. Au besoin, les P-Core sont bien évidemment disponibles, comme le montre l’exemple ci-dessous sur Control. Si l’OS devrait s’en charger, Windows n’a en pratique qu’une vue limitée des tâches réellement exécutées par les processus : le pourcentage d’utilisation du GPU dans le gestionnaire des tâches n’informe notamment que sur le nombre de processus dans les fils d’attente du GPU, et non leur contenu.


vs
Bien qu’efficace en pratique — tous les mécanismes sont bons pour donner plus de Watts au GPU —, nous avons toutefois du mal à y voir autre chose qu’une usine à gaz dans laquelle l’OS, incapable de reconnaître les caractéristiques des threads qu’il manipule (et les threads incapables de s’identifier correctement…), doit avoir recours à une télémétrie du driver pour passer des informations au firmware, qui va lui-même restituer ces conseils via Intel Thread Director pour que le scheduler — retour à l’OS, donc ! — fasse correctement son travail. Une étrange boucle au niveau du système d’exploitation, que Valve solutionne de manière bien plus élégante sur le Linux de son Steam Deck via sched-ext, un mécanisme permettant de contrôler l’ordonnancement directement depuis l’espace utilisateur sans avoir besoin de passer par le driver graphique.


C’en est tout pour la partie GPU et gaming… mais pas pour ce qui est du traitement d’image : rendez-vous page suivante pour découvrir l’IPU, un composant peu connu des SoC mobiles.




Les évolutions architecturales sont faible mais l'augmentation du nombre d'unité cpu/gpu va dans le bon sens
Le 12 xe sera t il disponible a faible tdp ?
J'ai peur que face a un apu 12 core zen 6/6c 16 core cpu mais 12 e/lpe core ça ne va pas etre suffisant
Côté gpu intel va etre devant amd en attendant udna
Pas d'infos sur les SKU officiellement, il faut regarder les rumeurs. Néanmoins, il est très souvent possible de brider les puces avec un faible TDP (ou les faire thermal throttle dans le pire cas).
Appriorie pas de 12 xe en version u dommage