
Si vous faites partie de nos fidèles lecteurs, il ne vous aura pas échappé que nous avons ajouté au sein de nos derniers dossiers dédiés aux cartes graphiques (hors évaluation des modèles AIB où nous nous consacrons à l'analyse de leurs prestations environnementales), un test d'inférence IA via Stable Diffusion. Pour ceux qui n'auraient pas suivi l'affaire, il s'agissait de mesurer les performances des différentes solutions graphiques lors de la génération automatique d'une image à partir d'une description en langage courant, comme par exemple :
Château entouré d'eau et de montagnes dans un environnement fantastique avec un rendu photoréaliste en 4K ultra
Pour sa mise en œuvre locale sous Windows, nous utilisions le projet Automatic1111 WebUI rassemblant les bibliothèques nécessaires sous une même interface web, et procédions à l'installation et au paramétrage des optimisations spécifiques à chaque architecture. C'est plutôt simple côté NVIDIA, puisqu'il suffit d'entrer le lien URL de la page GitHub associée dans le champ Ad Hoc de WebUI, pour procéder à l'installation automatisée de TensorRT. Il ne reste dès lors plus qu'à compiler ce dernier (à chaque changement d'architecture GPU). Pour AMD et Intel, il faut par contre mettre un peu plus les mains dans le cambouis.
Pour les rouges, nous utilisions un projet DirectML via Microsoft Olive sous une branche différente de WebUI, le constructeur mettant à disposition un petit guide pour ce faire. Toutefois, même en suivant pas à pas la méthode, c'est loin d'être clé en main, et la présence d'un Nicolas sous le coude était bien utile pour peaufiner le tout. Pour Intel, nous utilisions OpenVINO dans yet another fork de WebUI, disponible ici. L'installation se passe plutôt facilement si votre configuration ne s'emmêle pas les pinceaux dans les différentes version de Python . Restait alors à paramétrer l'inférence de l'image : nous options donc pour SD 1.5 (un classique des réseaux de neurones préalablement entraînés) avec les réglages suivants :
- Steps = 50
- Sampler = Euler a
- Taille d'image = 512 x 512
- CFG Scale = 7
- Batch size = 1
- Batch number = 100
Toutefois, pour faire fonctionner tout cela sous le même Windows, c'était la foire aux versions : les cartes vertes et rouges utilisaient WebUI 1.7.0 et Python 3.10.6, la bleue tournait de son côté sous Python 3.11.5 et WebUI 1.6.0. Si cela n'avait pas trop d'effet sur les performances, ce pouvait être davantage le cas côté PyTorch... puisque l'affaire était encore pire à ce niveau : l'ARC utilisait la 2.1.0, les GeForce la 2.0.1 et les Radeon la 1.13. Malgré nos multiples tentatives, il ne nous avait pas été possible d'unifier ces versions, qui soit se réinstallaient automatiquement, soit ne fonctionnaient tout simplement pas avec le fork dédié. Cela dit, le nombre d'itérations par seconde obtenues dans ces conditions correspondaient bien aux attendus des différentes cartes, selon les sources citées précédemment.
Malgré cela, ce n'était pas parfait et nous envisagions de migrer ce test sous Linux pour tâcher d'obtenir quelque chose de plus cohérent. Entre temps, le grand spécialiste des benchmarks qu'est UL (à qui l'on doit le célèbre 3DMark), a décidé de s'attaquer lui aussi au sujet de l'inférence et propose depuis une grosse semaine, un test dédié au sein de sa suite Procyon à destination des professionnels. Nous nous sommes donc penchés sur le sujet afin de voir de quoi il retournait. Stable Diffusion est utilisé via une implémentation spécifique réalisée par UL.

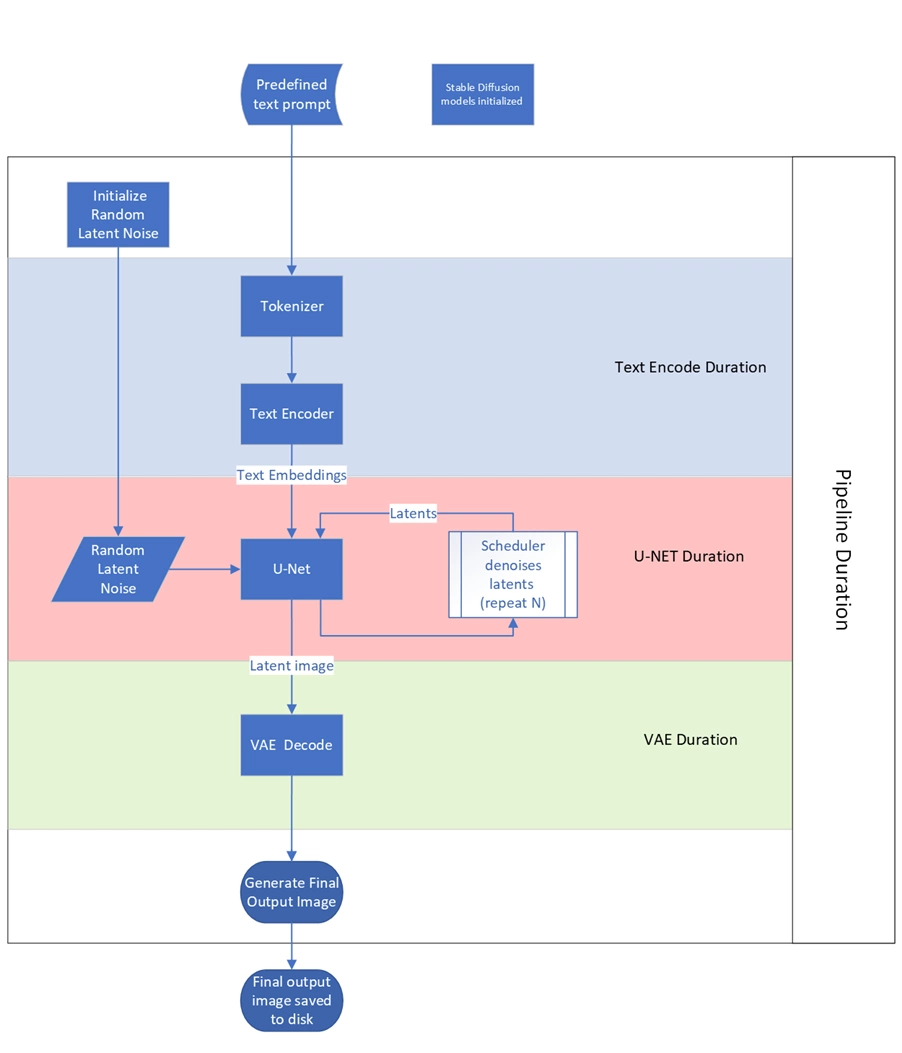 Diagramme de fonctionnement simplifié de Stable Diffusion
Diagramme de fonctionnement simplifié de Stable Diffusion
Les paramètres de tests varient par contre sensiblement de ceux que nous avions retenus pour SD 1.5 via WebUI :
- Steps = 100
- Sampler = DDIM
- 512 x 512
- CFG Scale = ?
- Batch size = 4
- Batch number = 4
On remarquera donc l'usage de lots (batch) traitant 4 images simultanément alors que nous étions restés sur une seule image dans nos réglages. La méthode d'échantillonnage diffère également puisque DDIM est préférée à Euler A et le nombre d'étapes pour cet échantillonnage est doublé à 100. Il est également possible d'opter pour le modèle SD XL afin d'obtenir des images mieux définies, les réglages sont alors les suivants
- Steps 100
- Sampler = DDIM
- 1024 x 1024
- Batch size = 1
- Batch number = 16
UL opte donc ici pour un traitement unitaire des images cette fois, afin d'éviter de saturer la VRAM avec des images 4 fois plus définies. 16 lots sont par contre traités de manière séquentielle, ce qui revient à la génération du même nombre d'images (4 x 4 = 1 x 16). Pour ce qui est des optimisations spécifiques à chaque architecture, UL emploie les mêmes que celles que nous avions retenues, c'est à dire TensorRT pour Nvidia, OpenVINO pour Intel et DirectML pour AMD, les prises de têtes en moins pour les faire fonctionner...



Et les résultats dans tout ça ? Commençons par SD 1.5. A l'instar de ses autres benchmark, UL opte ici pour un score numérique croissant en fonction de la puissance de la carte graphique testée. Le temps d'exécution est toutefois fourni avec une grande précision, de quoi nous permettre d'exprimer également le résultat en images par minute, soit l'unité que nous avions retenue pour nos propres tests. En définitive, la hiérarchie ne change pas, mais les réglages respectifs conduisent à quelques variations dans les valeurs absolues. Les GeForce dominent donc toujours de la tête et des épaules, puisqu'une "simple" RTX 4070 est suffisante pour devancer la plus rapide des Radeon.
Procyon - SD 1.5
Nous avons également réalisé le test en employant le modèle Stable Diffusion XL. La hiérarchie obtenue reste similaire à celle constatée sur le test précédent.
Procyon - SD XL
Ce nouveau test d'UL parait donc totalement pertinent pour évaluer les performances relatives des cartes entre elles lors des opérations d'inférence de Stable Diffusion, si on se fie à nos propres résultats précédents. La mise en œuvre est par contre d'une simplicité enfantine, ce qui n'est pas le cas via Automatic1111 WebUI. Son intégration à la suite Procyon ne le destine pas à un usage particulier mais bien professionnel, comme en atteste la licence annuelle de 5000 $ de ladite suite. Pour un usage presse (licence fournie par UL), c'est par contre un outil très puissant qui permet de simplifier des opérations complexes, tout en conservant une précision remarquable pour son exploitation à titre d'analyse des différents GPU (pour ce test AI).




Wow, sur le font Stable Diffusion est vraiment impressionnant dans sa réalisation, au niveau de la simplicité et de la puissance d'exécution...Content de savoir que la gestion fine du bestiau est simplifié, au niveau de son potentiel quelque chose me dit qu'on a pas fini d'en entendre parler.
Tout d'abord merci pour cette actu, pas forcément sur la présentation de l'outil, mais plutôt sur le fait de vouloir étudier un point pas forcément abordé dans les tests de GPU : les algorithmes spécialisés, notamment ici le machine learning, qui sont tout de même un point important dans le marché de l'informatique aujourd'hui.
Néanmoins, je voudrais faire par de remarques qui me trottent dans la tête depuis que je vois ce paragraphe dans vos tests. Alors je sais bien que vous êtes tous des passionnés avec le temps et les capacités qui en découlent, ce n'est pas un jugement ni l'envie de faire chier, plutôt de quoi (possiblement) aider à améliorer vos analyses sur ce domaine.
Premièrement, sans rentrer dans des détails techniques d'optimisation ou autre, le choix du protocole de base est très... surprenant ! En effet, bien que la majorité des lecteurs sont sous Windows pour le jeu vidéo, une très très grosse partie de la communauté du machine learning utilise plutôt des distributions Linux, avec des drivers et des packages adaptés à ce sujet. Surtout dans la gestion des versions de Python et autre outils, cela est de loin bien plus simple (lancer une ligne de commande d'un script tout fait, facile à automatiser), qui sont mis à jour en priorité sur cette plateforme, notamment sur des distributions comme Ubuntu. Ça demande du temps en amont, mais une fois bien préparé cela permettrait de faire des benchmarks propre avec un environnement correspondant à l'utilisation classique et attendue d'ingénieurs/chercheurs dans ce domaine, le tout assez simplement et sans trop d'effort pour vous.
Ensuite, le choix de fixer uniquement Stable Diffusion me laisse complètement perplexe. Premièrement, c'est loin d'être basé sur des modèles représentatifs de ce que l'ont fait en machine learning, la génération d'image est principalement un système d'autoencodeur ou des technologies proches. Du coup, il ne représente pas la variabilité de ce secteur, et un GPU qui pourrait être habile sur cette tâche pourrait bien ne pas l'être sur une classification ou une régression linéaire. D'autant plus qu'on est sur des tests d'inférence uniquement, si cela se trouve l'entrainement est différent, ce qui peut être important pour de nombreux cas (non, tout le monde n'utilise pas un accélérateur H100 pour l'entrainement 🤣). Du coup ça peut paraître réducteur voire trompeur, alors que l'idée est de bien faire à l'origine, ce que je trouve dommage.
Encore une fois, c'est super de parler de ces choses, d'autant plus que d'autres articles de ce site apporte un œil bien plus critique vis-à-vis du machine learning que d'autres média qui sont en mode "wouah trop cool les IA !". Toutefois, sans avoir besoin d'être une expert, ça serait vachement cool de voir un benchmark tournant sous linux avec les paquets à jour, proposant par exemple un ensemble de tests sur des modèles/catégories de modèles connus et représentatifs de l'écosystème (ResNet, VGG, ConvNet, MobileNet, Autoencoder, LLM... la liste est longue, il faut faire des choix aussi :p )
Nos tests n'ont pas l'ambition ni vocation à être exhaustifs, c'est tout simplement impossible lorsque l'on a une activité en parallèle, toi mieux que quiconque devrait le savoir. C'est d'autant plus vrai lorsque lesdits tests sont soumis à un NDA et donc imposent un temps réduit pour la réalisation de l'ensemble des mesures et la rédaction/mise en page/graphique de tout cela.
Ensuite, si tu as bien lu la news et les tests explicitant le protocole, il ne t'aura pas échappé que l'on souhaitait basculer vers une solution Linux à l'avenir comme tu le proposes et ce bien avant que tu n'en parles. Seulement cette intégration de Procyon rebat les cartes. Que Stable Diffusion ne représente pas l'Alpha et l'Omega des tests d'IA, je crois que personne et surtout pas moi n'a émis une telle assertion.
Mais comme toujours, il faut bien faire des choix dans la vie et cette solution était la plus "simple" et pertinente (selon moi) à mettre en œuvre au moment où les dossiers arrivaient et l'inférence (puisque c'est bien cette partie qui est évaluée ici) est la plus susceptible d'être utilisée par un acquéreur particulier de telles cartes (qui représente la majorité de notre lectorat). Puisque ce test est également repris par UL (avec ses propres ajustements) spécialisé dans les benchmarks, j'imagine qu'il n'est pas si mauvais en soi, même s'il ne représente qu'une portion de ce que comprend le traitement de l'IA.
Maintenant, notre protocole est toujours en perpétuelle évolution et je travaille sur d'autres usages possibles des capacités d'accélération GPU et qui intégreront probablement des tests à l'avenir. Nos mesures de SD pré-Procyon ont eu le mérite de nous confirmer aussi pourquoi Nvidia domine outrageusement le marché, vu la différence de facilité à mettre en œuvre la chose sur GeForce en comparaison des concurrentes (sans parler de performance).
Je rajoute que le budget de temps de test est en lui-même limité, et ça ne permet pas de tester l'alpha et l'oméga de toutes les utilisations d'un GPU. Certes, Windows n'est pas la plateforme canonique de ML (à la manière de Linux pour les jeux typiquement !) ; il n'empêche que le ML est de plus en plus présent dans les logiciels (PureRAW, nous en parlions ici), mais Photoshop également, Copilot, etc... Il y a donc bien un besoin de ML sous Windows, et si Intel / AMD veut rester compétitif, il faudra bien bosser à un moment sur un runtime dédié Windows digne de ce nom.
En tant que site de hardware grand public, il est du coup bien pratique d'avoir un benchmark synthétique pour tester cela.... mais c'est à prendre comme une fraise sur le gâteau Windows, et non un test détaillé des performances en ML de cartes (même si ce serait fort intéressant dans un dossier dédié !).
Ah je comprends tout à fait, je ne tiens pas à faire une quelconque morale ou critique de fond, plus que ça serait vraiment intéressant de voir un vrai dossier complet sur ce sujet, d'autant plus dans la presse française. Loin de moi de vouloir remettre en question la dominance des verts, j'utilise en ce moment tous les jours leur matos, et faut avouer que ça fonctionne nickel.
C'est plutôt une crainte que s'installe dans les esprits que ça sera le cas pour très longtemps, hors dans mon cadre de travail on voit que ça tend à bouger de tous les côté, surtout avec le rachat et l'intégration de Xilinx. C'est plus la curiosité qui m'attire vers un tel test qu'un possible parti pris de ma part. Parce que je sais que lors de mon prochain changement de GPU, ça sera quelque chose que je devrais prendre en compte, et vu le pris du matériel, avoir une idée propre et concise serait plutôt cool 😁
La question n'est pas de remettre en cause ou non la dominance de telle ou telle marque, mais de l'intégration de tests complémentaires au sein de dossiers déjà extrêmement chronophages et ce sans mettre en péril la fiabilité des résultats. Je m'explique : à l'origine, ces dossiers étaient exclusivement dédiés aux performances ludiques des GPU. Même si ce n'est qu'une hypothèse de ma part, je dirais que l'immense majorité des lecteurs reste intéressée uniquement par ce domaine.
Toutefois, des commentaires récurrents nous sollicitaient pour ajouter des tests additionnels au niveau du rendu 3D, de l'encodage et maintenant de l'IA pour avoir un vue plus large. C'est ce qui a été fait, mais il ne faut pas se leurrer, ce n'est pas avec un test de chaque type de tâche que l'on a un vue exhaustive (ce n'est pas pour rien que l'on inclut 20 jeux depuis belle lurette). Pour le choix des logiciels retenus, ça a été un mix de leur popularité, facilité à mettre en œuvre (pour ne pas alourdir une charge temporelle déjà énorme) et disponibilité de licence (Resolve).
Ces tests additionnels au sein des dossiers GPU ne sont donc ici qu'un "bonus" (tout comme les benchmarks) qui représente le niveau de performance des différentes solutions graphiques avec ces derniers uniquement. A contrario, notre indice ludique se base lui, sur une moyenne pondérée des 20 jeux et s'avère pertinent pour représenter le comportement "moyen" des cartes graphiques en jeu (sans être exhaustif pour autant). Il ne nous viendrait pas à l'idée de juger les performances ludiques des cartes avec un seul jeu, il en est donc de même pour les autres tâches.
Donc oui, il est possible qu'à l'avenir on étudie un dossier axé cette fois sur les tâches "productives" des cartes graphiques, selon le temps à disposition et notre capacité à le mettre en œuvre.
Même si ça tend à bouger, je pense (= mon opinion, pas une vérité absolue) que l'avance de Nvidia dans le domaine est loin de se résumer à une simple question de Hardware, et qu'il suffirait d'une acquisition pour renverser la situation. Leur point fort à mon avis, c'est d'avoir de nombreux modèles IA déjà entraînés depuis des années et de proposer des solutions clefs en mains tel que les NIMs, qui permettent aux acquéreurs de leurs GPU d'avoir accès aux modèles, runtime et moteurs d'inférence optimisés pour leurs modèles. Pour le monde pro c'est un avantage substantiel et il faudra du temps pour que la concurrence propose l'équivalent à ce niveau. Ce n'est que mon avis pour l'heure, wait & see comme aiment à dire les anglo-saxons.
Curiosité : est-ce qu'on connait les raisons de ces solutions qui donnent des écarts énormes entre AMD et NVIDIA ? Est-ce que cela vient de l'archi matérielle de base (genre des pipelines matériels dédiés à ce type de traitement en plus chez nvidia ou mieux organisé) ou d'un choix logiciel (donc de procyon) d'optimiser pour une architecture matérielle précise ou juste de la puissance financière et de développement de Nvidia qui (comme semble indiqué par Eric en début d'article) peut packager et optimiser ses propres solutions adaptées à ses cartes ?
Si on va sur un truc plus bas niveau, genre un script d'IA codé en fortran sur une classification moins "pipeliné" qu'une IA générative (ou plutôt système synthétique de plagiarisme automatisé), ces différences d'efficacité subsistent-elles ?
J'aurais tendance à dire que pour Stable Diffusion, c'est un mélange d'archi matérielle plus efficace (en tout cas si on compare GeForce et Radeon comme ici, ce serait peut-être différent avec les cartes rouges employant non pas RDNA mais CDNA) et de capacité d'optimisation software des verts. UL indique avoir utilisé les moteurs d'inférence spécifiques à chaque architecture comme nous avions pu le faire pour WebUI.
merci pour ta réponse rapide et éclairée 👍
Pour bosser un peu dans les architecture matérielles, je confirme ce que dit Riton. CUDA sous Windows, ça fait un moment que ça tourne et le pipeline est rodé, autant pour l'utilisation que pour son intégration dans des softwares. Pour AMD et Intel, il y a moins d'intérêt à cela et moins d'expertise dans ce domaine précis... À l'inverse, sous Linux (qui serait probablement la manière la plus cannonique de faire un benchmark comme tu le proposes), les trois sont à peu près à égalité (en programmation applicative, je ne parle pas de la partie display).
Le soucis de parler de fortran, c'est d'imaginer qu'un langage unique va produire un code "équivalent" sur tous les GPU ; or c'est loin d'être le cas. Certaines passes d'optimisation (comme Microsoft Olive) vont modifier des précisions et "tuner" le réseau. Même au niveau du compilo GPU, il y a des paramètres au runtime qui peuvent influer énormément les performances pour un même code (nombre de warp et size si je me souviens bien). C'est comme essayer de comparer un Intel AVX512 avec un Threadripper sans AVX512 mais le double des cœurs : le même code ne va même pas tourner sur une des deux machines, et l'approche "microbenchmarking" ne donnera pas un résultat interprétable pour l'utilisateur. Par exemple, les cartes AMD à l'époque des GTX 1080 étaient plus puissantes en FLOPS (très probablement en microbenchmark donc) sans pour autant pouvoir transformer cela en jeu. On peut aussi citer, plus récemment, la bataille de zizi sur les les performances de la MI300X vs la H100, ou personne n'est d'accord sur les optimisations à appliquer pour avoir les "bonnes" performances.
Rajoute enfin que les réseaux de neurones deviennent de plus en plus complexes et différents, et donc qu'un microbenchmark fortran comme un test SD "tout seul", cela revient à tester un GPU sur un jeu : il faut le prendre avec beaucoup de recul ;).