
Le 05 octobre 2022, Intel levait le voile sur sa série de cartes graphiques ARC A700. Ce n'était certes pas la première itération (pour carte graphique) de l'architecture Alchemist développée depuis des années sous la houlette de Raja Koduri, puisque l'ARC A380 destiné à l'entrée de gamme avait été lancée durant l'été précédent en catimini. Mais l'annonce officielle eut réellement lieu à l'occasion de ce lancement des premières cartes graphiques (de l'ère récente) réellement destinées aux joueurs.
Le résultat était encourageant, mais les pilotes n'étaient pas au niveau et conduisaient à un pari de l'acquéreur éventuel quant au support assuré par les bleus. Intel n'a toutefois jamais baissé les bras, sa solution logicielle étant de plus en plus robuste au fil des versions de pilotes. C'est dans ces conditions qu'il lance aujourd'hui la nouvelle génération de carte graphique ARC B500. Au programme, la nouvelle architecture Xe2 couplée à un procédé de fabrication plus performant pour le GPU BMG-G21 l'utilisant (TSMC N6 -> N5).

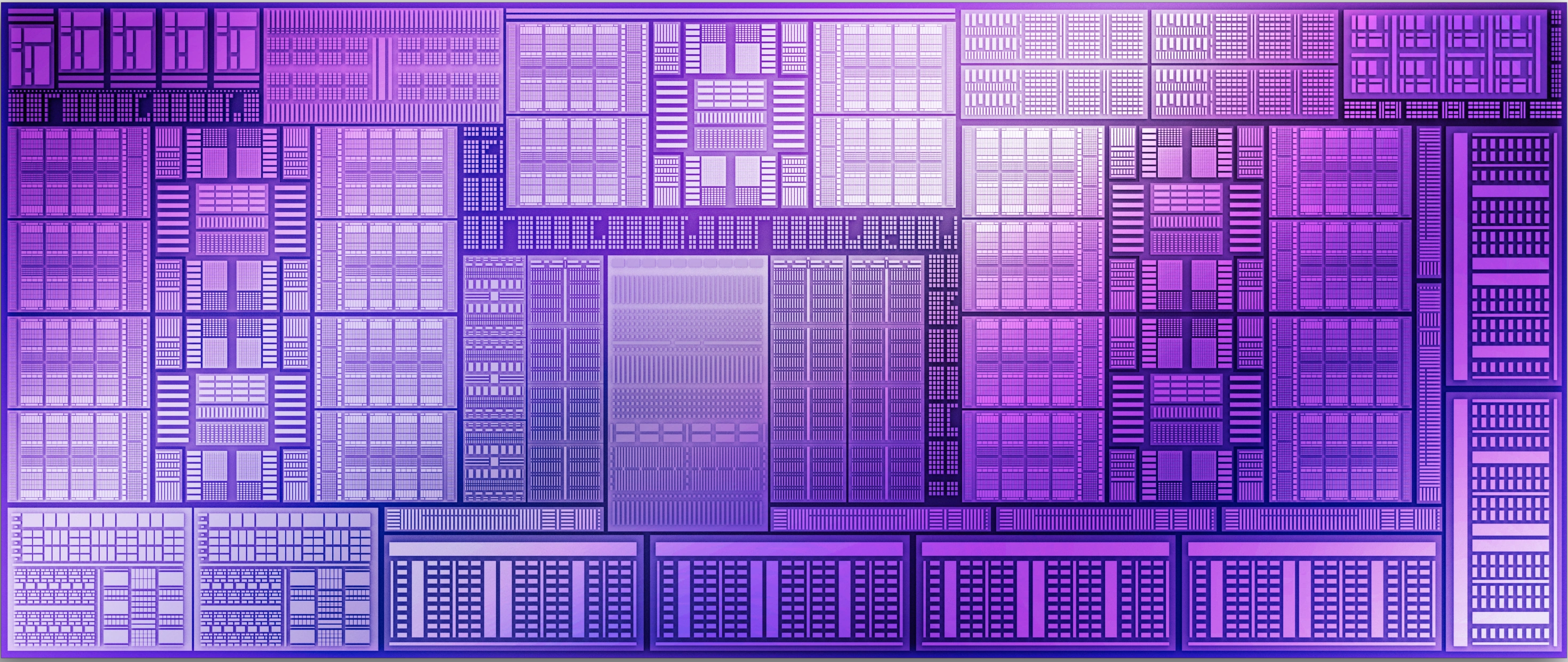 Die BMG-21
Die BMG-21
La représentation visuelle du BMG-G21
Côté architecture, nous vous invitions à relire notre page dédiée à Alchemist pour vous aider à appréhender les changements. En résumé, Battlemage s'articule toujours autour de blocs appelés Render Slice et qui correspondent grosso modo aux GPC chez Nvidia et Shader Engine chez AMD. Au sein de ces derniers, on va retrouver les Xe-cores ressemblant vaguement aux SM/CU des concurrents. Chaque Xe-core est constitué de 8 Vector Engines intégrant les unités de calculs. C'est ici qu'a lieu une des modifications profondes, puisque l'organisation de ces dernières est à présent du type SIMD16 (Single Instruction Multiple Data à 16 voies) au lieu des SIMD8, permettant d'exploiter davantage et plus efficacement les ALU.
En fait, les Vector Engines étaient sur Alchemist agencés par couple SIMD8 partageant une partie de la circuiterie logique de pilotage. Au sein de Battlemage, ce duo est à présent fusionné en une seule "grosse" unité. Le gros avantage est de revenir à une granularité davantage usitée dans les jeux, évitant ainsi à l'équipe drivers de devoir "optimiser à la main" les shaders pour tirer parti des spécificités de l'architecture. A noter également le support des opérations en SIMD32 par association de 2 Vector Engines. Le cache L1 et la mémoire locale sont toujours unifiés, mais la capacité totale passe de 192 Ko à 256 Ko. Les unités matricielles XMX (équivalent Tensor Core) doublent de leur côté le débit en passant à 512 opérations / cycle en INT8.


L'IA est donc une composante priorisée par Intel, nous y reviendrons un peu plus bas concernant les avancées logicielles basées sur cette dernière. Le Ray Tracing est la seconde composante qui a fait l'objet d'une attention particulière. La première implémentation nous avait séduits, devançant (à gamme de GPU équivalent) celle d'AMD pourtant dans sa seconde version. Intel augmente la puissance brute de ses unités avec des gains allant de 50 % à 100 % par rapport à la génération précédente. Le cache dédié au BVH est également doublé.


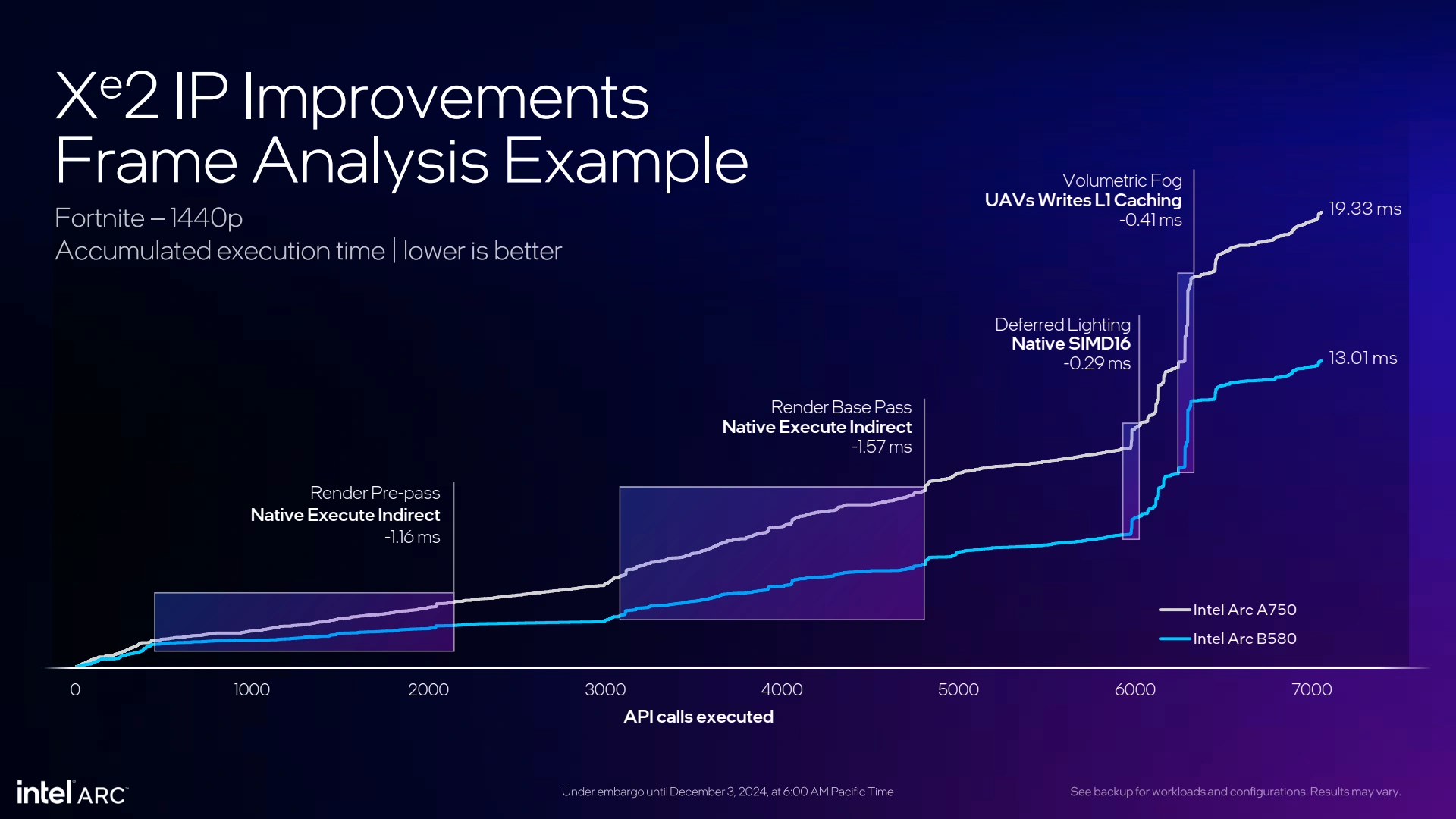
Intel annonce que les modifications apportées à son architecture (et les progrès du procédé de fabrication) permettent d'augmenter de 70 % les performances par Xe-core avec une efficacité énergétique progressant de 50 %. Parmi les gros pourvoyeurs de gains, on notera également qu'avec Alchemist, certaines tâches indirectes n'étaient pas exécutées nativement, faut de hardware capable de le faire. Certaines unités ont donc été réingéniées avec Battlemage afin de les exécuter nativement, conduisant à des gains colossaux à ce niveau entre générations.

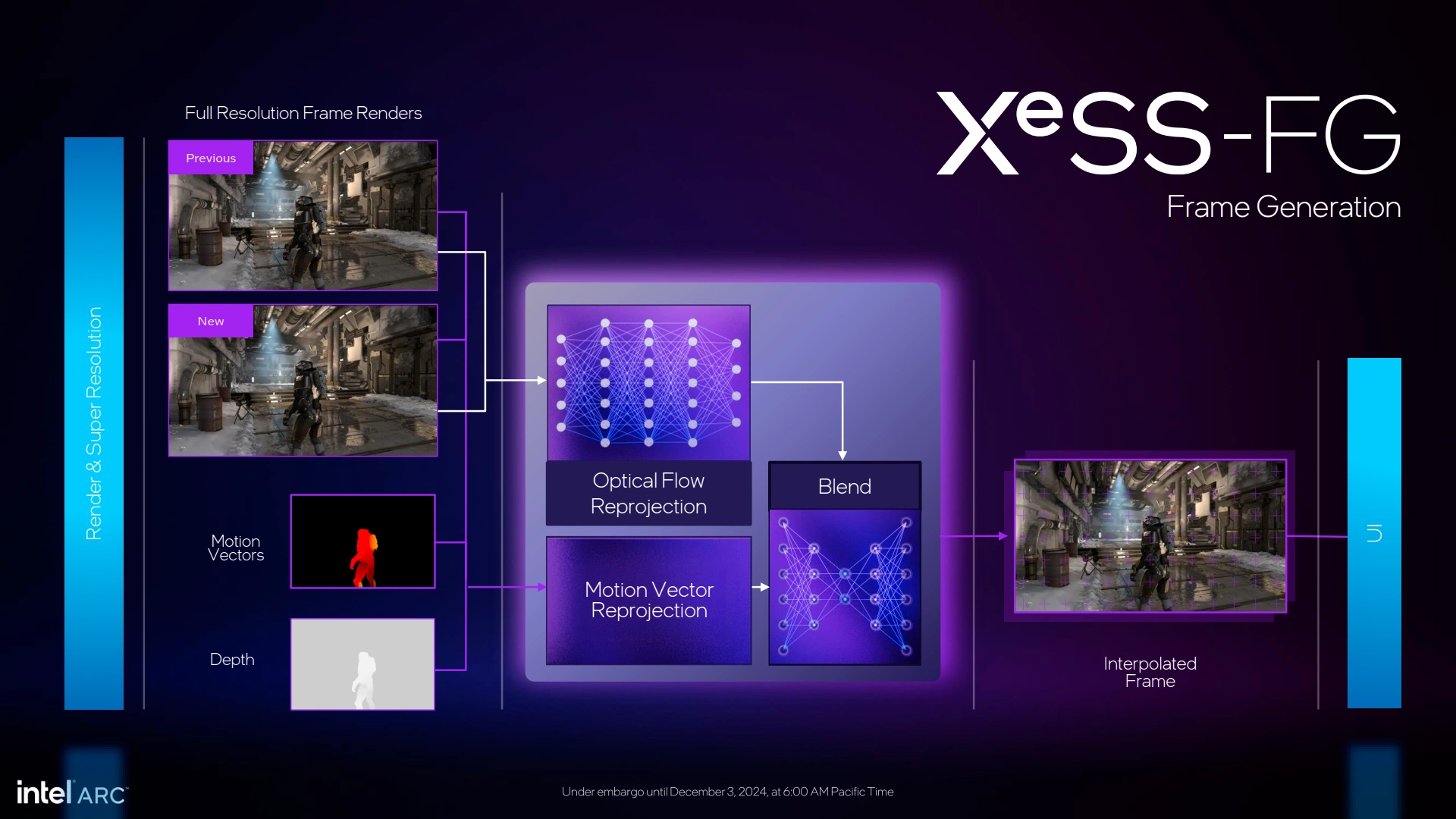
Côté nouveautés logicielles, XeSS2 est lancé officiellement. Ce dernier ressemble comme 2 gouttes d'eau au DLSS 3. En effet, on retrouve la composante upscaling matinée d'IA de la version initiale de XeSS nommée Super Resolution, à laquelle s'ajoute à présent une Frame Generation (XeSS-FG) ainsi qu'un mécanisme de réduction de la latence afin de contrebalancer l'effet négatif à ce niveau de l'insertion d'image. Les bleus nomment celui-ci XeLL (Low Latency), il s'agit donc du pendant de Reflex (Nvidia) et AntiLag (AMD).


La Frame Generation utilise finalement une méthode d'interpolation à l'instar de ses concurrents (avec toutefois quelques spécificités) alors qu'il était question à un moment d'extrapolation... Intel n'a pas jugé utile d'ajouter des unités dédiées à l'analyse du flux optique comme Nvidia peut le faire et préfère utiliser pour cela un algorithme IA s'appuyant sur les unités XMX. Seconde source d'interpolation (ou reprojection comme le nomme les bleus), les vecteurs de mouvement issus du moteur de jeu. Le résultats obtenus via ces deux options sont insérés ensuite dans un second algorithme IA, et c'est lui qui va inférer au mieux l'image à insérer grâce à ces deux composantes. Reste à voir en pratique comment tout cela fonctionnera, sachant qu'une dizaine de jeux devrait l'inclure sous peu (F1 24, AC Shadows, Dying Light 2 pour les plus connus).

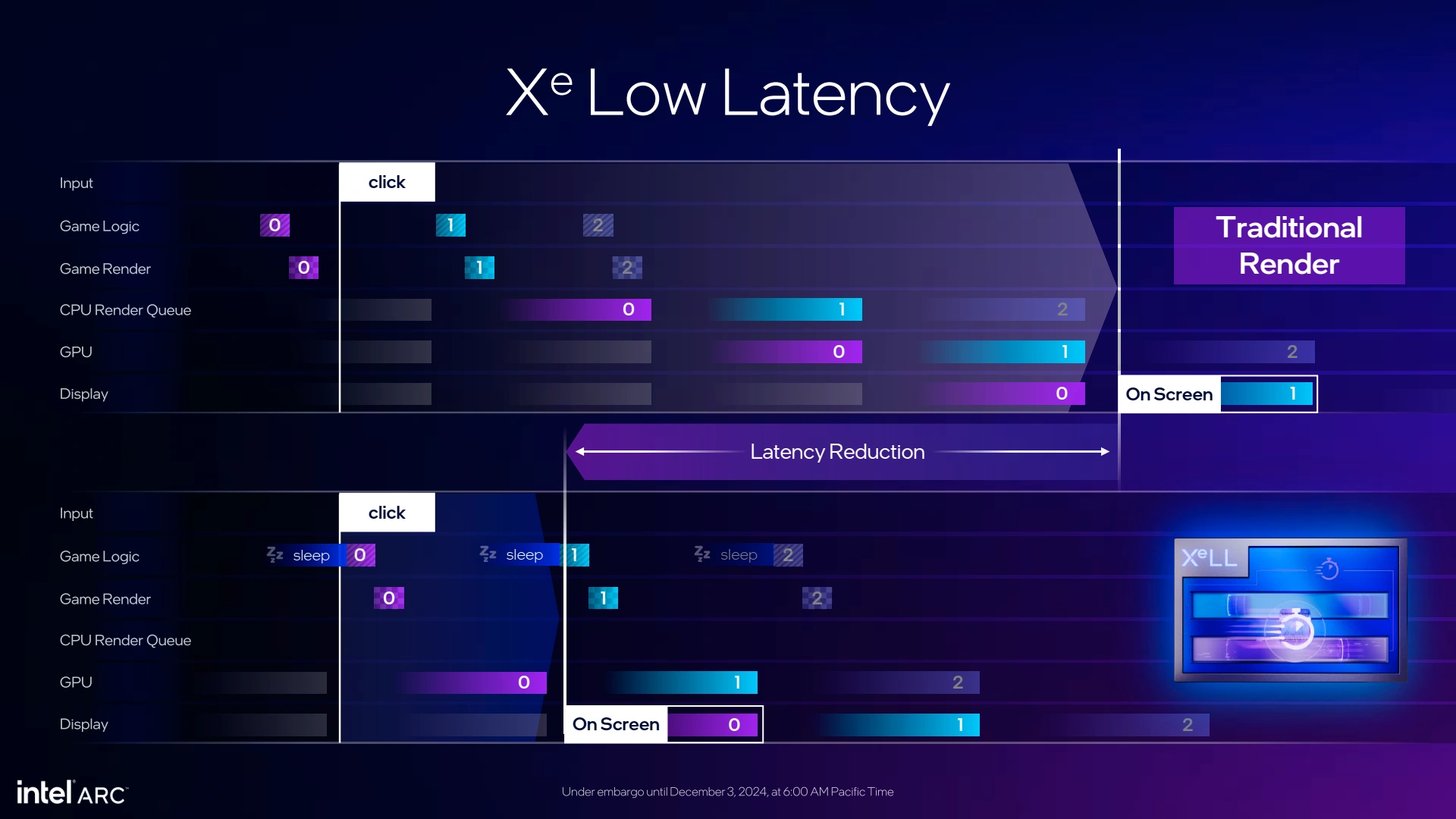
XeLL fonctionne de son côté de manière similaire aux technologies équivalentes des rouges et verts, à savoir via synchronisation des files de rendu d'image côté CPU et GPU. La technologie devra donc être intégrée au jeu pour fonctionner de manière optimale. Intel propose également une option au niveau des pilotes, à voir le résultat pratique tout en rappelant qu'AMD a connu quelques déboires avec un fonctionnement similaire ayant conduit au bannissement de certains joueurs accusés de tricherie. Espérons qu'Intel s'est assuré d'éviter cet écueil.

Les pilotes progressent également avec de nouvelles fonctionnalités au niveau des réglages et des options d'overclocking, dont la possibilité d'appliquer un Offset variable tout au long de la courbe. On regrettera l'absence d'un algorithme permettant de tester la stabilité et faciliter ce travail long et fastidieux, mais Intel n'exclut pas de le proposer à l'avenir.


Quid des cartes ? Deux modèles sont proposés : l'ARC B580 et sa petite soeur la B570. Cette dernière se retrouve amputée de 10 % au niveau des unités de calcul couplée à la désactivation d'un contrôleur mémoire 32-bit (-16,7%). Intel utilise de la GDDR6 à 19 Gb/s sur les deux, mais du fait de la contrainte liée au bus mémoire, la B570 se contentera de 10 Go alors que sa grande soeur disposera de 12 Go. Parmi les autres caractéristiques, on notera des TBP respectifs de 190 W et 150 W permettant l'utilisation d'un seul connecteur d'alimentation externe type PCIe à 8 broches. Pour son interface avec le CPU, BGM-21 se contente de 8 lignes PCIe Gen 4. Précisons que le resizable BAR doit impérativement être activé dans le BIOS sous peine de saccager les performances tout comme pour les ARC Axxx.


Dès le 13 décembre il sera possible d'acquérir une ARC B580, tout du moins en Europe et aux USA, mais la France ne serait à priori pas approvisionnée avant janvier. Il faudra dans tous les cas patienter jusqu'au 16/01 pour se tourner vers une B570. Côté tarif, cette dernière sera proposée à partir de 219 $ HT et sa grande soeur débutera à 249 $ HT. Cela conduirait au cours actuel €/$ à respectivement 250 et 285 € TTC.


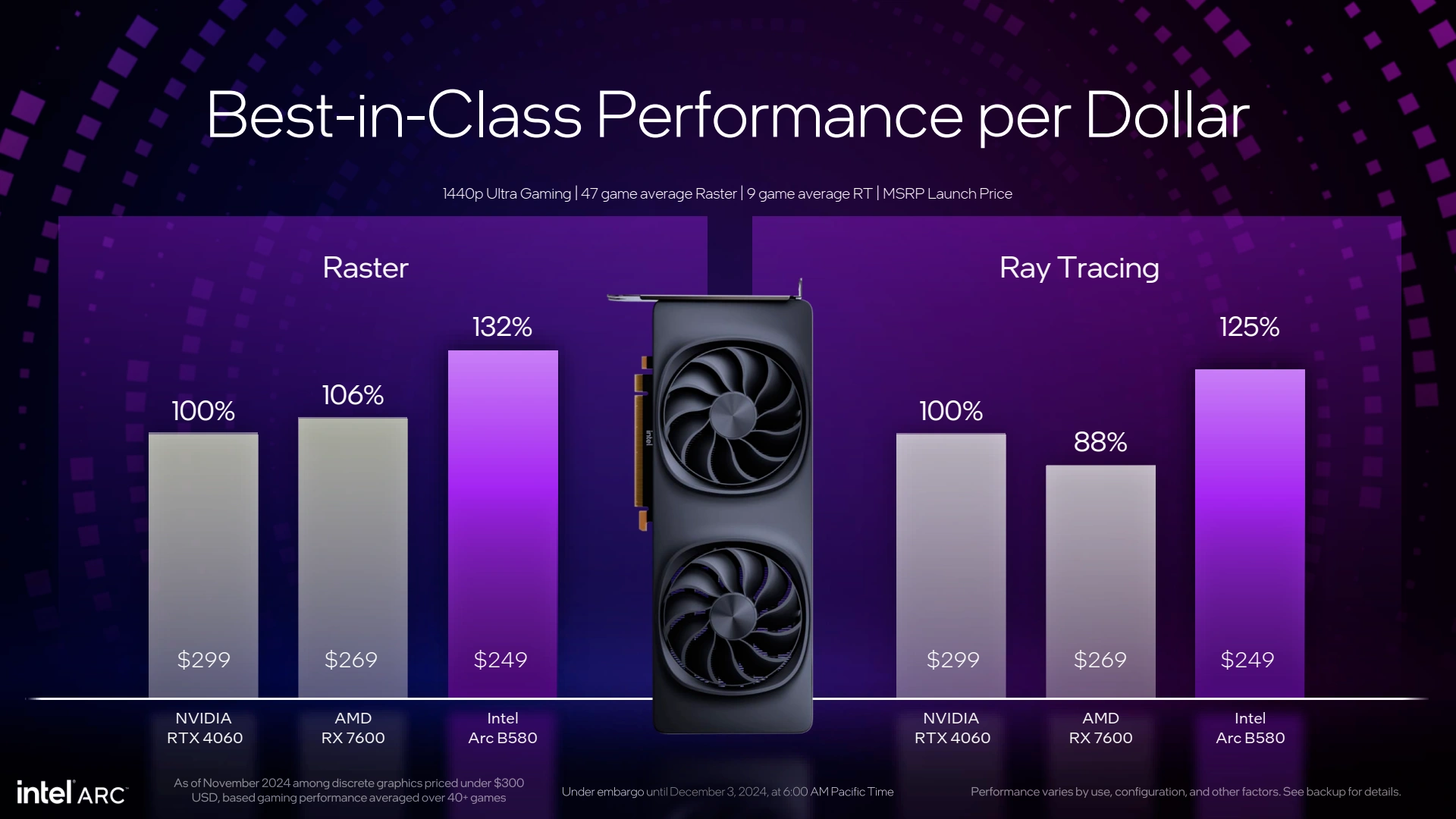
Côté performance, l'ARC B580 devancerait les RTX 4060 et RX 7600, tout ceci méritant bien entendu d'être vérifié par nos propres tests. Cela tombe bien puisque nous avons reçu un exemplaire du modèle Limited Edition ( équivalent Founders Edition ou MBA) de cette ARC B580. Il sera également possible d'acquérir des modèles auprès de partenaires tiers tels qu'Acer, ASRock, Gunnir, Sparkle, etc. A noter que ce sera du reste la seule option pour l'ARC B570, Intel ne proposant pas de LE pour cette référence.

Voilà ce que nous pouvions vous dire rapidement au sujet de ces nouvelles cartes. Nous entrerons davantage dans les détails lors de notre test que vous pourrez consulter avant la commercialisation de l'ARC B580. Si vous désirez en apprendre davantage d'ici là, vous pouvez consulter la présentation complète d'Intel ci-dessous.




Grâce à vous je viens de découvrir un verbe que je ne connaissais pas : sursoir 👍
😉
Je connaissais mais je ne l emploie jamais car j'ai peur de mal le faire 😅
Tour ça va dans le bon sens et c'est normal pour une évolution
Xess enfin a niveau du dlss les drivers pareil côté fonctionnalité
J'ai juste une remarque je me demande si le die est bien en 5 nm ( ironie ) au vu de la consommation 190 watts c'est beaucoup pour une carte entre une 4060 et 460 ti et sur la densité le die est gros pour autant de transistors
Une explication ?
L'explication est simple, Intel utilise probablement un des node N5 ou N5P qui offrent de meilleures fréquences mais qui consomment plus et sont moins denses que le node N4 utilisé par NVidia avec les AD107 et AD106.
Les nodes N5 et N4 font tous deux partie de la famille "5 nm". Dans l'ensemble c'est la même technologie mais avec des assemblages de transistors plus ou moins denses et plus ou moins rapides. C'est ce qu'on appelle des librairies.
De la même façon Zen4 et Zen5 sont en réalité produits avec des process quasi identiques mais l'architecture Zen5 est en "4 nm" parce qu'elle utilise des librairies plus denses.
Il y a des petites impressions dans ce que tu dis
Le n4 de nvidia est commercial il a été prouvé que c'est du n5 en faite et intel n'a pas des fréquences meilleur que les autres ou j'ai mal vu
Zen 5 utilise le n4p qui est du n5 optimisé oui
Mais la on a l'impression qu'avec une gravure normalement proche là densité montre une gravure d'écart d'où mon étonnement
Intel est à 72 millions de transistors par mm² la ou nvidia est à 120 ça fait beaucoup
Des imprécisions, où ça ?
Entre les différentes librairies du 5 nm TSMC + les différences de conceptions des architectures c'est pas anormal d'avoir des différences de densités significatives.
Il suffit de regarder la différence entre Zen4 et Zen4c par exemple, même nombre de transistor pour quasiment 2x la densité sur la partie compute. Et c'est avec les mêmes librairies.
Essentiellement ce que cette différence de densité nous apprend surtout c'est que les BMG-G21 sont probablement plus chers à produire que les AD107 et Navi33.
Edit : pour les fréquences ça dépend aussi de l'architecture, pas que de la finesse et des librairies. Et c'est aussi possible qu'Intel soit resté en N5 pour des raisons de prix auprès de TSMC et pas pour les qualités du process.
Zen 4c attention le nombre de transistors ne double pas ils augmente de 2/3 car core x2 mais l3 réduit et la densité s'explique par des modifications de design pour compacter les core monter moins haut en fréquence et la suppression des lien tsv
Pour intel la seul explication que je vois c'est qu'ils ne sont pas très doué 😅
Ca à l'air pas mal honnêment,* les cores XmX seront là pour gérer le FG/Upscal, pour un 2ème jet, ils possèdent déjà l'équivalent du OFA → OFR,
Pour le tarif, c'est plutôt cool aussi, yaura moyen de faire une belle config avec un RTaptor lake d'occaz (i5/i7) apacher, sur une plateforme LGA 1700.
Hâte de voir les tests!