Si AMD a fait évoluer l’agencement interne de ses cœurs entre générations — la fameuse microarchitecture qui nous passionne tant —, une technologie est restée identique depuis Zen 2 : celle de l’interconnect reliant les CCD (dies de calcul) au CIOD (die gérant les entrées/sorties, principalement PCIe et RAM). En effet, pour limiter les coûts, les rouges ont opté pour un routage en utilisant directement les couches du PCB (on parle alors de substrat), identique à la technologie employée pour relier le silicium du die aux contacts de la puce. À l’opposé, Intel et ses designs en tuiles reposent sur une technologie à base de silicium intégré préalablement dans le substrat nommée EMIB, ce qui offre une densité et une efficacité énergétique meilleure au détriment du coût de fabrication.

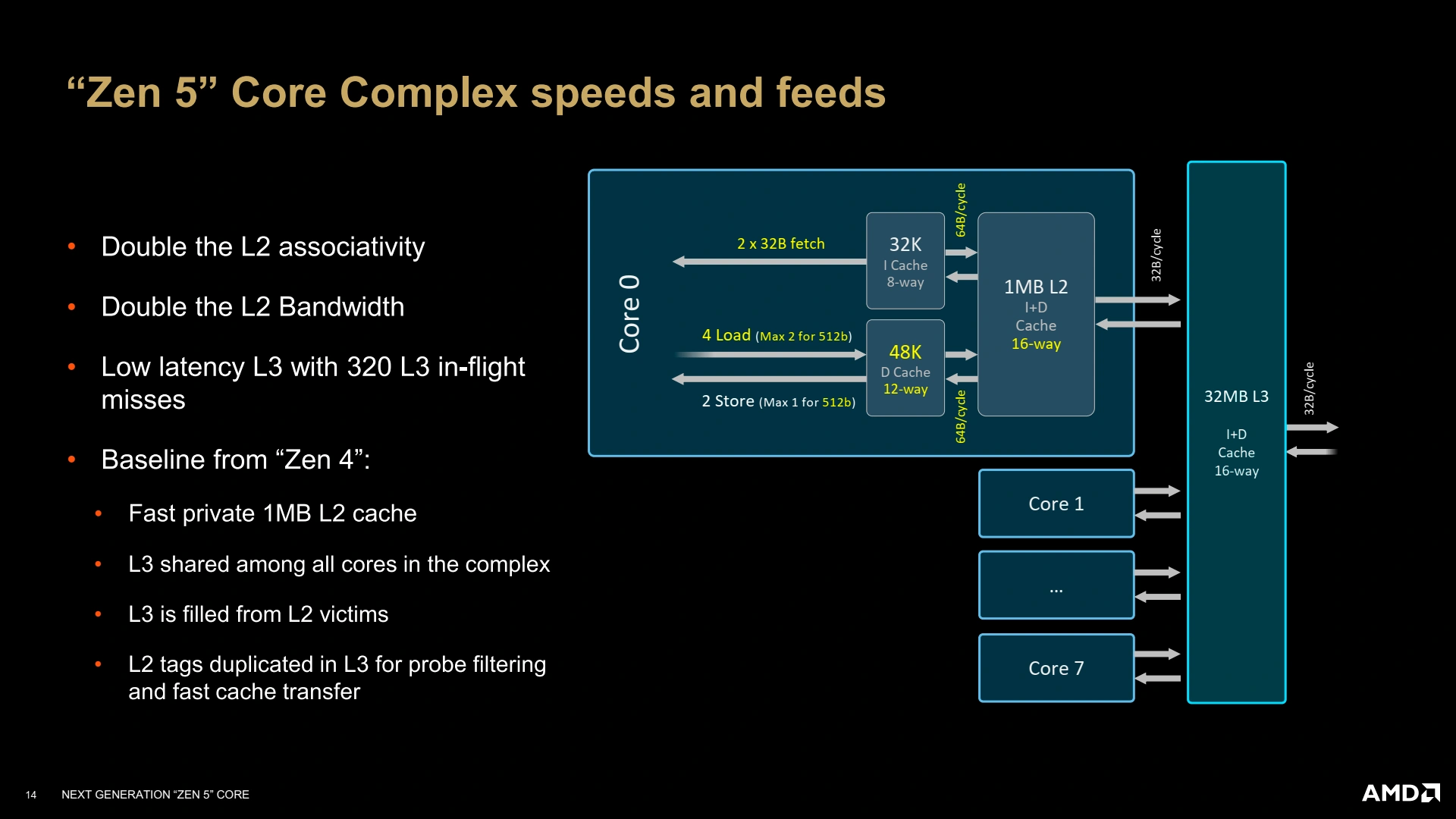
Notez la flèche double de droite, sortant du L3 (32 B/cycle) : voilà notre interconnect !
Or, avec la progression des performances monocœur, ce lien devient castrateur en particulier du fait d’un bus encore et toujours limité à 32 octets par cycle en lecture et 16 octets par cycle en écriture entre CCD et CIOD. Pour y remédier, un cache plus gros est d’une bonne aide… comme par hasard, les X3D offrent justement des gains impressionnants ! Pour Zen 6, le bruit court depuis quelques mois déjà d’un changement de cet interconnect die-to-die (d2d), sans pour autant trop s’étendre du côté des détails techniques. Voilà qu’un examen attentif de Strix Halo nous offre des éléments de réponse, que l’on imagine repris sur Zen 6 (le contraire serait en tout cas fortement étonnant puisque les coûts de développement engagés ne seraient pas amortis).


Routage de Zen 3 : entre pins et liaisons inter-dies il n’y a plus beaucoup de place ! Notre connexion série est au milieu, en blanc.
En effet, bien que Strix Halo repose sur un mix Zen 5/RDNA 3.5 — deux architectures CPU/GPU déjà connues — la mise en relation de ces deux compères s’avère être inédite. Depuis Zen 2, l’implémentation physique de l’interconnect passe par un SerDes, pour Sérialiseur/DéSérialiseur, un duo permettant de faire passer un maximum d’informations initialement encodées en parallèle (par exemple, un fil par bit) par un nombre restreint de signaux de plus grande fréquence représentant les données en série (par exemple, un fil pour tous les bits), d’où son nom.

« Boh, c’est simple, tu as juste à mettre un SerDes, et c’est bon ! » —Un fameux chercheur en hardware breton.
L’avantage du système est de réduire le nombre de fils, ce qui est bien pratique pour notre substrat peu propice aux intégrations denses, mais cela n’est pas sans inconvénient ; d’une part sur la latence — la donnée devant passer par le SerDes avant et après la transmission — ; et la fréquence démultipliée du signal série est plus demandeuse en énergie et en contraintes de routage, en dépit du nombre réduit de contacts. Avec son énorme bus mémoire de 256 bits, Strix Halo était ainsi un terrain d’expérimentation de choix pour cette nouvelle implémentation, basée sur une mer de fils (sea of wire), comprenez une explosion du nombre de connexions du fait de l’abandon de la sérialisation.

L’InFO-oS par TSMC : la RDL (jaune) au milieu permet des interconnexions (vertes) haute densité entre les dies (gris).
Pour cela, l’utilisation du substrat seul n’est plus suffisante, et AMD a ainsi recourt à une couche de redistribution (RDL) plus dense, permise par le procédé InFO-oS (Integrated Fan-Out on Substrate) de TSMC. Dans le détail, cette couche de redistribution est similaire à un interposer (morceau de silicium dédié à l’interconnect) tout en étant bien moins chère, car la couche métallique faisant passer le signal est déposée sur un composé organique et non du silicium. De quoi conserver un positionnement agressif en manière de tarifs, bien que la RDL (en particulier dans les cas complexes nécessitant le recours à plusieurs couches) se retrouve plus coûteuse que le combo SerDes/substrat précédent. Au passage, Intel a également cet assemblage sur son plan de route de sa division fonderies avec Foveros-R, prévu pour 2027, autant dire que la chose attise les regards des deux côtés de la Force. Rendez-vous sur Zen 6 pour voir comment tout ce beau monde s’orchestre en pratique ! (Source : Wccftech)
Tout cela est merveilleusement expliqué dans le travail de High Yield, que nous vous encourageons à regarder (préparez les sous-titres !)



Si c'est si bien que ça la parallélisation, pourquoi a-t-on abandonné le PATA/IDE au profit du SATA?
Et du coup, c'est mieux ou moins bien que l'EMIB d'Intel?
C'est ni mieux ni moins bien, ça offre un coût et des possibilité différentes. Sur un câble, le meilleur compromis c'est de sérialiser et blinder les câbles pour éviter les interferences :) mais je ne suis pas expert dans ce domaine !
Par rapport à l'EMIB, ça va dépendre de la version de l'EMIB mais comme chez Intel c'est de base du silicium, je dirais l'avantage côté perf est à Intel, au détriment du coût. Après on a pas les données techniques donc c'est du doigt mouillé !
Je peux ajouter ce qu'il te manque pour ta réponse si tu veux pour la parallélisation 🤣
Dans le cas des connexions type IDE, cela donne des coûts de conception atroce, lié à des besoins comme avoir strictement aucun problème de transmission dans l'ensemble des fils ou un cout en cuivre bien plus élevé. D'un autre côté, augmenter la fréquence n'est pas si problématique et permet via certaines méthodes de transmettre bien plus sur un seul fil (modulation des signaux, plusieurs symboles/bits par coup d'horloge).
Par contre, sur un die ou des circuits imprimés, c'est tout l'inverse, les pistes étant courtes, on va paralléliser le plus que possible, mais cela ne veut pas dire que la conception est simple, de nombreuses règles de design sont à respecter pour que ça fonctionne (ça se voit sur les photo ci-dessus, les pistes ne sont pas random et souvent groupées).
C'est une excellente nouvelle car en plus de réduire la latence ça va permettre d'augmenter les débits
Il faudrait qu amd double son débit comme ça ils pourraient gérer la ddr5 8000 sans limitation
Quid de l'usage d'un composé organique plutôt que minéral sur la durée de vie (avec un petit parallèle aux écrans OLED) ?!
Rien avoir avec des pixel 😅
Je m'attendais à celle-là. Je dis, certes, bien que cela n'a rien à voir avec des pixels, les matériaux organiques sont potentiellement putrescibles. Est-ce que cela aura des conséquences même dans un CPU encapsulé ? Peut-on considérer cela comme étant plus ou moins "sous vide" ? Si oui, c'est déjà une bonne nouvelle.
Organique dans ce contexte se réfère à la chimie organique, c'est à dire au fait que c'est sur une base de chaîne carbonée, contrairement au métaux qui sont, ben, pas du carbone 😅. Certains composés vont mal vieillir, d'autres pas du tout ; et pour le moment on n'a pas besoin de se mettre sous vide pour limiter les effets, tous les composés sont inertes dans les conditions normales de température et de pression à ma connaissance.
Exactement, c'est de la chimie organique aliphatique ou aromatique et c'est bel et bien putrescible. Ce n'est en tout cas inerte. La kaolin (de la porcelaine) est chimiquement inerte par exemple. Je pense que c'est comme pour les écrans OLED, ils ne peuvent pas éviter la dégradation des molécules organiques, mais juste la ralentir (comme ils le font déjà).
Wikipedia a une longue page sur la question : https://en.m.wikipedia.org/wiki/Organic_semiconductor , je suppose que c'est suffisamment ralenti pour ne pas être perceptible à notre échelle, car les substrats organiques ne sont pas nouveaux et n'ont à ma connaissance jamais posé de souci de durée de vie (d'autant pkusbque le renouvellement du matériel précéde le plus souvent la panne).
c'est pour ça que j'attends encore mon 395 max ...