
Avec DeepSeek, la Chine a prouvé que du jus de cerveau bien employé pouvait passer outre une partie des restrictions techniques liées à la guerre commerciale américaine, au grand dam du pays de Trump. En effet, la prouesse d’entraîner un réseau capable de rivaliser — voire de surpasser — les ténors du genre est, en soit, impressionnante ; mais là n’est pas la seule étape dans la mise en production d’un nouvel algorithme d’IA : la firme doit désormais pouvoir le déployer sur un maximum d’appareils. Et, en raison de sa taille « restreinte » (671 milliards de paramètres, contre une estimation à un peu moins de 2 billions pour ChatGPT 4) et de sa décomposition en six sous-modèles de taille plus raisonnable (de 1,5 à 70 milliards de paramètres), son utilisation est possible sur des cartes graphiques grand public… voire des iGPU, à condition d’optimiser correctement la chose.
Ni une, ni deux, AMD et NVIDIA se sont retrouvés dans le même bateau à chercher à faire mouliner des modèles open-source préexiatants, ré-entrainees à partir du dernier modèle en date, DeepSeek-R1 (lancé le 20 janvier dernier), sur leur matériel respectif. Neuf jours plus tard, les rouges ouvraient le bal avec un post sur leur blog expliquant la marche à suivre pour les cartes Radeon ainsi que les Ryzen AI de la firme, le tout en passant par le logiciel LMStudio. Selon le GPU et la VRAM/RAM (dans le cas des iGPU), vous serez limités au niveau la taille du sous-modèle : le plus gros, DeepSeek-R1-Distill-Llama-70B, requiert par exemple pas moins de 64 Gio de RAM ! Fort heureusement, des modèles plus petits comme le DeepSeek-R1-Distill-Llama-8B sont compatibles dès la RX 7600 : de quoi vous permettre de tester le bousin par lui-même.
AMD illustre même la chose en vidéo
Chez NVIDIA, la réponse est arrivée le surlendemain, cette fois-ci en s’axant sur la rapidité des cartes. Sans surprise, l’inférence met à contribution les Tensors Cores, montrant ainsi leur suprématie technique sur la RTX 4090 et 5090 par rapport à RDNA 3. Une comparaison certes biaisée, puisque les rouges n’ont pas encore dévoilé leur propre nouvelle génération — qui se murmure être bien plus performante à ce niveau —, mais qui demeure de bonne guerre puisque, à l’heure actuelle, seule CDNA et les Radeon MI professionnelles sont capables de rivaliser… quand l’écosystème logiciel le permet. Dans notre cas, NVIDIA annonce une compatibilité avec Llama.cpp, Ollama, LMStudio, AnythingLLM, Jan.AI, OpenWebUI ainsi que Unsloth pour raffiner le modèle sur des données déjà en votre possession.

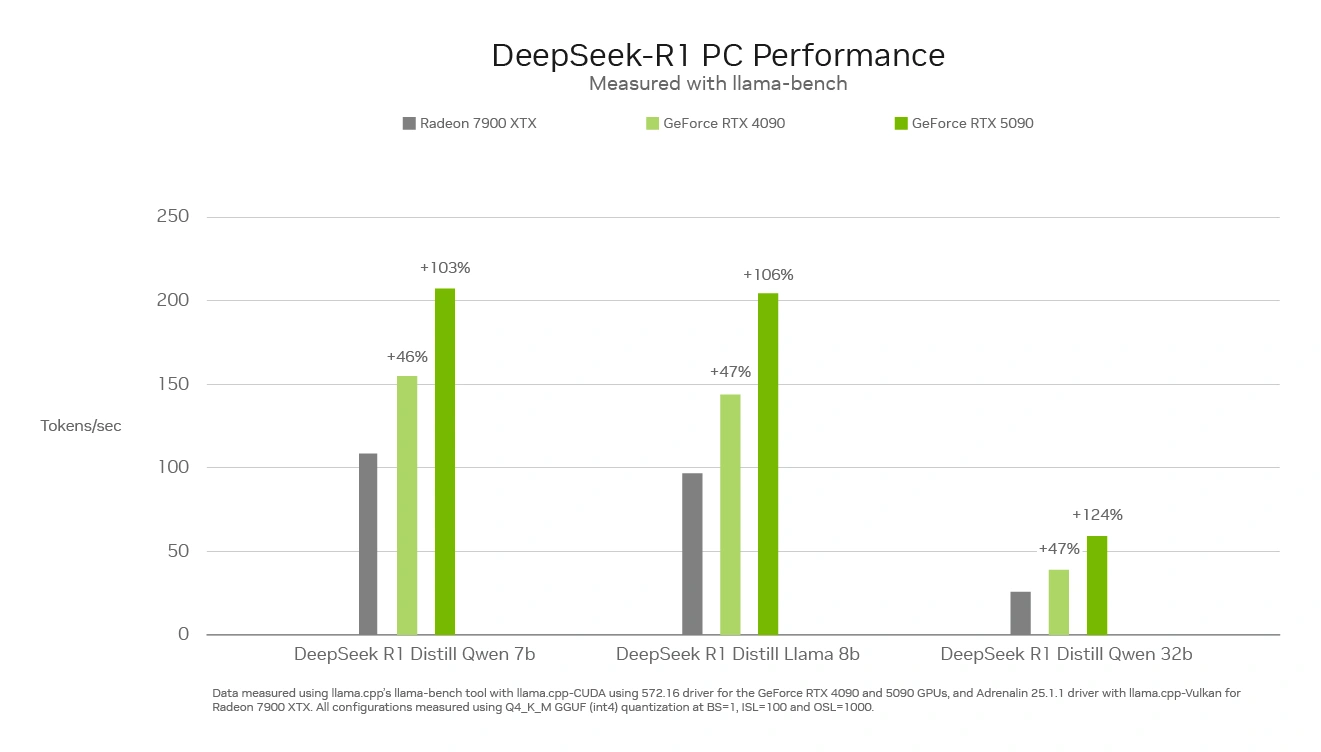
NVIDIA est plutôt dans les graphiques pour montrer la supériorité de sa solution
Sans surprise, les mesures du caméléon placent les cartes vertes en pole position avec un facteur 2 en performance entre la RX 7900 XTX et la RTX 5090, en partie grâce à une restriction agressive de la précision en se basant sur des entiers 4-bit.
La bataille est lancée, et le modèle encore très jeune : aucun de ces nombres n’est donc encore définitif… et le débit proposé, de l’ordre de la centaine de tokens par seconde pour le modèle le plus rapide, permet déjà de tester confortablement la chose chez soi. Niveau confidentialité, nous apprécions ! À voir comment la chose évolue, ainsi que les intégrations possibles dans des logiciels existants.




Attention, les modèles cités (de 1.5 à 70 milliards de paramètres) n'ont rien à voir avec le modèle original. Ce sont d'autre modèles (Llama celui de méta et qwen celui d'alibaba) ré-entrainés avec les sortie de deepseek R1.
Les seules versions "light" de deepseek sont celles ci à ma connaissance : https://unsloth.ai/blog/deepseekr1-dynamic
Bien sûr avec un impact plus ou moins important sur les résultats.
DeepSeek marche tres bien avec KoboldCpp 1.79.1 :
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-70B-GGUF/tree/main
J'ai utilise "DeepSeek-R1-Distill-Llama-70B-Q5_K_M.gguf"
Quand je lui pose une question il me repond en 3 minutes et demie environ, c'est deux fois plus rapide que Megadolphin-120B par exemple
Ces modèles disponibles en local c'est un plus côté confidentialité et pollution (les data centers ne sont pas specialement ecolo), tu as obtenu ce résultat avec quel matériel ?
CPU: Ryzen 7 5800X
RAM: 128 Go DDR4 (4 barrettes)
GPU: RTX 3080 12Go
J'attends avec impatience la RTX 5080 24Go pour acceler les calculs
Je suis d'accord pour le côté confidentiel, mais pour le côté écolo, cela se discute. Je ne parle pas de l'entrainement de ces modèles toujours plus gourmand, mais pour l'exécution. Entre des centaines de PC pas optimiser tournant chez des particuliers et une datacenter ultra-optimisé pour consommer le moins possible, dans l'absolu, je ne suis pas sûr que le datacenter s'en sorte moins bien.
Le datacenter est optimisé côté matériel, mais refroidir tout ce petit monde ça n'est pas rien. Avoir les modèles complets à la maison, ça n'est pas possible, donc il est difficile de comparer modèle local et modèle sur serveur. D'un autre côté, j'utilise un modèle Mistral 13B sur LMStudio et sans être parfait, il fait le taf en consommant assez peu.
Les dernières informations que j'ai eu sur l'impact des IA, c'était que 10 questions par jour sur ChatGPT 4o par une personne sur une année, c'est équivalent à une tonne de CO². J'ai de la marge avec la conso de mon PC perso.
Sur quelle période ? Une année ? Car pour seulement 10 questions, cela me paraît beaucoup.
Oui, sur une année pardon ^^
ChatGPT était déjà à 8,4 tonnes de CO² par an sous GPT 3 et 4 et 4o ont multiplié ses capacités, mais aussi sa consommation et utilisation d'eau. Pour les version 4+ ce sont des extrapolations (OpenAI manie très bien la langue de bois à ce sujet), mais sur GPT 3 tu peux trouver informations et prévisions sur cette étude.
Juste pour dire, la tonne de CO2 n'est pas une unité d'énergie (mais c'est une des réussites du GIEC).
Je me doutais bien ^^ Merci pour les précisions 👌
Je ne crois pas qu'il soit question d'unité d'énergie mais d'indicateur. Alors cela ne parle sûrement pas à grand monde, une tonne de CO2 dans l'air... mais 10 questions par jour sur un an ça ne fait que 3650 questions à ChatGPT et on comprend bien que cela pollue excessivement.
Même comme indicateur, c'est farfelu et catastrophiste. Un datacenter consommerait de l'énergie nucléaire, dont l'uranium a été extrait et enrichi par des machines électriques chargées à l'énergie nucléaire, qu'on parlerait encore en tonnes de CO2. Je n'entrerai même pas dans la théorie du CO2, ce n'est pas de la science mais une religion.
Pour revenir un peu dans le sujet, le marché est en train de migrer vers des accélérateurs spécialisés, ceux de Cerebras par exemple, ce qui améliore sensiblement l'efficacité. A domicile, ce serait intéressant de voir la performance des NPU intégrés aux derniers SoC Intel, AMD voire même Qualcomm pour accélérer Llama, Qwen, Granite et compagnie.
Attention aux termes employés. Un trillion en français est égal à 10 puissance 18. Alors qu'en anglais, un trillion c'est 10 puissance 12 (billion en français).
Merci, j'ai corrigé !