
Après maints reports (la carte ayant été montrée dès le CES en janvier dernier), voilà que les RX 9070 et sa version XT se retrouvent enfin précisées dans leur intérieur, en attendant les quelques jours nous séparant des tests en bonne et due forme. Des caractéristiques qui n’avaient d’ailleurs pas manqué de fuiter (une constante des derniers lancements), mais de manière incomplète : aucune mention architecturale n’était alors présente, or nous attendons à ce niveau bien des changements. Progrès dans le domaine du lancer de rayon, des unités IA, des unités classiques… Alors, qu’est-ce que RDNA 4 a dans le ventre ? La réponse après un premier tour d’horizon des cartes.

RX 9070 et RX 9070 XT, en bref
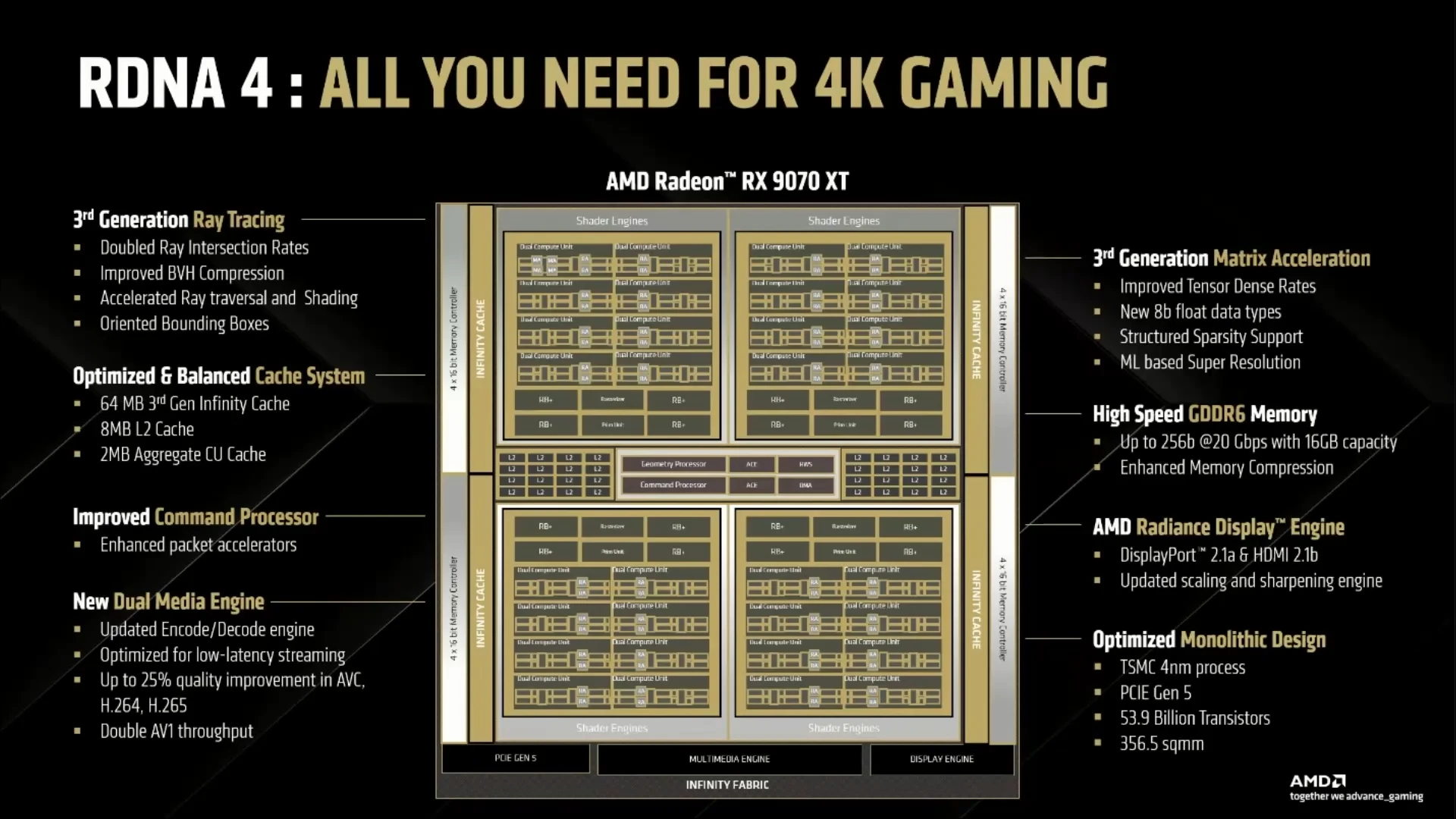
Après un essai RDNA 3 reposant sur des chiplets afin de limiter les coûts, la question pouvait se poser quant à la structure de la prochaine microarchitecture, RDNA 4. Finalement, le design monolithique usuel a été retenu, avec un TSMC N4 optimisé aux commandes, AMD communiquant cela comme étant « le meilleur équilibre entre performance et coût ». Comprenez par là que se rajouter un interconnect entre die dans une puce dont le but est de traiter un sacré tas de données en parallèle apporte ici plus de complications que de solutions ! Trêve de détails techniques, et place aux cartes :
| Carte | Radeon RX 9070 XT | Radeon RX 9070 |
|---|---|---|
| Architecture | RDNA 4 | |
| GPU | Navi 48 | |
| Unités de calcul | 64 | 56 |
| Processeurs de flux | 4096 | 3584 |
| Fréquence GPU Boost | 2970 MHz | 2520 MHz |
| Infinity Cache | 64 Mio | |
| VRAM | 16 Go GDDR6 | |
| Débit binaire VRAM | 20 Gbps | |
| Interface VRAM | 256-bit | |
| Bande passante VRAM | 640 Go/s | |
| TGP | 304 W | 220 W |
| Interface PCIe | PCIe 5.0 x16 | |
| Alimentation externe | 2 x PCIe 8 broches | |
| Prix conseillé | 599 $ | 549 $ |
| Disponibilité | 6 mars 2025 | 6 mars 2025 |
Des caractéristiques qui ne doivent pas vraiment vous surprendre tant les leaks ont été légion à leur sujet, et qui placent — sur le papier — les nouvelles venues aux alentours de la RX 7800 XT (60 CU/2840 SP @ 2430 MHz et 16 Gio de GDDR6), avec presque le double de transistors : 59,3 milliards pour la nouvelle venue, contre 28,1 milliards pour la RX 7800 — sans compter ses dies de mémoire toutefois. Prometteur, vous dites ? Sans performance difficile pour le moment de se projeter précisément, mais nous avons par contre les prix ! AMD fixe des prix conseillés à 549 $ pour la Radeon RX 9070 et 599 $ pour la Radeon RX 9070 XT ce qui est vraiment agressif par rapport aux performances espérées. Notez également l'adoption du PCIe Gen 5.0 pour l'interface avec le CPU, emboitant ainsi le pas des RTX 5000 à ce niveau. Continuons à présent notre analyse sur le papier avec les détails techniques.
RDNA 4
Comme toutes les architectures GPU modernes, RDNA 4 se doit d’évoluer non seulement au niveau des performances brutes (comprendre, en rastérisation/GPGPU), mais également sur des deux autres fronts inaugurés il y a quelques années : le Ray Tracing et l’IA. Dans ces deux cas, les rouges souffraient d’un retard par rapport à la concurrence verte, pionnière du secteur, bien qu’AMD ait réussi à camoufler tant bien que mal la déficience côté machine learning (c’est-à-dire des performances en multiplication de matrices en retrait) au moyen d’une implémentation FSR s’en passant, mais avec un résultat visuel de moindre qualité. Or, avec le FSR 4 (que nous détaillerons ultérieurement), la firme de Lisa Su a également basculée sur l’IA, requérant de ce fait un support matériel et, ainsi, une mise à jour hétérogène de la brique de base de la microarchitecture : les Compute Units (CU). Voyons cela en détail, d’abord par le côté « classique » du CU, avant de plonger sur la partie matricielle puis l’accélérateur de Ray Tracing.

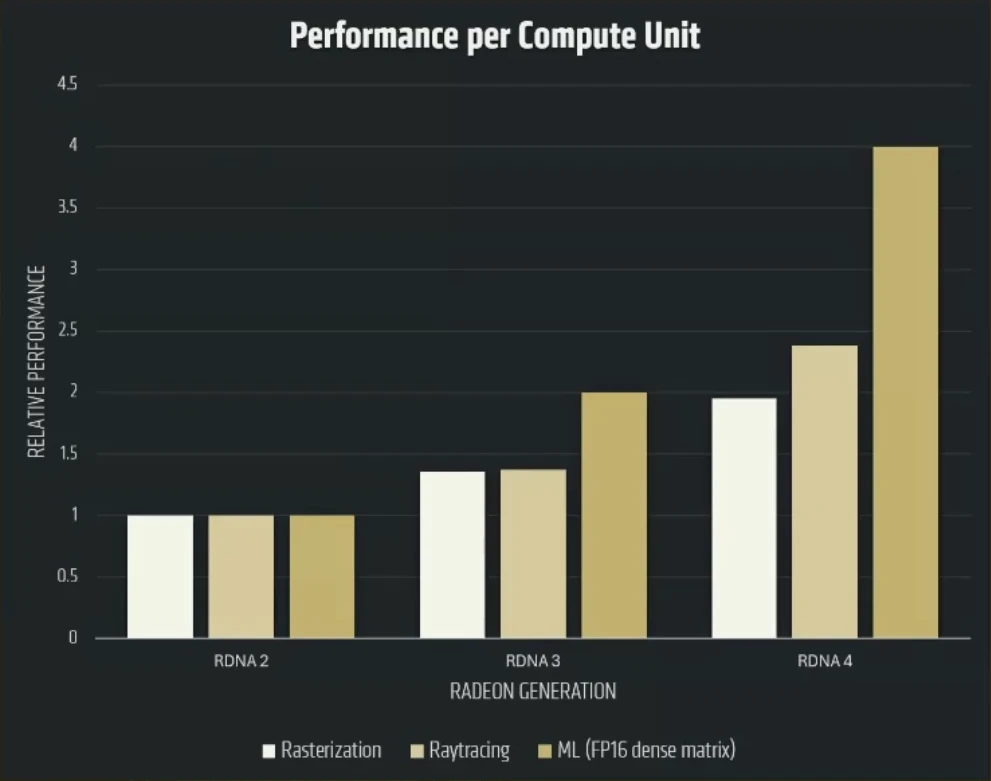
Des CU plus compétents, mais toujours en dual issue
Au niveau de la structure interne, les CU demeurent « dual issue » et conservent la particularité introduite avec RDNA 3 d’intégrer non pas une, mais deux unités vectorielles SIMD32 : une principale et une auxiliaire. Ces deux unités sont en théorie utilisables en parallèle — en pratique la chose est plus complexe et soumise à de nombreuses conditions — via l’instruction VOPD. En fait, RDNA 4 reprend la majeure partie de la structure logique de la génération précédente, dont l’accouplement par deux des CU (nommés également WGP pour WorkGroup Processors… mais qui n’a rien à voir avec le Dual Issue !). Nous retrouvons ainsi nos deux unités vectorielles SIMD32, la principale gérant également les calculs entiers ; des unités « transcendantales » calculant les opérations complexes — inverse, racine carrée inverse, racine, puissance, logarithme, sinus, cosinus — en SIMD toujours, mais sur 8 éléments ; ainsi qu’une unité scalaire et une unité d’IA sur laquelle nous reviendrons plus en détail dans la sous-section suivante. Rassurez-vous toutefois, quelques améliorations viennent se glisser çà et là pour augmenter (toujours plus !) les performances dans le pipeline de rendu classique !
En effet, les unités scalaires sont désormais capables de calculer sur des opérations flottantes, limitant ainsi le travail des unités vectorielles dans certains cas. Des primitives de synchronisation supplémentaires apparaissent, à savoir les split and named barriers : la première autorise les threads à continuer à exécuter partiellement des opérations alors que la barrière est atteinte, et la seconde permet à un nombre restreint de threads d’appliquer la barrière de manière à spécialiser davantage les waves utilisées lors de l’ordonnancement des calculs. L’idée est ici de maximiser l’utilisation des unités et éviter au maximum les temps d’attente, même lors des synchronisations. En outre, les manipulations de registres par blocs de 32 (éventuellement en utilisant un masque pour en omettre) sont également améliorées, ce qui a pour effet d’accélérer les appels de fonctions. Similairement à ce qui se fait sur les CPU, des nouvelles instructions de prefetch ont été ajoutées, ce qui permet de rapatrier en avance des données dans le cache lorsque les mécanismes de prédiction sont dans les choux, évitant ainsi un blocage du pipeline au moment de leur utilisation.

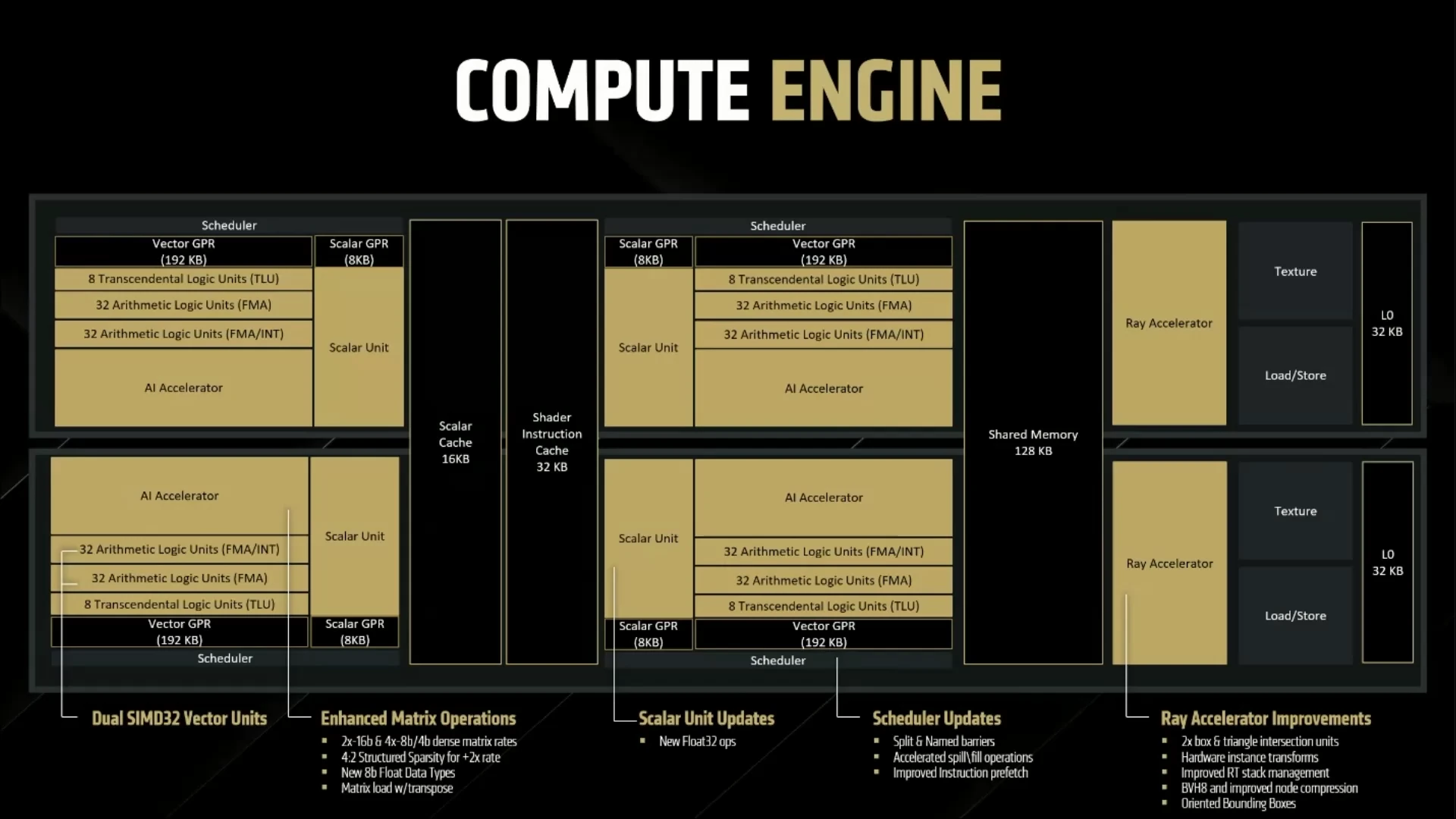
Comme toute la série des RDNA, les CU sont regroupés par deux pour mettre en commun leur cache, formant un (choisissez ce qui vous arrange) WorkGroup Processor/Compute Engine/Dual CU
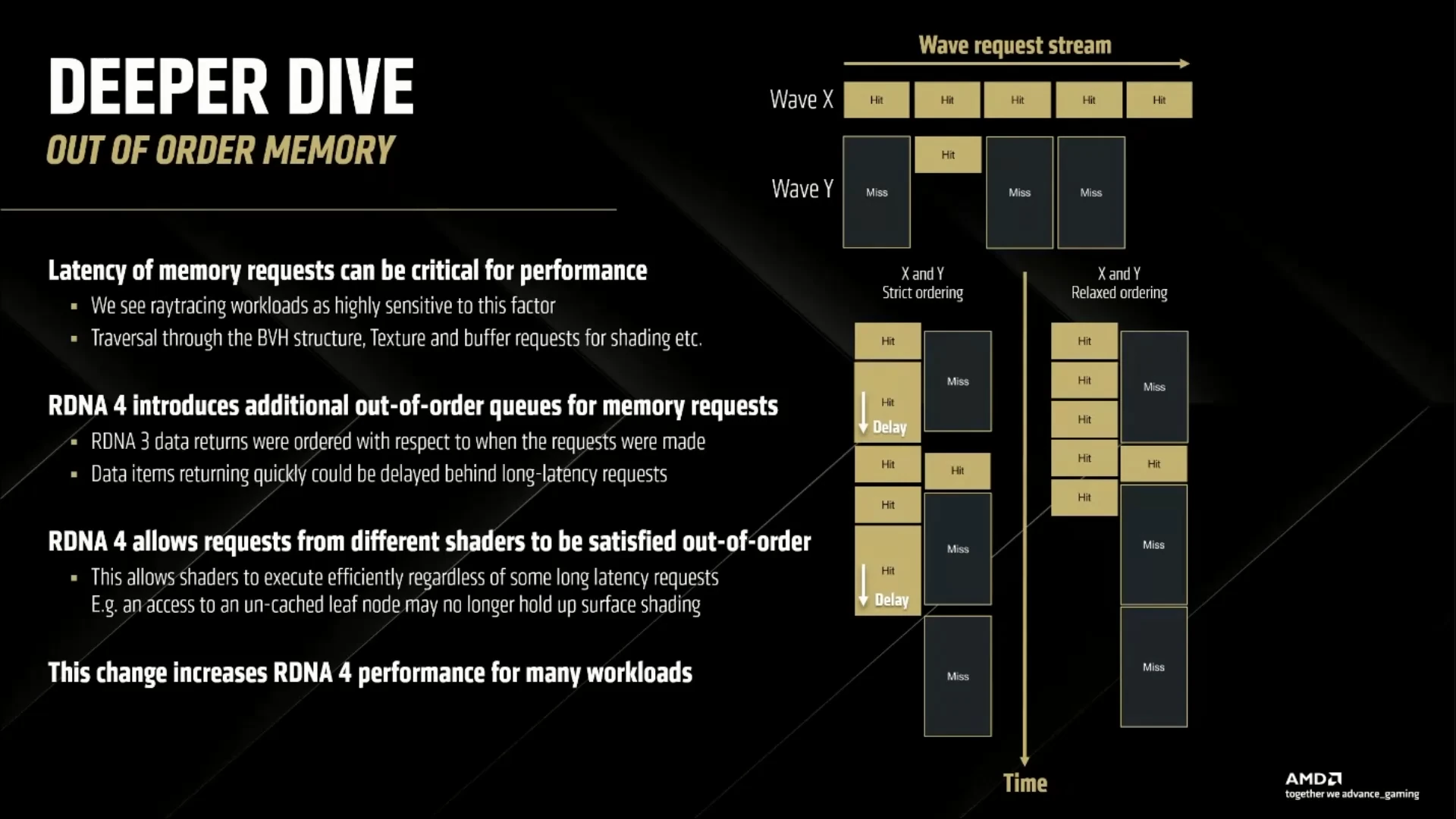
Or, si vous êtes familiers des modèles de programmation des GPU, cela signifie que ces instructions sont asynchrones : le GPU ne doit pas se bloquer pour attendre la donnée — autant faire directement le chargement plutôt que le prefetch. C’est ainsi que le modèle mémoire de RDNA 4 se relaxe en autorisant les chargements dans le désordre (ou Out-of-Order en anglais) : il est possible pour le sous-système mémoire de continuer à fournir les threads en données alors qu’une requête est encore en cours de traitement. Tant que les CU demeurent In-Order (c’est-à-dire que leurs instructions sont exécutées dans l’ordre d’arrivée, avec blocage complet si cela est nécessaire), l’intérêt est limité… sauf pour le Ray Tracing où le BVH (un algorithme utilisé dans ce cadre) et ses accès non-alignés, créent de nombreuses bulles dans les files d’attente mémoire, entraînant de potentiels ralentissements sur d’autres threads. Avec RDNA 4, l’exécution des requêtes mémoires dans le désordre — couplés aux 64 Mio d’Infinity Cache, qui passe en troisième génération sans plus de précision sur leur évolution — évite ce phénomène.

Enfin, la dernière nouveauté de RDNA 4 prend place dans l’allocation de registres. Usuellement, les charges de travail (graphiques ou scientifiques) des shaders sont régulières, c’est-à-dire que l’on peut facilement approximer le nombre de registres, les calculs et l’empreinte mémoire des programmes sans avoir à les exécuter. Avec le lancer de rayons, cela n’est plus le cas, notamment parce que la trajectoire d’un rayon après rebond est imprévisible. Sur RDNA 3, le GPU utilisait un nombre de registres fixe par shader, suffisant pour être sûr de pouvoir le nourrir correctement tout au long de son exécution : une approche correcte, mais qui résulte en une utilisation incomplète des ressources matérielles lorsque la période pendant laquelle tous les registres sont utilisés est courte (cf. schéma ci-dessous).

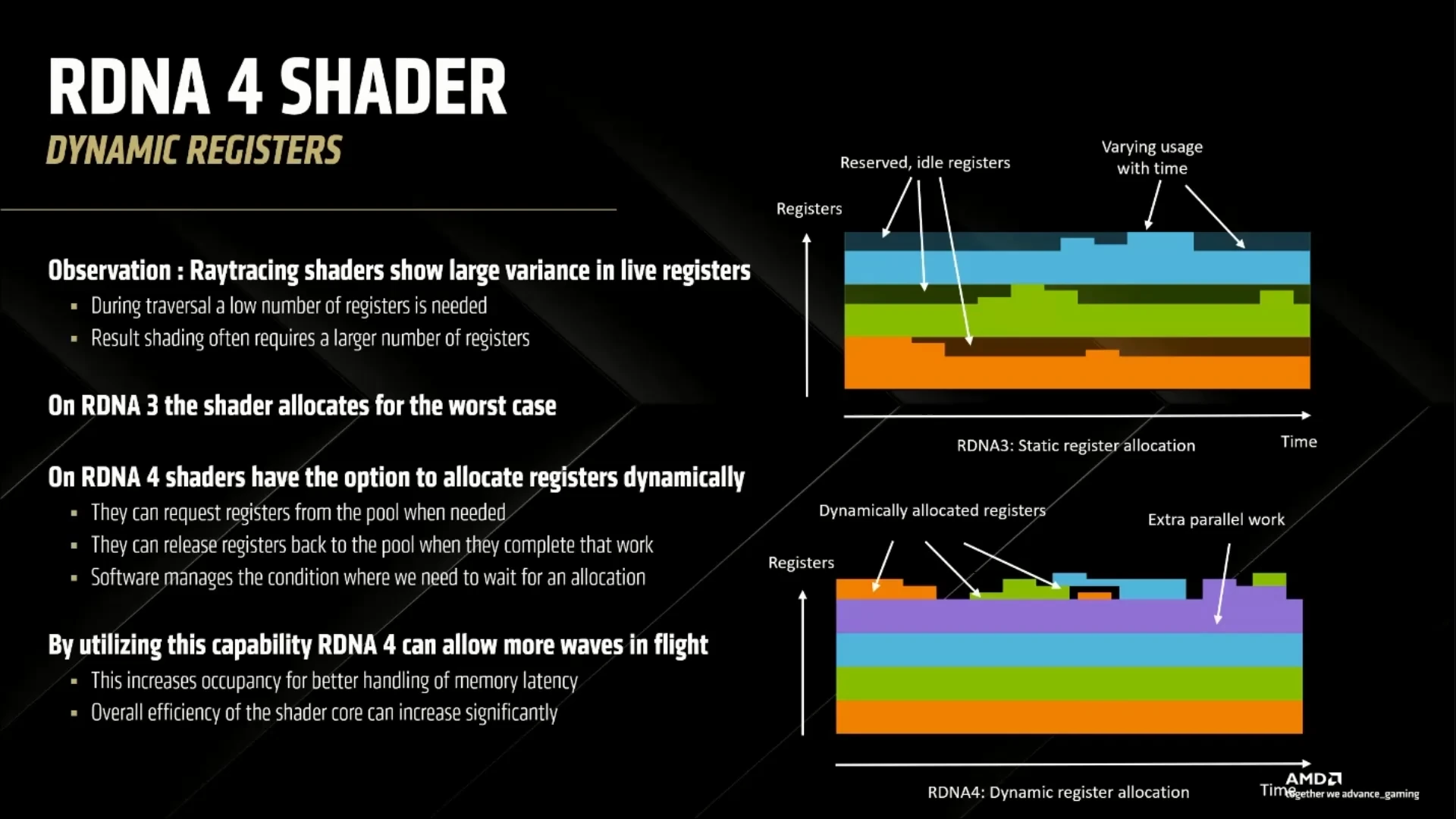
La solution proposée avec RDNA 4 est d’offrir un mode (facultatif) dynamique d’allocation permettant de piocher à la demande dans une pile de registres disponible à tous. En cas de famine (pas assez de registre pour tout le monde), la partie logicielle viendra stopper le shader le temps que l’un d’entre eux se libère. Sur le papier, cette optimisation permet d’améliorer l’efficacité du GPU en autorisant l’exécution concomitante d’un nombre accru de shaders ; encore faut-il savoir l’utiliser correctement !
Des cœurs IA plus versatiles
Alors que CDNA — l’architecture pour data center d’AMD — intègre des unités matricielles puissantes capables d’opérer en FP32 complète, que l’on aurait pu penser débarquer sur ces RX 9000, RDNA 4 suit en fait timidement la voie de RDNA 3. Ainsi, point de cœurs matriciels à proprement parler (les rouges conservant ce terme pour ceux de CDNA), mais des « IA Core » plus modestes limités au FP16 (le « F32 » marketing correspondant à des multiplications-accumulation sortant bien du 32-bit flottant, mais prenant en entrée du 16-bit flottant !). Cependant, la concurrence de NVIDIA n’est pas meilleure à ce niveau, puisque les Tensor Cores verts sont également dépourvus de capacité de traitement FP32 complet. En outre, la firme de Lisa Su n’a pas chômé, puisque RDNA 4 rattrape le retard des architectures précédentes en apportant la prise en charge de la sparsité à un facteur 50 % maximum (c’est-à-dire la capacité d’opérer sur des matrices composées d’un maximum de 2 zéros par blocs de 4 éléments), permettant de virtuellement doubler la capacité de calcul. D’ailleurs, cette capacité de calcul FP16 est elle aussi doublée pour culminer à 1024 opérations par cycle par CU (en mode dense) ; les rouges rajoutant au passage les formats de données FP8 et BF8 pour toujours plus de puissance pour les réseaux de neurones modernes.


De plus, RDN4 inclut des instructions de chargements globaux des données matricielles, dont un permettant de transposer à la volée des matrices lors de leur mise en registres, ce qui accélère grandement certaines opérations de calcul scientifique et de machine learning.
Au niveau des interfaces, les multiplications matricielles passent toujours par l’instruction wmma, mais l’effet de cette dernière est étendu pour prendre en charge les changements matériels. Intéressant, bien que le système demeure encore limité dans son utilisation. Il est par exemple toujours impossible d’effectuer ces multiplications matricielles en même temps que des opérations vectorielles au sein du même CU (il faudrait pour cela avoir recours à wgmma), ce que propose désormais la concurrence pour le grand public avec les neural shaders.
Toujours plus de Ray Tracing !
Depuis l’avènement du lancer de bâton rayons dans les jeux modernes, les Radeon ont été frileuses dans ce domaine et offrent des performances bien en deçà des concurrentes vertes. La « faute » incombant au choix d’intégrer des cœurs aux capacités limitées, ce qui permettait par contre de réduire la taille de la puce, et, ainsi, son coût. Avec RDNA 4, la prolifération de la technique de rendu sur la scène triple-A ne donne guère d’alternative : les rouges doivent se mettre à niveau là-dessus !

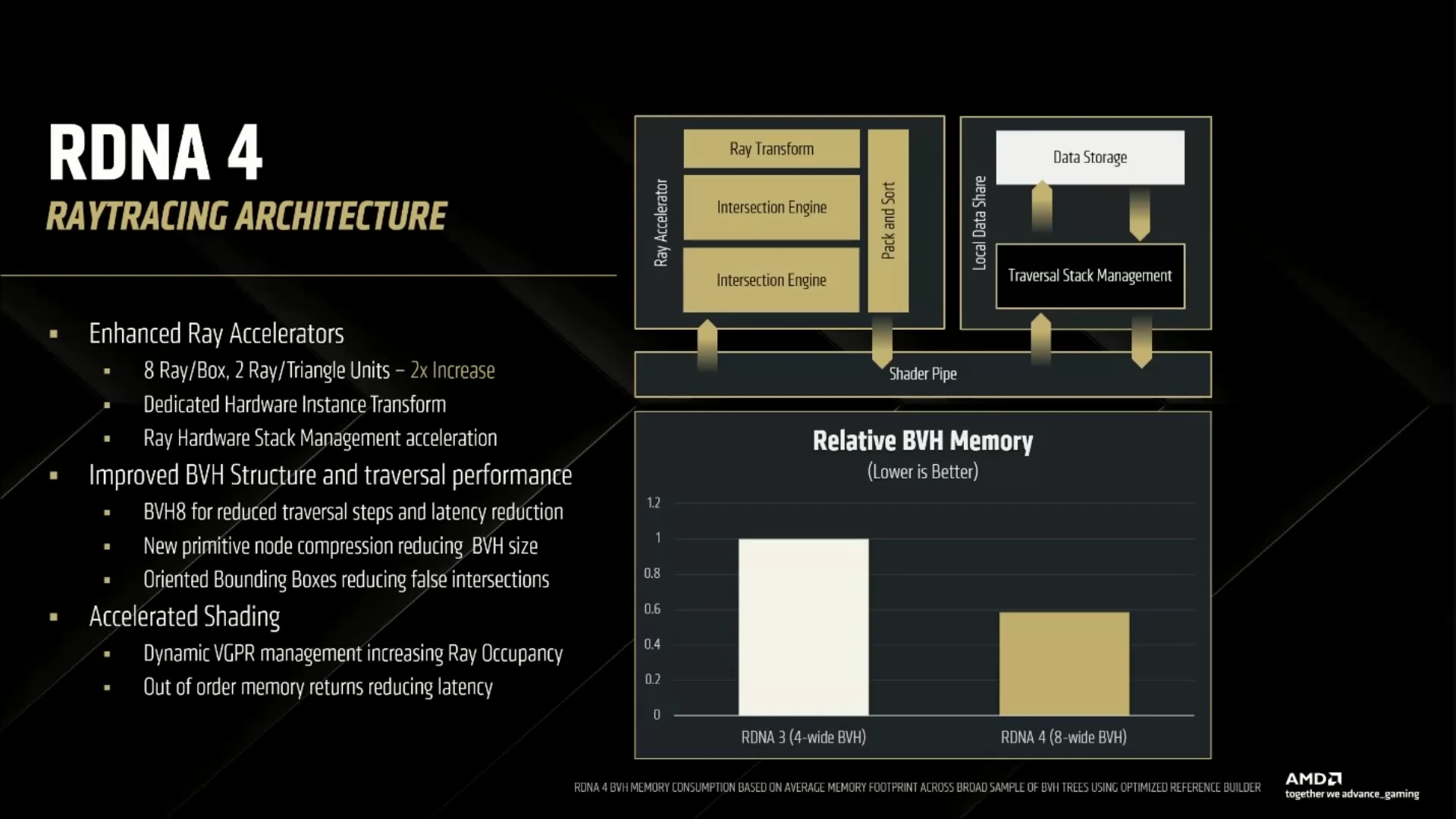
Et (sur le papier tout du moins) force est de constater que l’innovation est bien là. Déjà, le débit des unités BVH (Bounded Volume Hierarchy, une des étapes du Ray Tracing), est doublé par l’ajout d’une unité supplémentaire Intersection Engine, également chargée des collisions rayons-triangles. De ce fait, les cœurs RT travaillent désormais sur un arbre à 8 branches maximum par niveau au lieu de 4, ce qui réduit fatalement la profondeur de la structure, et donc le nombre d’étapes pour en venir à bout. C’est tout ? Non, une structure de donnée plus compacte de 40 % a également été développée afin de réduire l’empreinte mémoire du Ray Tracing pour toujours plus d’efficacité et moins de pollution des caches.
De plus, une unité de transformation des rayons est ajoutée pour traiter les opérations de modification de la structure du rayon tout au long du parcours du BVH. Auparavant, ces dernières étaient exécutées sur la partie classique des CU, ralentissant le rendu. Citons également des améliorations au niveau de la gestion de la mémoire tampon de 128 kio par double-CU gérant les structures du BVH (Local Data Share sur le slide précédent, ou Shared Buffer sur celle des CU) en rajoutant de nouvelles instructions permettant une gestion plus fine des données.


Enfin, là où NVIDIA proposait sur Blackwell des unités de gestion des brins (cheveux, herbes, etc.), AMD s’est concentrée sur un autre aspect : l’orientation des boites. Si les boites traversées par les rayons ont traditionnellement des arrêtes parallèles aux axes (comprendre, verticales ou horizontales selon des paramètres spécifiques à la scène), cela n’est pas bien adapté pour certains objets situés en travers. Dans ces cas-là, la traversée du BVH est très souvent caduque, puisque même les boites contenant l’objet sont en fait majoritairement composées du… vide qui l’entoure. En autorisant des rotations au niveau des boites, il est possible de décrire avec plus d’efficacité les objets qu’elles entourent, et, ainsi, accélérer le parcours du BVH d’en moyenne 10 % selon la firme.


Mises bout à bout, ces améliorations permettent au total de doubler les performances dans les tâches de Ray Tracing ; bien que le progrès exact soit dépendant de la scène observée (i.e. de la structure traversée lors du BVH). De quoi limiter les baisses de framerate liés à l’activation de la technologie en jeu, qui pourra éventuellement être assistée par un FSR infusé à l'IA. C’est en tout cas l’objectif qui ressort des modifications effectuées au sein de l’architecture, bien plus concentrées sur les cœurs IA et le Ray Tracing que le pipeline de rendu classique. Évidemment, il nous reste encore à vérifier cela en pratique sur le banc de test !
Média Engine
Si les GPU servent principalement à jouer, ces dernières années ont vu proliférer le streaming, comprenez ici le fait de diffuser ses parties en temps réel auprès de ses amis et/ou public. Pour éviter de surcharger le CPU de cette tâche, les puces graphiques intègrent des encodeurs matériels — AMD AMF, Avanced Media Framework dans notre cas —, pour réaliser l’encodage desdites vidéos à la volée. Problème : la qualité de la vidéo de sortie dépend de l’implémentation du media engine chargé de faire la conversion, et AMD est notoirement en retard sur ce point. RNDA 4 prétend ainsi corriger le tir avec 25 % de gain en qualité annoncés en H264, 11 % en HEVC. Les performances sont également en hausse avec un gain en encodage de 30 % maximum en 720 p, et 50 % de gains lors des décodages sur les codecs AV1 et VP9. A voir en pratique via les retours des streamers.


Display Engine
Dernier pan de nos RX 9000 : le Display Engine, chargé de la transmission des images depuis le framebuffer jusqu’à l’écran. AMD est assez avare de détails à ce sujet, mais communique tout de même sur des améliorations de la consommation au repos sur les configurations multi-écrans (Éric pour sûr sortira son module pour tester cela !), une prise en charge matérielle des images précalculées (l’insertion des images tout juste calculées dans une file, de manière à limiter les synchronisations CPU-GPU à l’affichage de ladite image), et surtout l’insertion de Radeon Image Sharpening 2 directement à ce niveau. Ainsi, l’activation de l’option se résume à un unique bouton, quelle que soit l’API utilisée : cool ! Au niveau des connectiques, le classique duo DisplayPort (2.1 a) et HDMI (2.1 b) sont de la partie : pas de souci de compatibilité à ce niveau même si on notera que les RX 9000 se limite pour le premier à l'UHBR13.5 alors que les RTX 5000 proposent de l'UHBR20.


C’en est fini du détail de l’architecture RDNA 4, tout du moins sur papier. Car, pour avoir plus de précision au niveau des performances, nous allons encore devoir attendre quelques jours et la sortie des tests indépendants…

Un petit récapitulatif, ça vous dit ?




Vous pouvez suivre l'annonce officielle en direct sur Youtube si cela vous intéresse : LIEN.
Tout cela va dans le bon sens
Je reste déçu qu'il est pas visé 3 ghz
Pas mal du tout
Bonne nouvelle pour le prix MSRP! Il reste Le grand inconnu, le prix en boutique…
Je ne comprends pas qu'avoir 2 cartes annoncées avec environ 15 % de différence de perf mais seulement 50 $ d'écart
Comme la 7800 xt et 7700 xt
7700 xt qu'on voit nul part
L'écart de prix entre la 9070 et la 9070Xt est très étrange oui
Simplement parcequ'ils veulent vendre de la 9070XT et que la 9070 sert juste à écouler les die partiellement défectueux de la 9070XT, et comme ils en ont pas des tonnes, s'ils rendent la 9070 trop alléchante ils seront contraints soit d'avoir de la rupture de stock soit d'utiliser des die fonctionnels de 9070XT pour la 9070...ce qui serait débile pour eux donc.
L'autre objectif c'est de faire en sorte que le client se dise "a partir de 550$ je peux avoir une 9070, c'est cool, mais si je pousse un peu je peux avoir bien mieux avec la XT ! Alors que sans la 9070, peut-être que la XT serait considérée hors budget.
Propre ... ils ont travaillés ardemment chez AMD.
On va attendre de voir comment les AIB vont se gaver ou non avant de sabrer le champagne mais en tout cas si les 9070XT a 600$ existent bel et bien elle sera mienne !!
Va y avoir le même problème de rupture et donc le 700€ va vite se transformer en 1200€ comme pour la RTX 5070 Ti.
Si j'ai bien suivi, pour le Path Tracing ils vont faire une sorte de Ray Reconstruction, donc utiliser en même temps les unités Ray Accelerator et AI accelerator d'un Compute Engine? Par contre dans le même CU, c'est soit l'AI Accelerator, soit l'ALU/TLU, mais pas les deux en même temps? Ca veut dire pas de Neural Rendering, ou alors à un coût prohibitif?
Oui
Du coup, si j'ai bien suivi, ça met quand même RDNA4 en désavantage théorique par rapport à Blackwell, et même Ada, qui peuvent utiliser les cuda cores et les tensor cores simultanément? (même si pour des taches différentes dans le cas d'Ada).
Par rapport à Blackwell pour sûr, pour Ada c'est moins clair, on avait justement une discussion à ce niveau avec Nicolas hier soir.
Ada ne pouvait pas non plus utiliser les tensor cores et les unités vectorielles en même temps, c'est arrivé avec Hopper chez les pros uniquement (et timidement), puis vraiment avec Blackwell... Et NVIDIA a bien réussi a faire le DLSS 3.5 avec Ray Reconstruction dessus. En fait, le Ray Reconstruction nécessite d'avoir fini le lancer de rayons, donc mixer à ce moment matriciel et vectoriel n'est pas si utile (c'est pour ça que Blackwell cause de tout un tas de techno de compressions de textures / utilisation de l'IA dans le pipeline de rendu, qui, elles, bénéficient bien plus de ce parallélisme).