
Alors qu’AMD avait convié une partie de la presse mondiale (dont H&Co) pour son Tech Day 2024, nous étions restés pour le moins sur notre faim concernant la nouvelle microarchitecture Zen 5, finalement pas vraiment développée. Mais ce n’était que reculer pour mieux sauter, puisqu’AMD a organisé il y a quelques jours une vidéoconférence dédiée cette fois à cette dernière, avec de la technique à tout va. Cela vous plaît ? Nous aussi, alors commençons directement dans le vif du sujet avec les objectifs qui auraient présidés aux choix architecturaux du concepteur texan !


Comme à l’accoutumée, l’idée est (évidemment) de faire mieux que la génération précédente, sans pour autant déséquilibrer le cœur : dans un intérêt économique (et de consommation énergétique), il est inutile de booster aux hormones un seul "endroit" du CPU, sous peine de le voir freiné par les autres éléments ! Dans cette mouture Zen 5, l’accent a ainsi été mis sur la performance single et dual-thread (le cœur du cœur !), construisant par-dessus les améliorations des caches de Zen 4. L’hétérogène sauce AMD est toujours de mise, avec une version Zen 5 moulinant à pleine vitesse et une version Zen 5c plus dense (dans les 25 % plus petit, au doigt mouillé et en fermant un œil) et plus économe énergétiquement via une bibliothèque optimisée haute densité utilisée lors du passage de l’architecture logique aux transistors physiques via lithographie. Petite nouveauté cette fois-ci, les unités de calculs vectorielles sont configurables pour opérer soit en mode 256-bit (le précédent double pumping), soit 512-bit selon son intégration dans divers produits, limitant de fait la performance de l’AVX-512 dans le premier cas. Un choix qui se justifie sur mobile notamment, où l’importance de ces instructions vectorielles est bien moindre, tout en laissant la possibilité à la firme de réutiliser le même cœur sur serveur sans restriction. Par ailleurs, tant qu’à causer des modifications de Zen 5 pour la haute performance, le bousin est disponible à la fois dans une version 4 nm et 3 nm, afin de pouvoir s’adapter à vraiment toutes les gammes de puces d’AMD.
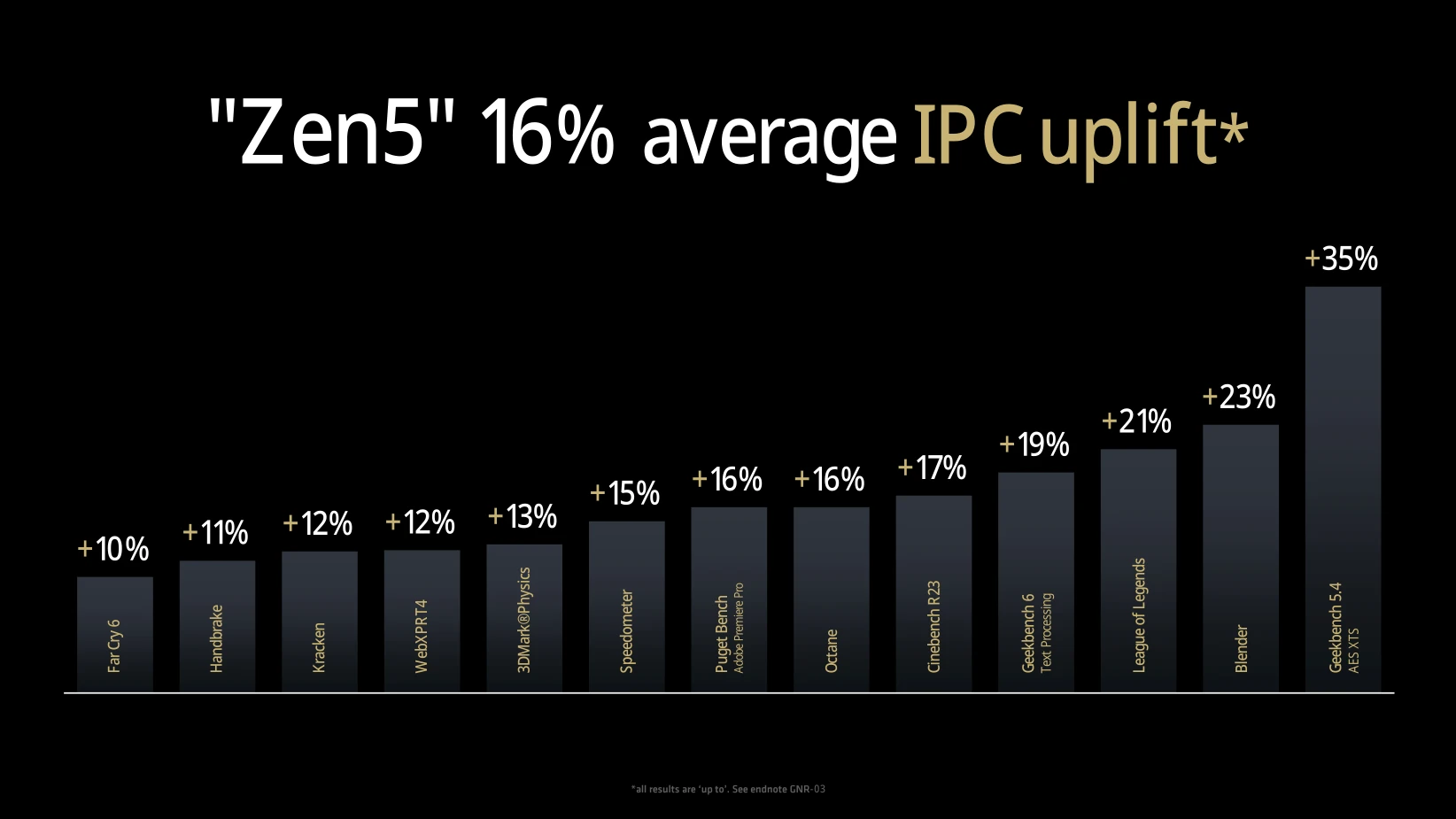
Avec ces idées de designs en tête, les rouges annoncent fièrement un gain moyen d’IPC de 16 % en comparant un Ryzen 9 9950X à un Ryzen 7 7700X à 4 GHz (devinez comment l’indice a été calculé sur les tâches multicores…). Comment cela est-il possible ? Voyons le détail ensemble !

Un Front-End toujours plus agressif
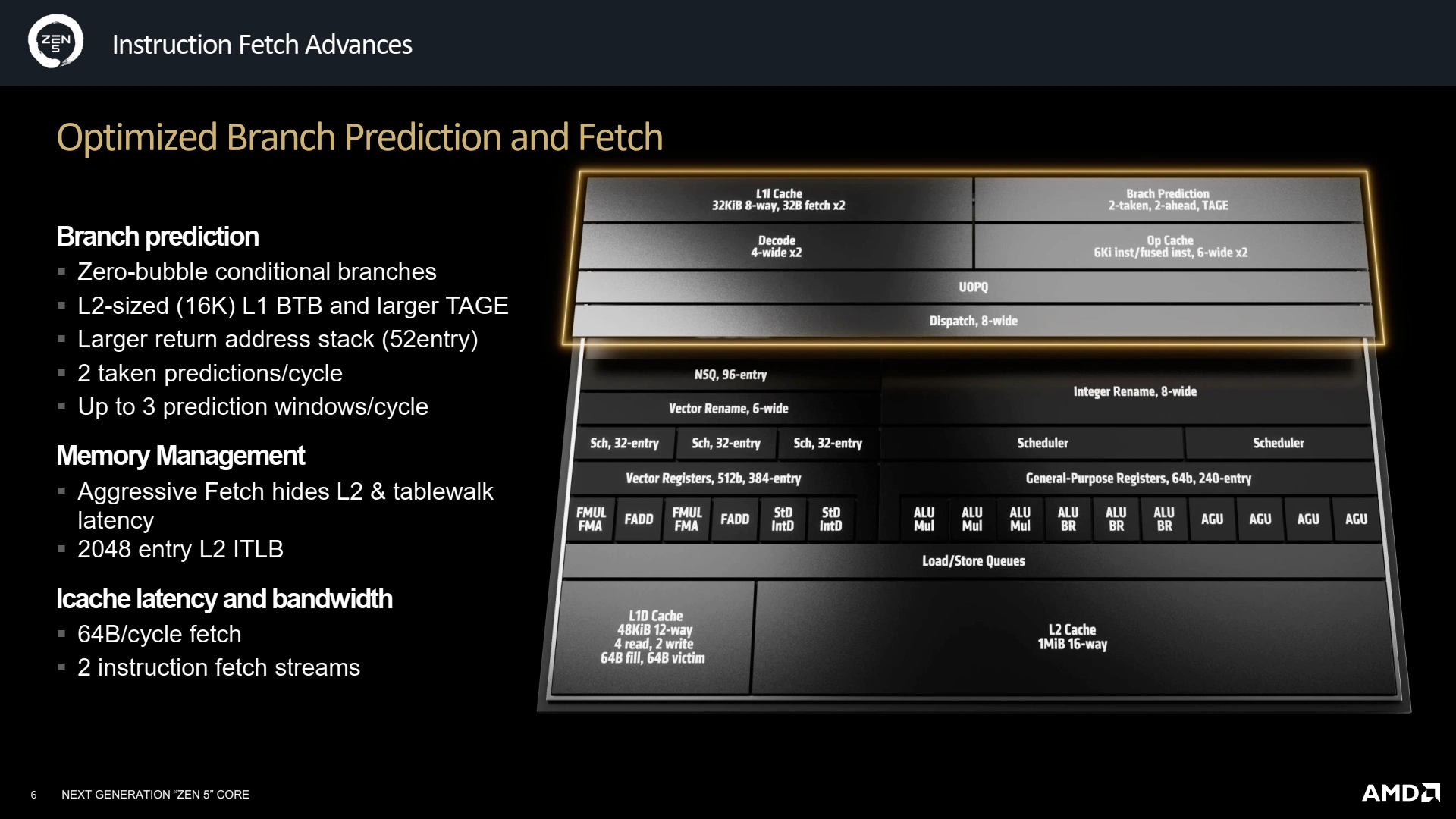
Le décodage est la toute première étape que le code subit : une digestion du programme brut situé en mémoire, le transformant en une liste d'instructions compréhensibles atomiquement par le CPU. Similairement à ce que le concurrent Intel propose depuis quelques générations sur sa microarchitecture efficiente, AMD a opté pour un double pipeline de décodage, ce qui permet de travailler sur deux flux indépendants d’instructions, bien pratique dès lors que le CPU est intriqué dans de multiples branchements conditionnels spéculatifs… ainsi que pour le SMT ! Les divers buffers accueillant les instructions décodées sont également mis à niveau, avec un OpCache recevant les instructions décodées 33 % plus grand, et opérant désormais sur des instructions au lieu des plus petites micro-instructions (implémentation de Zen 4) afin de gagner en densité. Le tout permet ainsi d’atteindre un faramineux 12 instructions décodées par cycle au maximum : ça décoiffe !


L'autre pendant du Front-End est la prédiction de branchement, qui permet d'éviter d'attendre certains résultats intermédiaires avant de commencer à décoder (puis exécuter) la suite du programme ; une opération cruciale pour les performances puisque c’est elle qui extrait un nombre d’instructions suffisant pour peupler le ReOrder Buffer et, ainsi, nourrir toutes les unités de traitement. Depuis le TAGE de chez André Seznec (cocorico), l’essence du prédicteur n’a pas beaucoup changé, et Zen 5 doit faire comme tout le monde : un plus gros cache L1 d’historique des branchements (BTB), qui passe à 16K entrées, une taille de L2 ! Le L2 est quant à lui plus modeste avec 8K entrées, il fallait bien économiser de la place quelque part. Enfin, la pile des retours d’adresses croît de 20 entrées pour culminer à 52, toujours dans une optique de meilleure prédiction des sauts. Enfin, la prédiction de branchement conditionnel se fait désormais sans latence supplémentaire, cependant la latence en cas de missprediction est en légère augmentation, sans que nous ayons de valeur exacte.

Un Back-End gonflé à l’AVX-512
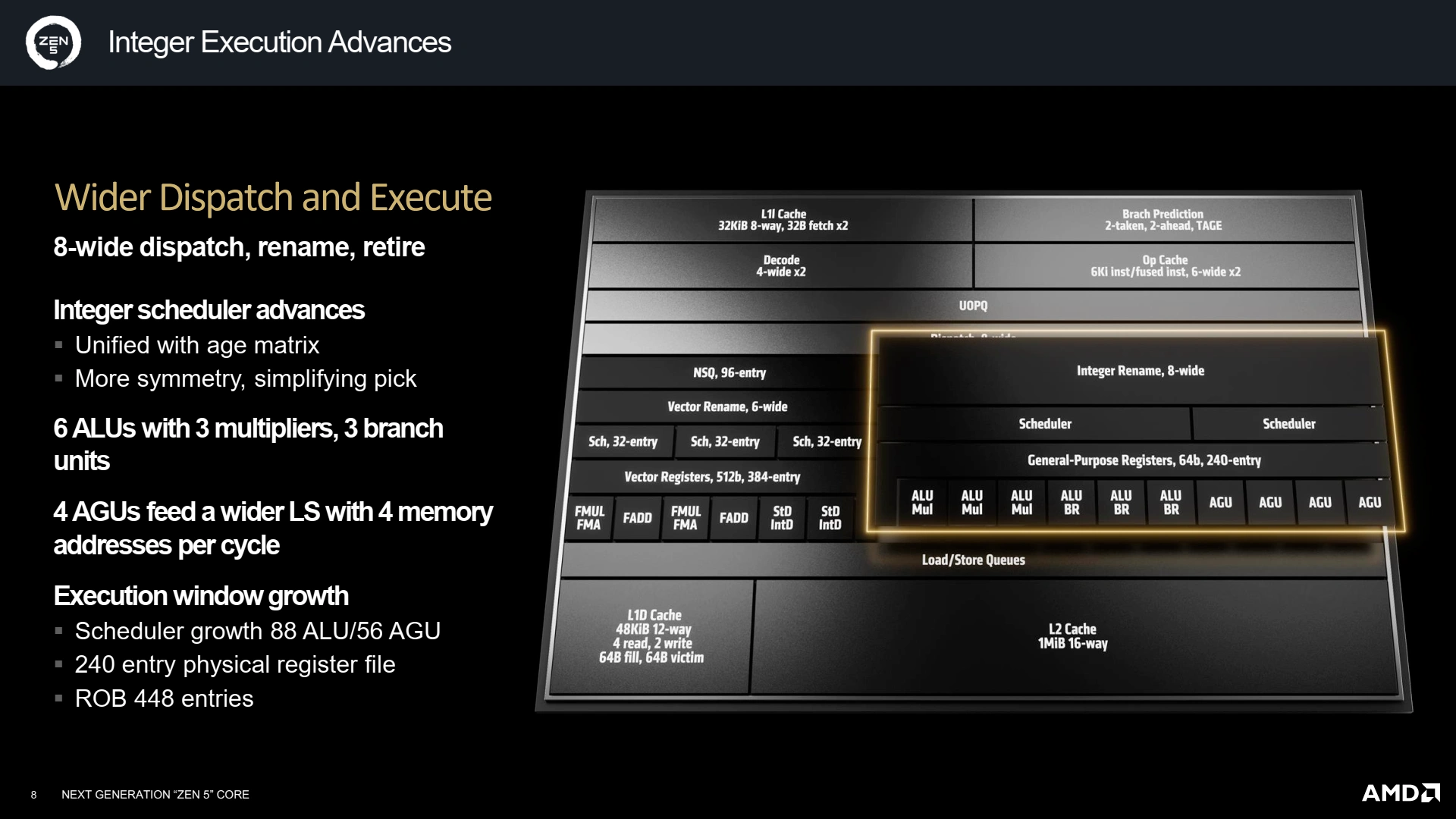
Si le Front-End grossit, c'est bien pour que le Back-end réussisse à extirper toujours plus de parallélisme des micro-ops décodées et/ou prédites. Mais, pour cela, il faut un nombre plus grand d’unités de calcul/branchement, et un ROB plus gros histoire de retenir suffisamment de micro-ops et extraire ainsi un maximum de parallélisme. Cela tombe bien, ce dernier est passé de 320 entrées à 448 sur Zen 5 ! Mécaniquement, les divers autres mémoires grandissent tel le nombre de registres vectoriels (384 entrées) et entiers (240).
La structure générale du pipeline n’évolue pas avec une partie gérant l’arithmétique entière et les branchements, secondée par un coprocesseur gérant les instructions flottantes et leurs chargements/rangements. Commençons par la gestion des entiers : AMD a unifié son scheduler, ce qui permet de simplifier son implémentation avec une matrice d’âge unique et moins de risques de stalls. Au niveau des unités, deux ALU/Branchement font leur apparition (une dérivant d’une unité de branchement seule), ainsi qu’une AGU, portant la largeur du pipeline à 10 ports de 3 types différents.

Du côté du pipeline flottant, la largeur ne change pas (6 ports), mais sa composition évolue avec l’intégration d’unités AVX-512 complètes (configurables en 256-bit selon la référence précise du CPU) — la plus grosse avancée —, et la symétrisation des unités de rangement, qui peuvent désormais toutes deux effectuer des écritures dans la mémoire et dans les registres entiers en cas de besoin. Tout ce beau monde est contrôlé par trois schedulers, un par couple FMUL-FMA/FADD et un pour les deux unités de chargement-rangement. Justement, ces unités évoluent avec la possibilité d’effectuer 2 chargements 512-bit par cycle et un rangement 512-bit ; tout comme le FADD (fast-add) qui peut s’effectuer en 2 cycles dans certains scénarii, au lieu des 3 cycles de Zen 4.


Et pour le cache ?
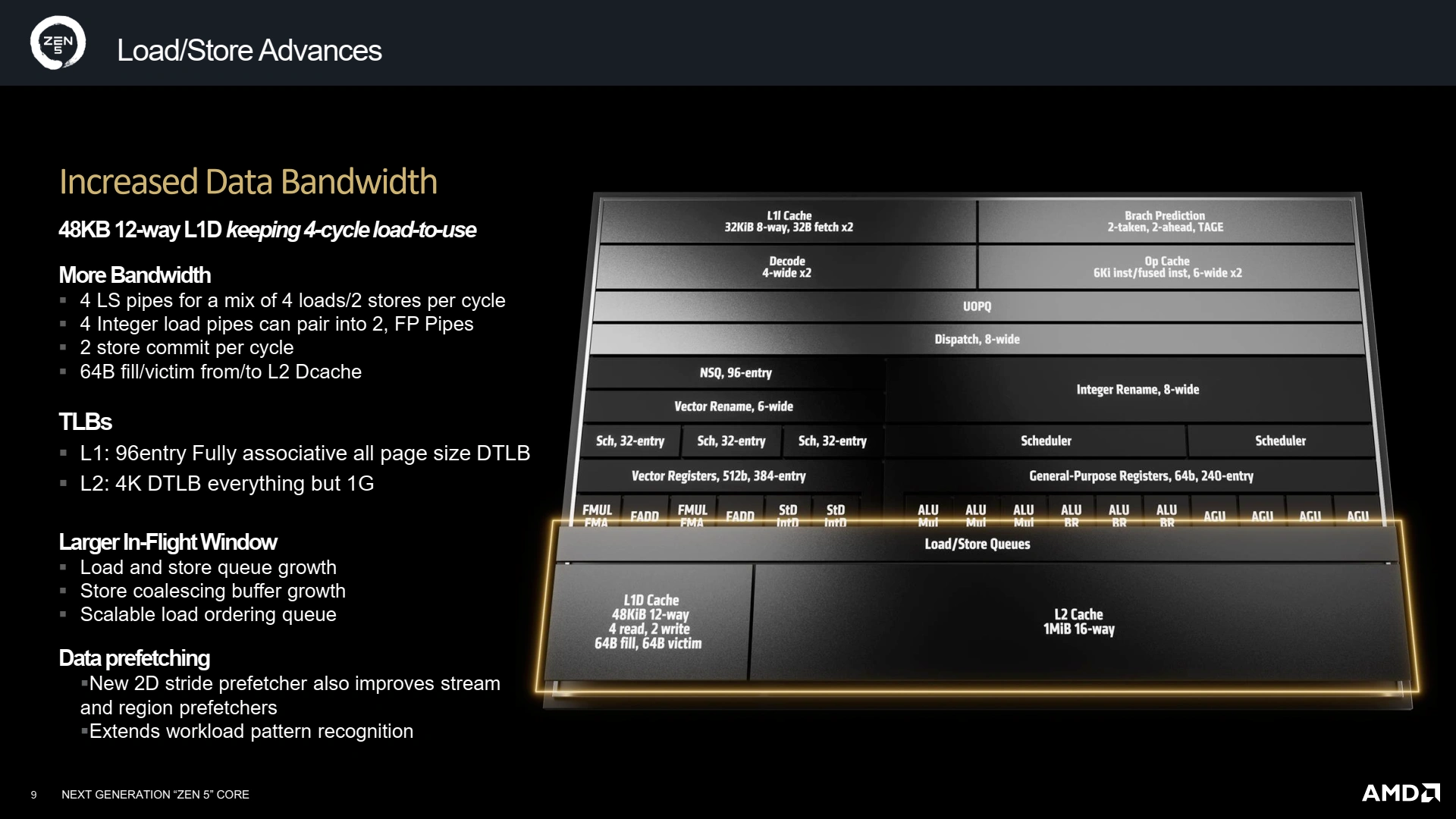
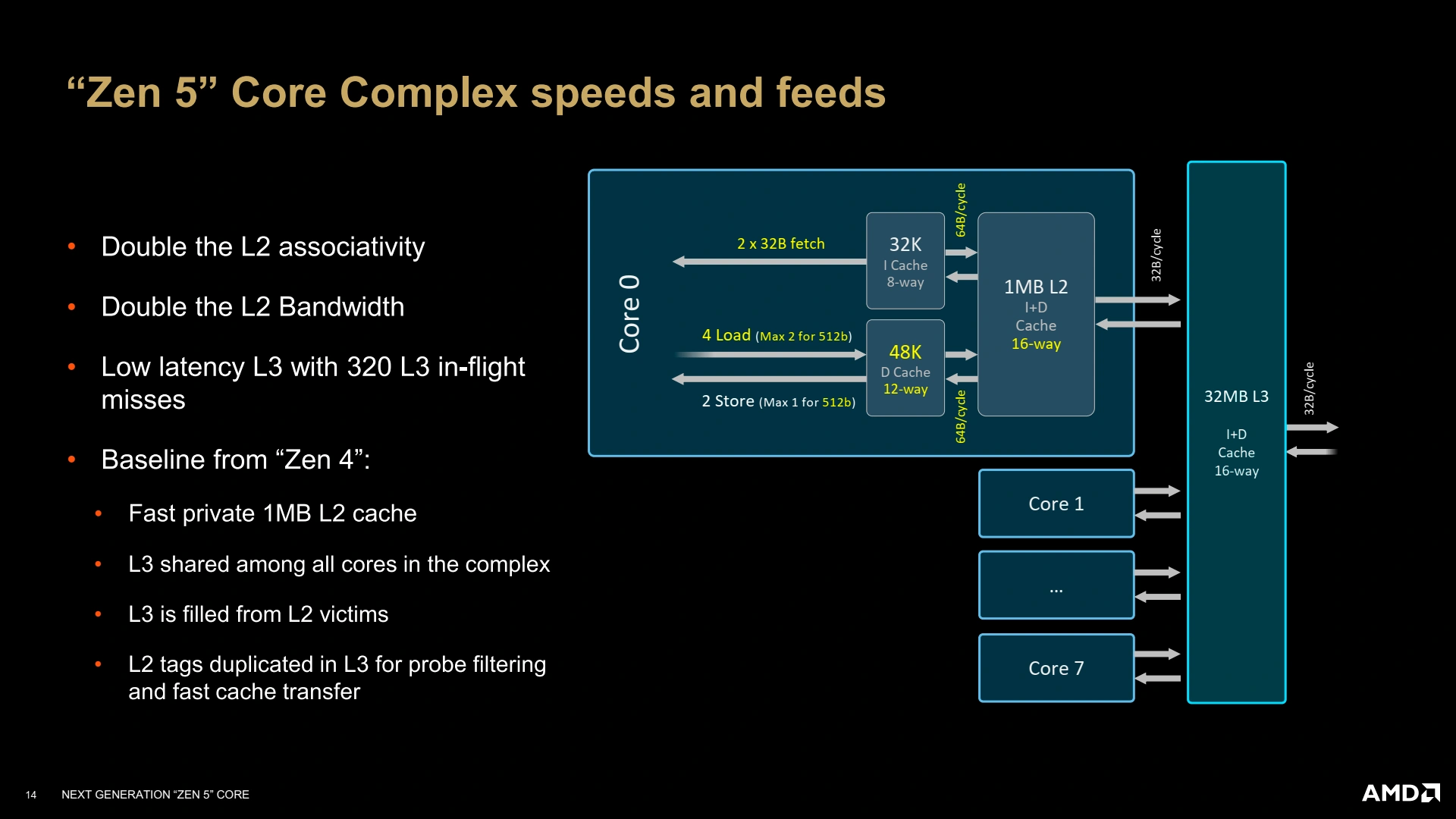
Avoir de la puissance de calcul, c’est bien, mais il faut également que le sous-système mémoire suive. Ainsi, le L1D passe à 48 Kio partitionné en 12 voies… tout en gardant une latence de 4 cycles, bien joué ! Le L2 reste à 1 Mio par cœur, et le L3 pourra être configuré de 8 à 32 Mio selon le besoin (mobile, desktop, serveur). En revanche, les TLB évoluent afin d’offrir toujours plus de performances avec 96 entrées dans le L1 data, et un L2 data de 4K entrées qui contient tous les types de pages sauf celles de 1 Gio — il faut dire que supporter 4096 Gio de mémoire mappée en hugepages n’est pas du plus commun ! Quant aux instructions, leur TLB n’est pas en reste avec un L2 de 2048 entrées, et une bande passante du L1-I capable de satisfaire le double décodeur — tout comme le L1-D se doit d’être capable de supporter les chargements - rangements AVX-512 ! Enfin, le L2 voit également sa bande passante doubler avec le L1D et le L1I, toujours dans cette logique d’équilibrage du design global.

Quid de Interfaçage avec l’OS ?
Côté hétérogène, AMD vend une solution plus simple qu’Intel avec des cœurs de même IPC — puisque de même microarchitecture — ce qui simplifie les décisions de l’ordonnanceur de l’OS. Néanmoins, la firme a développé un système permettant de transmettre des informations entre le CPU et le système hôte concernant la charge des cœurs et le type du travail en cours, similaire dans l’esprit à l’Intel Thread Director, sans pour autant reprendre toute sa complexité. AMD souhaite ici rajouter que le système est encore en cours de développement, et pourra faire l’objet de futures communications et extensions ! Dans tous les cas, puisque les cœurs Zen 5c sont les plus efficients, AMD considère que, de manière générale, ces derniers sont à privilégier ; mais le fin mot revient à Windows/Linux pour l’association processus/cœurs, histoire que la réactivité puisse être au rendez-vous en cas de besoin.


Citons également les quelques mises à jour du jeu d’instructions, avec le support toujours plus étendu de l’AVX-512 et le rajout d’instruction de streaming permettant de stocker des valeurs sans toucher aux caches, lorsque le programmeur est sûr que la donnée ne sera pas utilisée, ainsi que divers utilitaires afin d’isoler les compteurs hardware (des mécanismes chargés de collecter des statistiques sur l’état du CPU pendant les tâches exécutées) dans le cas d’utilisation de machines virtuelles.




Un petit récapitulatif du bousin !
Et dans un vrai die ?
L’architecture sur papier, c’est bien, mais dans une vraie puce, c’est encore mieux ! Zen 5 va rouler sa bosse dans des Core Complex (CCX), comme tous les cœurs rouges depuis Zen, et là, l’organisation ne change pas avec une bande passante de 32 octets/cycles avec le L3 (type victime), partagé par tous les cœurs du cluster. Le L3 est également toujours interfacé avec bande passante de 32 octets en lecture/16 octets en écriture (pour des raisons de rétrocompatibilité et d’intégration sur les design en chiplets)… de quoi justifier la castration possible des unités vectorielles AVX-512, vu que le sous-système mémoire est trop faible pour suivre une chargement complet AVX-512 (64 octets !) depuis le L3 ou la RAM par cycle !

Pour le moment, Zen 5 est annoncé dans deux familles de produits : Granite Ridge (les Ryzen 9000 desktop) et Strix Point (les Ryzen AI 300 mobiles). Le premier reprend une structure homogène classique dont un CIOD inchangé par rapport à la génération précédente, et dote ses CCX de 32 Mio de L3, alors que les CPU pour laptops se voient moins bien dotés — il faut bien limiter la chauffe et le coût de production d'un die monolithique — avec un CCX de 4 cœurs Zen 5 à 16 Mio de L3, et un CCX efficient de 8 cœurs Zen 5c à 8 Mio de L3. Notez que Strix Point n’intègre physiquement que la version 256-bit des unités vectorielles (que ce soit Zen 5 et Zen 5c), pour Granite Ridge, le mystère reste entier !

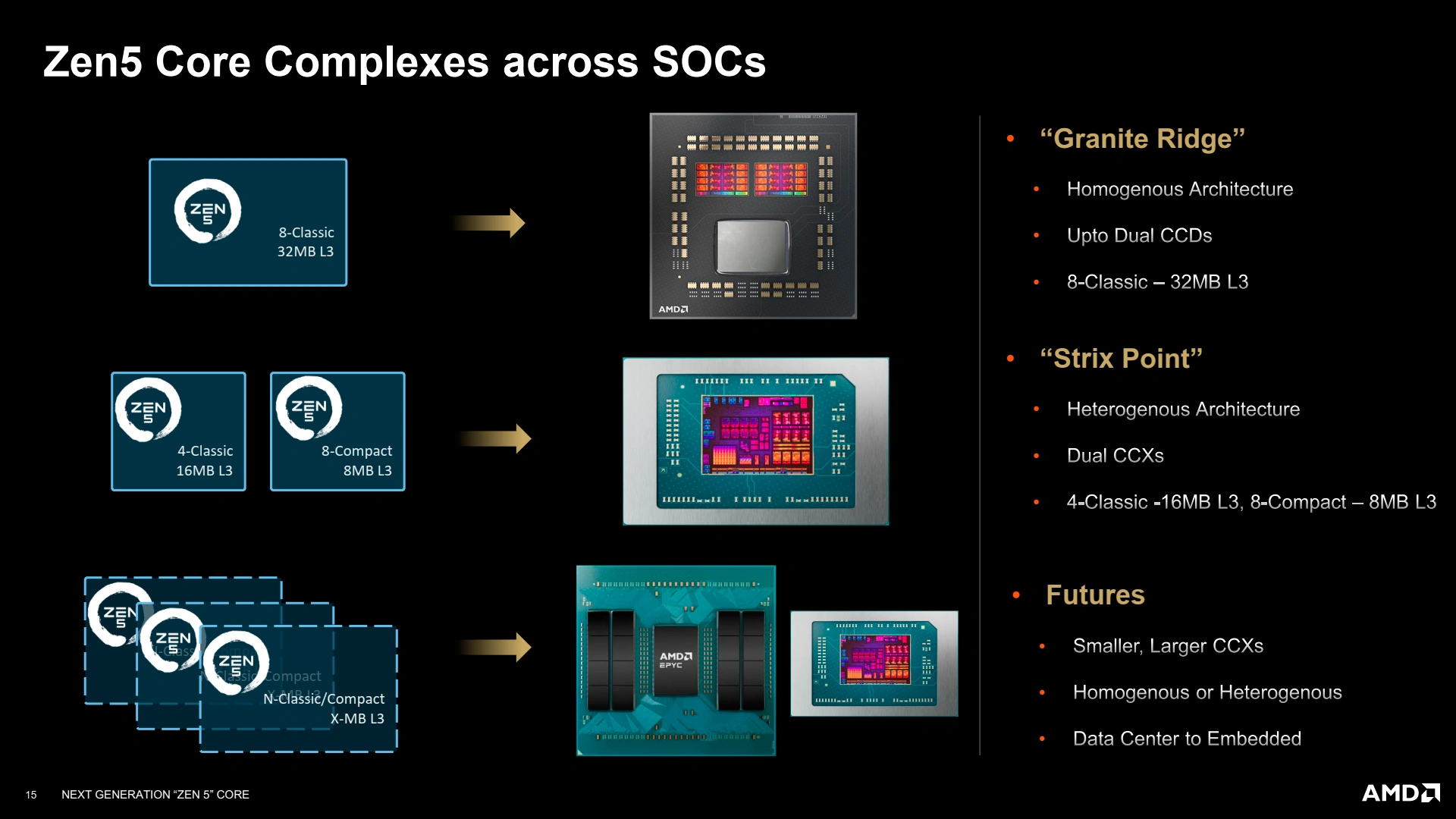
Dans le détail, voilà la structure des deux SoC (ne pas hésiter à passer en plein écran pour tout voir !), comprenant l’interfaçage de l’iGPU et les divers IO. Notez le rétropédalage à 16 lignes PCIe 4.0 sur Strix Point, contre 20 sur Hawk Point, jugé suffisant vu la cible du produit.


Ici, le datapath correspond au nombre de connexion avec les contrôleurs mémoires via l'Infinity Fabric
Hors-sujet #1 : RDNA 3.5
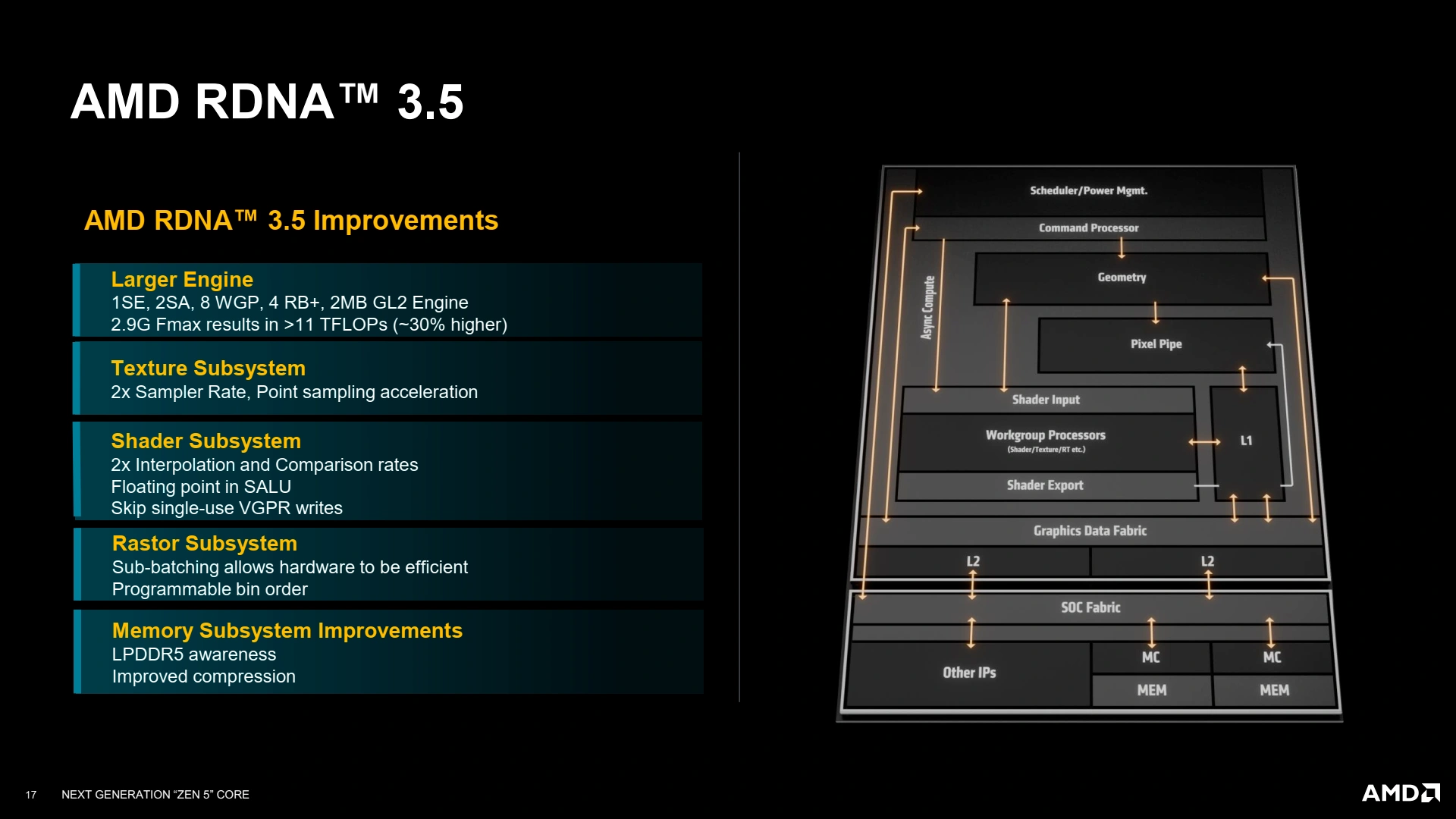
Strix Point, la sauce mobile de Zen 5, intégrera une mise à jour de l’iGPU des rouges en la présence de RDNA 3.5. Loin d’être une nouvelle génération architecturale, la majorité de ses gains provient de la multiplication des unités de calcul avec le passage de 12 CUs maximum sur Hawk Point à 16 CU sur Strix grâce aux progrès en matière de lithographie. Néanmoins, quelques petites améliorations (avant tout dans un but d'amélioration de l'efficacité énergétique) se sont pointées ici et là sur le pipeline de rendu afin d’optimiser l’utilisation du GPU sous forte charge, notamment la possibilité de programmer l’ordre des bins manuellement dans le sous-système de rastérisation permettant de favoriser la localité temporelle du programme. De même, le système de gestion des textures évolue (débit doublé), et celui des shaders est retouché pour être plus efficace sur les tâches d’interpolation et comparaison, éviter les écritures mémoires inutiles (si la donnée n’a qu’un seul consommateur) et le rajout des opérations flottantes sur l’ALU non vectorielle (la Scalar ALU). La plupart de ces améliorations visent donc à limiter autant que possible les accès à la mémoire, qui sont de gros consommateurs d'énergie.

Hors-sujet #2 : XDNA 2
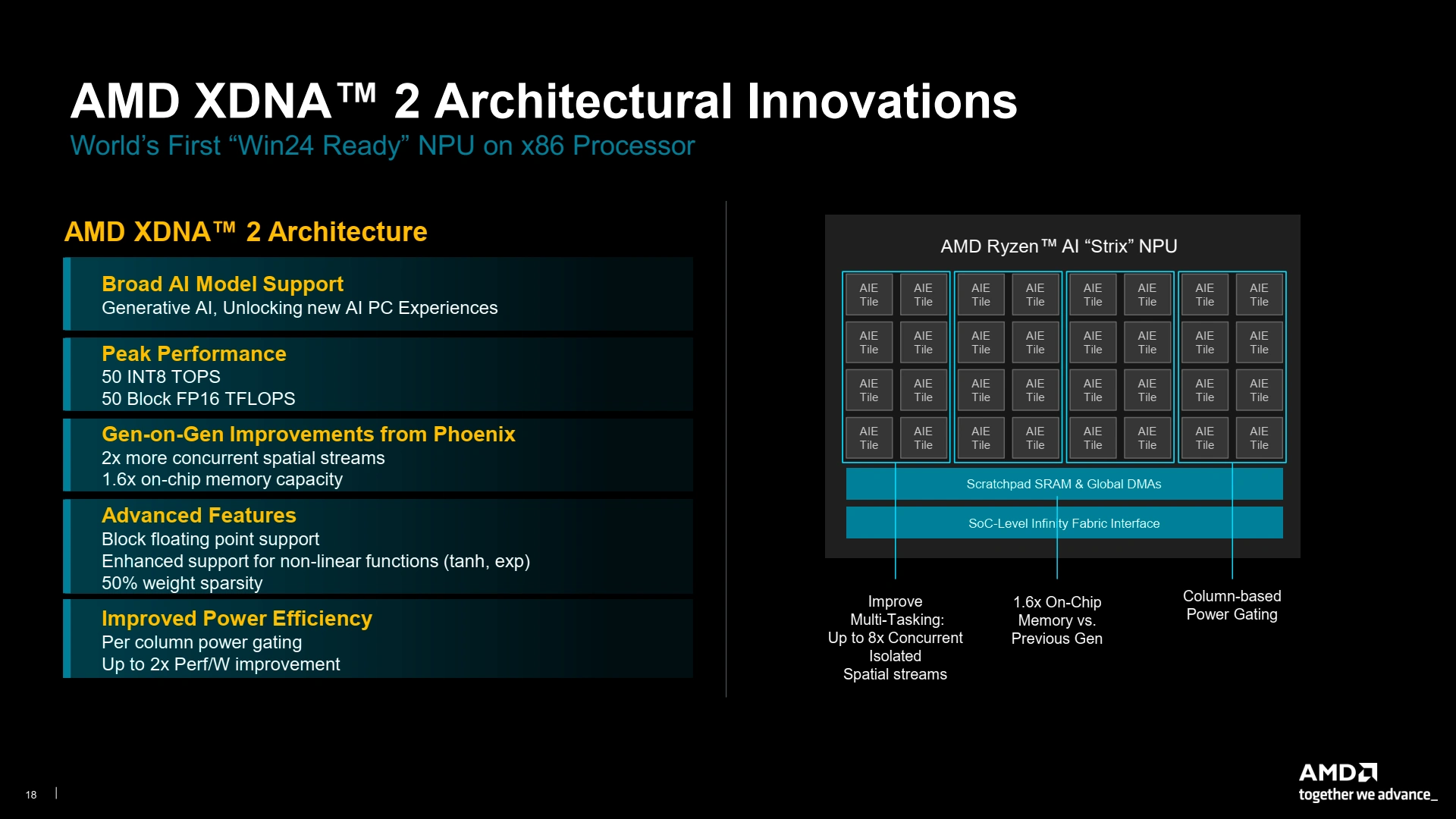
Toujours sur Strix Point, la seconde amélioration autre que le CPU réside dans son accélérateur de machine learning : XDNA 2. Pour être le premier sur la course aux TOPS avec 50 TOPS Int8 (et 50 en Block FP16 !), la firme a tout simplement… gonflé la taille de sa puce. Deux fois plus de spatial streams offrant la possibilité de faire tourner 8 tâches différentes sur l’accélérateur en même temps, 1,6 fois plus de de mémoire on-chip, et un support de la sparsité dans la limite de 50 % de poids nuls (similairement à ce que propose NVIDIA) : voilà la recette du succès ! Il ne suffit plus que de rajouter quelques petites améliorations ici et là, comme le support élargi des fonctions d’activation (tanh et exponentielles pour ne pas citer les nouvelles venues), et la possibilité de désactiver l’alimentation de colonnes de tuiles afin d’économiser l’énergie.

C’en est tout pour ce (long) point micro-architectural : si, sur le papier, Zen 5 semble fort appétissant, il va encore falloir attendre la fin du mois pour les tests du bousin en bonne et due forme !




J'ai du mal a comprendre un truc
Amd a 2 version des core ? Une avec fpu 512 et une avec fpu 256 ?
Zen 5c c'est toujours 256 bits ou ça peut changer ?
Strix point est full 256 bits si j'ai bien compris ?
Sur pc du bureau 512 bits ?
Les versions 256bits sont pour les versions mobiles (strix point). Un compromis conso/perf/surface jugé plus pertinent sur ce segment. La pleine puissance vectorielle a été privilégié pour les machines de bureau et serveurs de calcul. Zen5 et Zen5c en 512 pour les deux. C'est le même layout logic.
Il se dit que Strix Halo pourrait avoir droit à un CCD spécifique. Peut-être lui gravé en N3, mais avec 8 gros Zen 5. Éventuellement castré en 256b? Ca pourrait être une hypothèse.
Il y a deux interview intéressantes de Mike Clark, le papa des Zen, chez Tom's et Chips&Cheese (pas fini de tout lire, et pas encore commencé cette actu de Nico 😜)
Tu as vu ça ou zen 5c serveur 512 bits ?
Strix halo aira normalement les même die que les pc de bureau
Chez Tom's US.
Juste des spéculations, dans les commentaires de Tom's, qui me paraissent pertinentes. Clark à l'air de mettre beaucoup le boulot sur le N3 en avant, tout autant que le 4. Beaucoup plus que si c'était juste pour la version compact. On verra bien quant ça sortira.
Tu as du te tromper de source, sur Tom's US ils ne causent pas de 256-bit / 512-bit vectoriel (ou pas encore !). Mais je plussoie tes suppositions, même si AMD n'a pas été très clair. Pour moi :
Ok, j'aurai dû mettre les liens
https://www.tomshardware.com/pc-components/cpus/an-interview-with-mike-clark-the-father-of-zen-zen-daddy-talks-fast-3nm-launch-zen-5c-cores-for-desktop-chips
https://chipsandcheese.com/2024/07/15/a-video-interview-with-mike-clark-chief-architect-of-zen-at-amd/
Ahhhh merci, j'étais passé à côté de celle-ci :)
xeon vraiment ? tu me déçois 😒😅
Oups oups oups 😇😇😇 c'est corrigé ! Trop d'Intel en moi 😅 !
Je crois que si, slide 19:
On peut aussi imaginer des CCD N3 big cores exclusivement pour les serveurs (Epyc), et le deskop restant en 4.
Je me souviens de rumeurs, peu après la sorties des 7000, évoquant la futur fournée de Zen 5. Il était question de craintes de la part d'AMD concernant les rendements ou de possibles retards du N3 de TSMC, alors encore tout juste en phase de finalisation, ou peut être de difficulté à livré, avec des gros Apple et Intel passant possiblement devant.
C'était à partir de cette période qu'on a commencé à entendre parler de N4 pour Zen 5, alors que jusque là, tous le monde s'accordait à dire qu'il serait en 3.
A mon avis, pour éviter de se prendre un possible mur, AMD n'a pas voulu mettre tout ses œufs dans le même panier, et à du coup développé Zen 5 pour ces deux nodes, pour pouvoir réagir en cas de problème. Et comme au final, les deux nodes fonctionnent, et sont tout les deux livrables, ils vont peut-être répartir leur CCD suivant les marchés, coûts de revient et capacité de production de tsmc: AM5 / SP5 / Halo.
Ou bien alors ça sera du classique: N4 pour les Zen 5 et N3 pour les Zen 5c et mobiles.
je pense que amd va attendre le 3 nm pour sortir des zen 5c avec avx 512 sans le 3 nm ça serait trop grand
ça serait bien un 8 zen 5 + un second die 16 zen 5c en pc de bureau
Pourquoi tu tiens tellement a avoir la même politique que chez Intel.Travailles tu pour Intel, on dirait bien?Au vu des gros déboires des séries Intel 13 et 14 avec ses configurations 8 P+16 E, au contraire j'espère vraiment qu'il y en aura jamais en haut de gamme chez AMD, je suis très loin d'être le seul.Alors non merci.Amd surtout ne copiez pas Intel dans ses dérives.Même Apple ne le fait pas sur sa gamme pc avec arm qui sont pourtant une référence arm, dans la gamme processeur pc, y a toujours beaucoup plus de core puissant que de core faible sur leur processeur, cela devrait finir de te convaincre et de les convaincre de ne surtout pas faire comme Intel donc cela surtout en haut de gamme...dans l'avenir.
Tu n'as pas suivie le truc
Amd c'est la même architecture les core sont "juste" compacté donc pas de problème comme intel
Rien à voir. Le modèle 8+16 existe chez Intel depuis la série 12, et n'a strictement rien à voir avec les problèmes rencontré sur Raptor Lake.
Par ailleurs, leur 24c/32t leur donnait bel et bien un bel avantage face à AMD. Un vrai cœur, même petit et monothread vaut toujours bien mieux qu'un cœur logique.
Ils en parlent, chez Tom's. Le mode 8+16 est bien à l'étude, mais probablement pas avant Zen 6 (quoique, ils restent très vague, alors il est peut-être toujours possible d’espérer pour un refresh pour meubler en attendant? Perso j'ai hâte). Parce qu'en l'état des choses, ils leur aient impossible de passer au-delà de 16 gros cœurs du fait des contraintes de limites du TDP d'AM5.
Et Zen 5 et Zen 5c sont les même cœurs. Ce n'est pas une architecture hétérogène à proprement parlé (même leur AVX, est soit 256 soit 512 partout, justement pour garder cet cohérence logique partout). Ce n'est qu'une histoire de fréquence de fonctionnement. Leur objectif est de trouver un équilibre au niveau du proc. Etant donné que plus il y a de cœurs en fonctionnement, plus les fréquences sont obligé de baisser pour rester dans les limites du TDP, l'idée serait de trouver le bon point d'équilibre où à N thread donnés, les cœurs compact se mettraient en route, à une fréquence qu'ils leur seraient possible d'atteindre, qui serait la même que si des gros avaient été là mais auraient dû se limiter, pour ne pas exploser le TDP. Et ainsi, on ne remarquerait presque pas la différence entre un 8+16 ou un 24. Et en mono tâche, leur thread placement trouvera tout seul quel est le cœurs le plus performant dans tout cet amas hétérogène, sans même à avoir de code spécifique dans l'os.